...
在新版本中,指标模型中的维度、指标、维表、事实表和数据模型,都可以作为独立的资源通过资源导入导出的方式进行资源迁移。

3.4 自助ETL
...
+ 新增数据接入和数据输出的类型
...
+合并行节点中新增集合运算功能
背景介绍
在合并行的场景中,会有集合操作的需求,具体来说,合并行有多种方式:交集、差集、并集和异或。通过不同的集合操作方式,可以满足多种合并需求场景。
功能简介
为了满足更多项目的场景,在新版本中,自助ETL支持更多的数据源和目标数据源类型。
- 新增支持的数据库:TiDB、PanWeiDB、YMatrix、阿里云MaxCompute、Elasticsearch、MongoDB;
- 新增API取数节点,用于读取API数据;
- 目标源连接星环数据库时,支持新建表到星环数据库中。

+ 合并行节点中新增集合运算功能
...
在合并行的场景中,需要通过不同的集合操作方式,满足多种合并需求场景。在新版本中合并行的集合操作配置提供四种操作:交集、差集、并集和异或。

...
...
^ 合并行优化选择列弹窗新增列匹配机制
...
为了使列匹配更加灵活和易用,新增自定义列匹配机制功能。列匹配提供以下方式:按别名自动匹配、按别名自动匹配、按位置自动匹配和手动配置字段。

