...
函数 | 描述 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | instr(str, substr) | 函数说明:返回从1开始的字符出现索引 示例:
| |||||||
| 2 | left(str, len) | 函数说明:返回第一个 n 字符 示例:
| |||||||
| 3 | locate, position | 函数说明:返回子字符串第一次出现的位置 示例:
| |||||||
| 4 | parse_url | 函数说明:提取URL的一部分 示例:
| |||||||
| 5 | repeat | 函数说明: 返回将给定字符串值重复n次的字符串。 示例:
| |||||||
| 6 | substring(str, pos[, len]) substr(str, pos[, len]) | 函数说明:返回str从pos开始、长度为len的子字符串,或字节数组从pos结束、长度为len的切片。 示例:
| |||||||
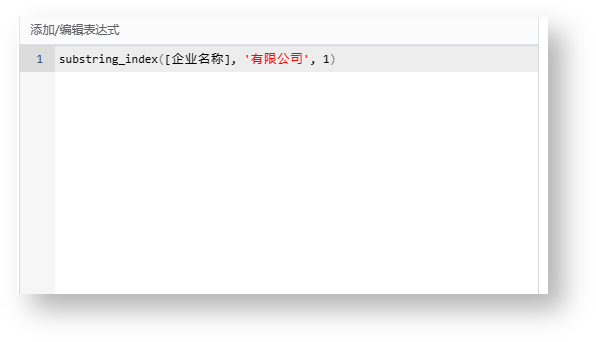
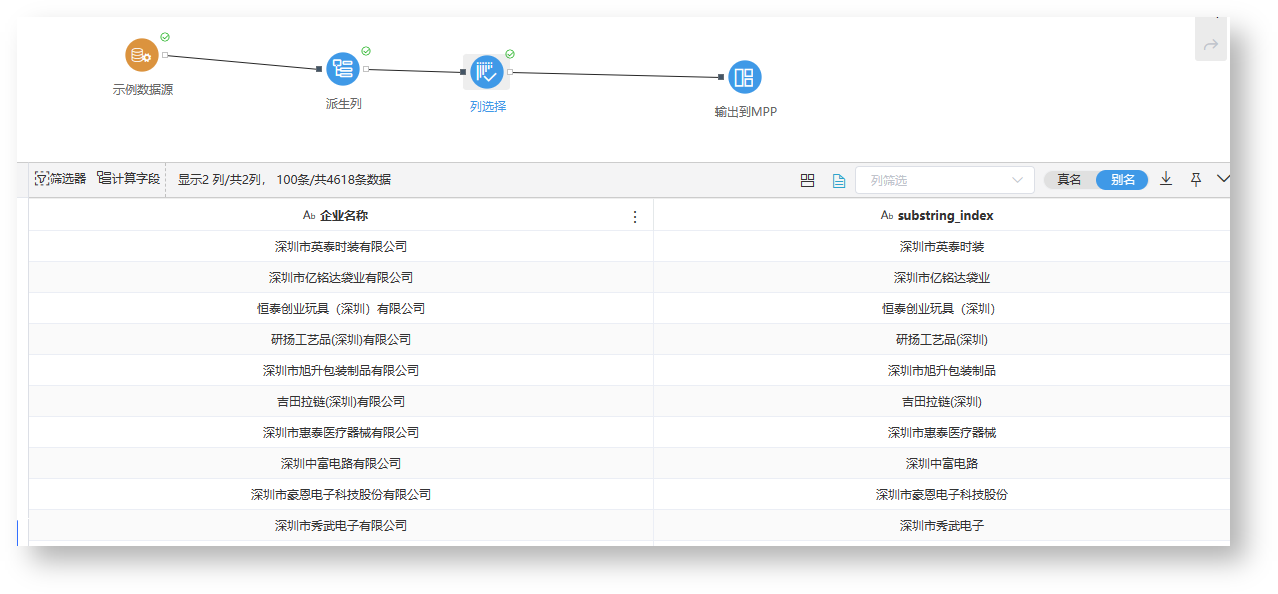
| 7 | substring_index | 函数说明:返回子字符串的索引。 示例:substring_index([企业名称], '有限公司', 1)
| |||||||
| 8 | split | 函数说明:拆分字符串 示例: |
...