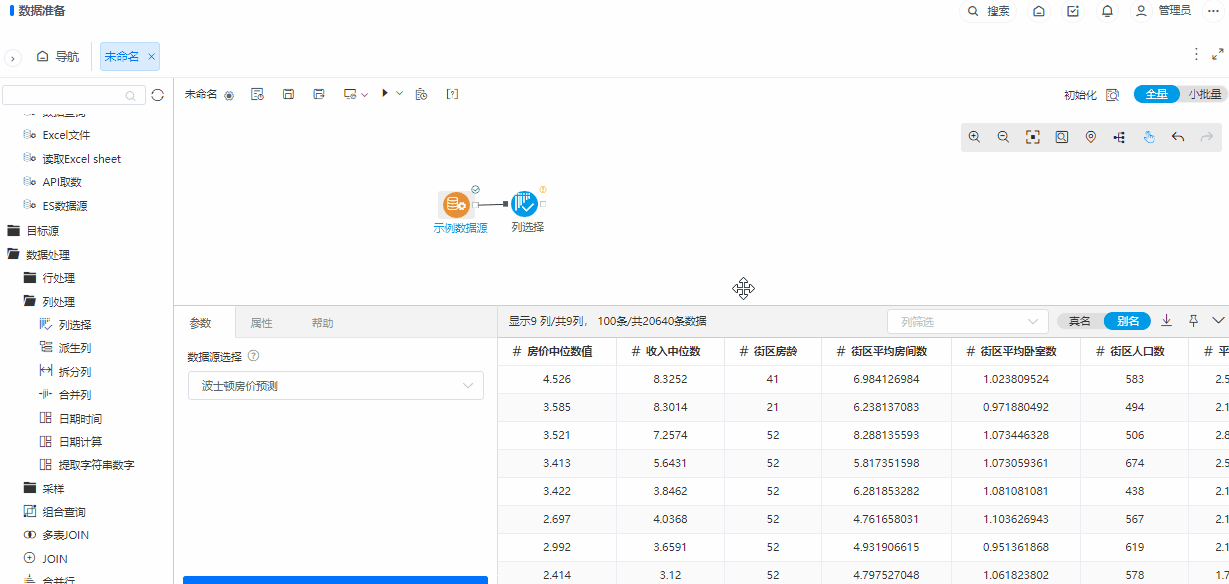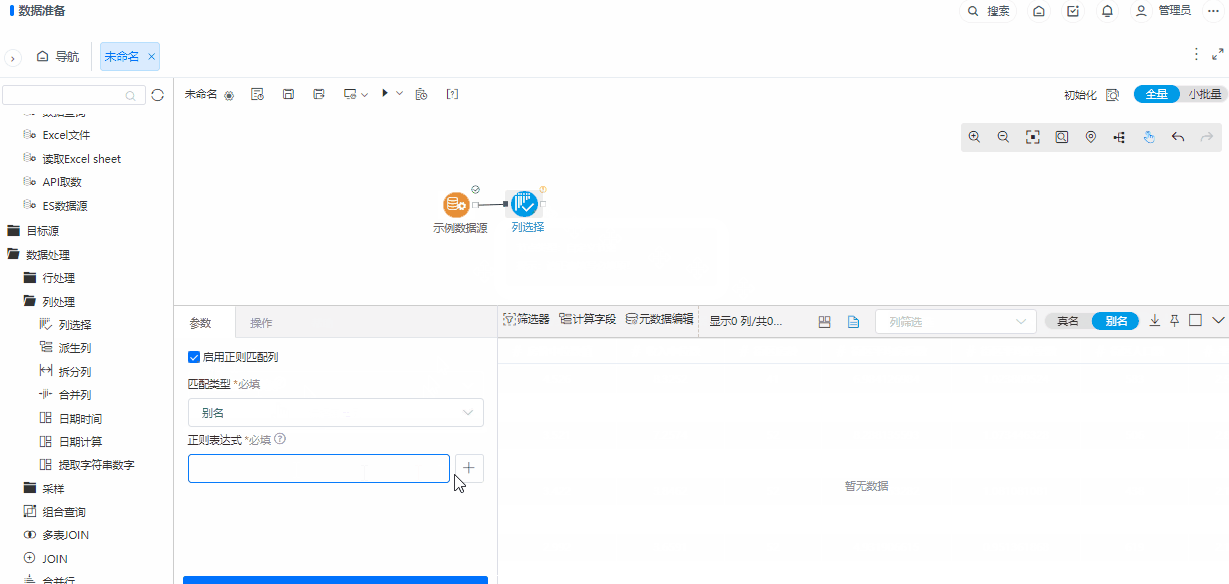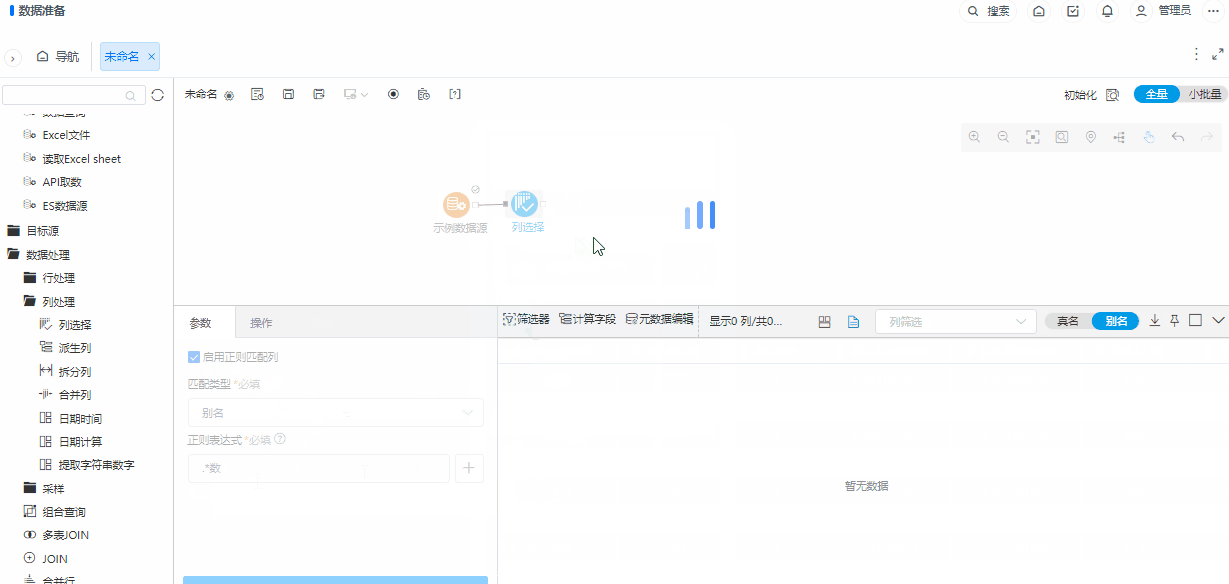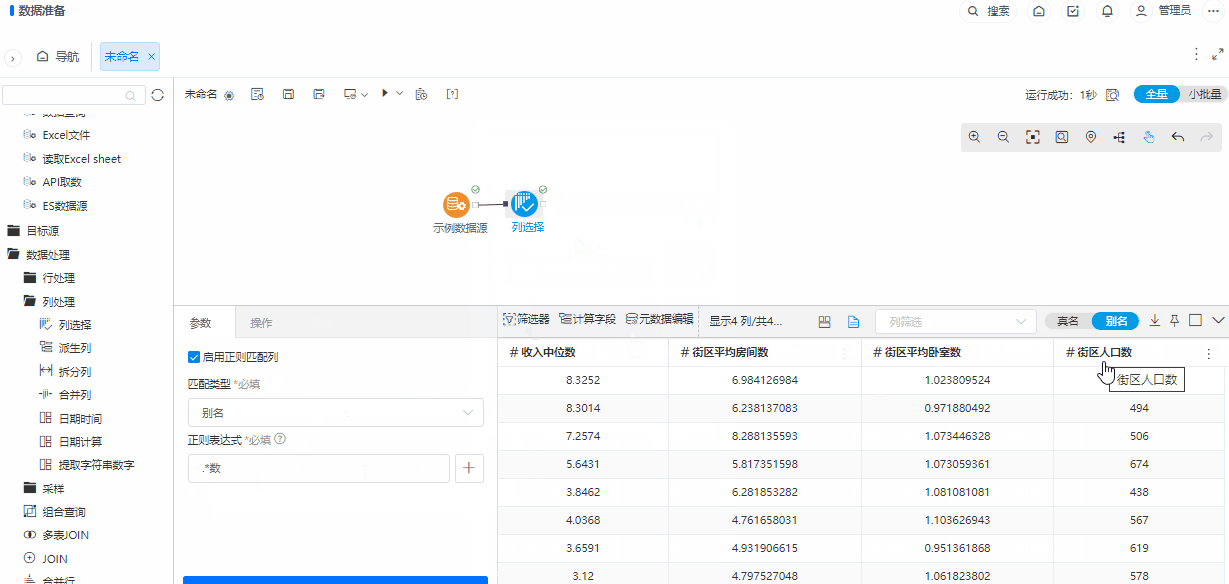
+ 列选择/转行节点新增正则匹配
背景介绍
在列数较多或者前节点输出列不固定的情况下,都可以使用规则匹配的方式进行列选择,使选择列方式更加灵活。
功能简介
默认不启用正则匹配列,启用正则匹配列后,可以进行名称正则匹配,也可以进行别名正则匹配。
...
+SQL函数列表增加EXCEL导入
背景介绍
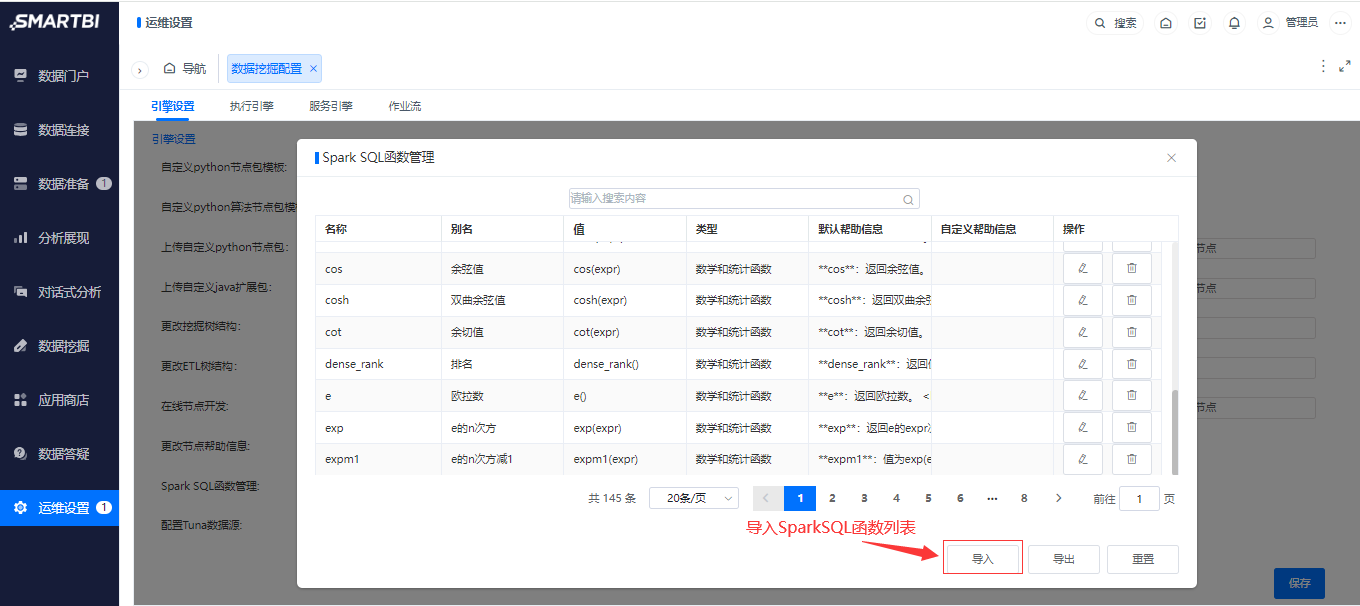
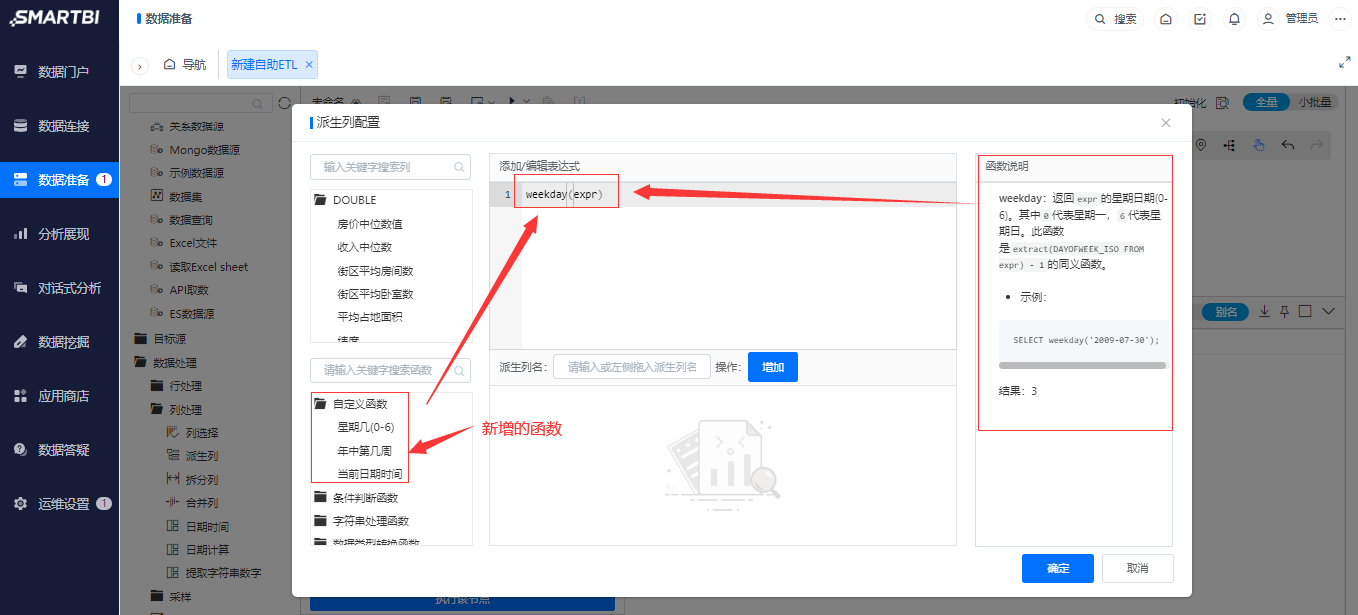
Spark SQL函数列表增加EXCEL导入功能,方便用户进行维护,如果需要进一步丰富内置Spark SQL函数,可以通过此方法补充更多Spark SQL函数。
功能简介
对Spark sql函数进行管理:导入、导出和重置,导入的EXCEL文件中可以自行添加补充Spark SQL函数。
...
+数据源支持elasticsearch
功能简介
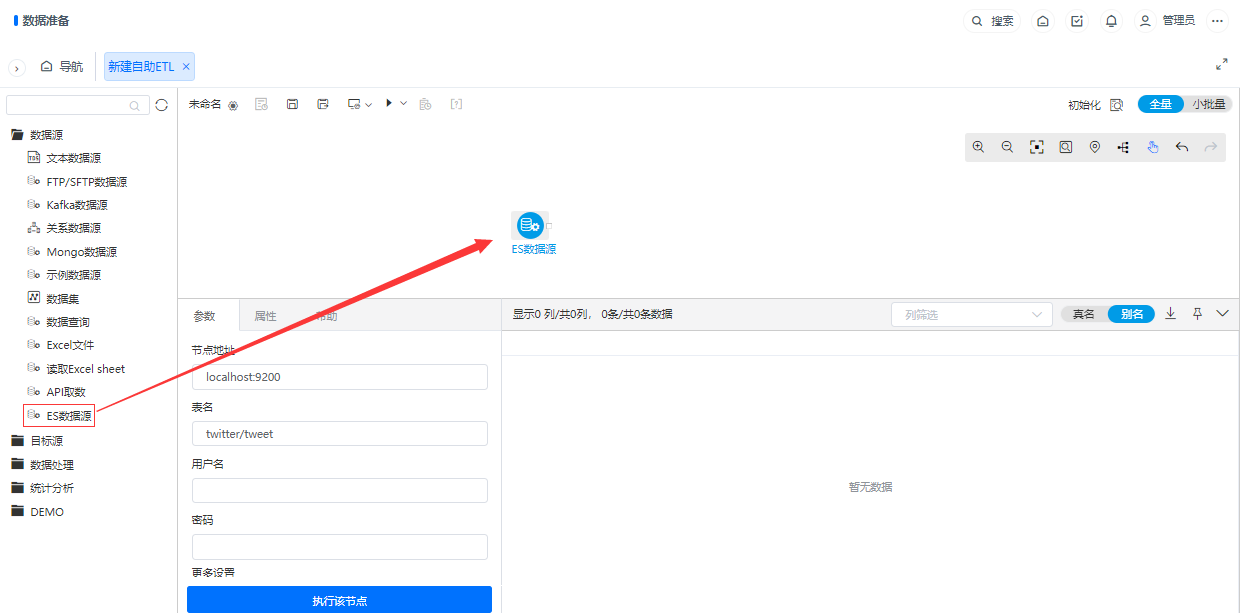
为了丰富ETL的数据源读取节点,新增了ES数据源,ES数据源节点用于读取elasticsearch数据源数据。
...
+数据源和目标源支持mongo 数据库
功能简介
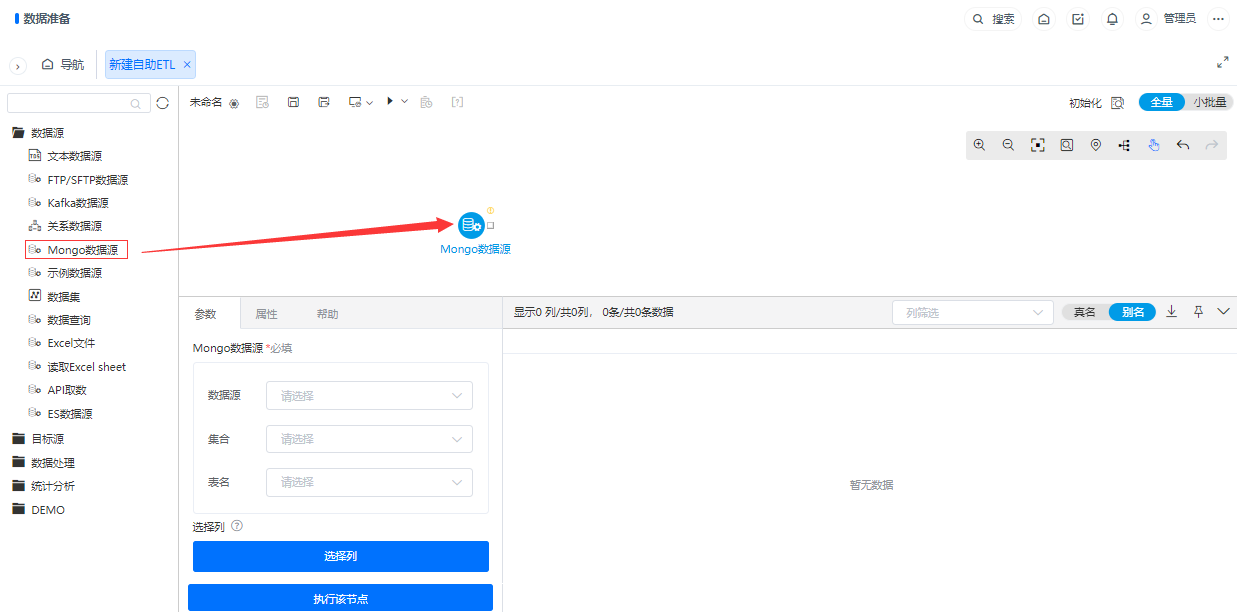
为了丰富ETL的数据源和目标源节点功能,新增了mongodb数据库,用于mongodb数据库数据库读取和写入操作。
...
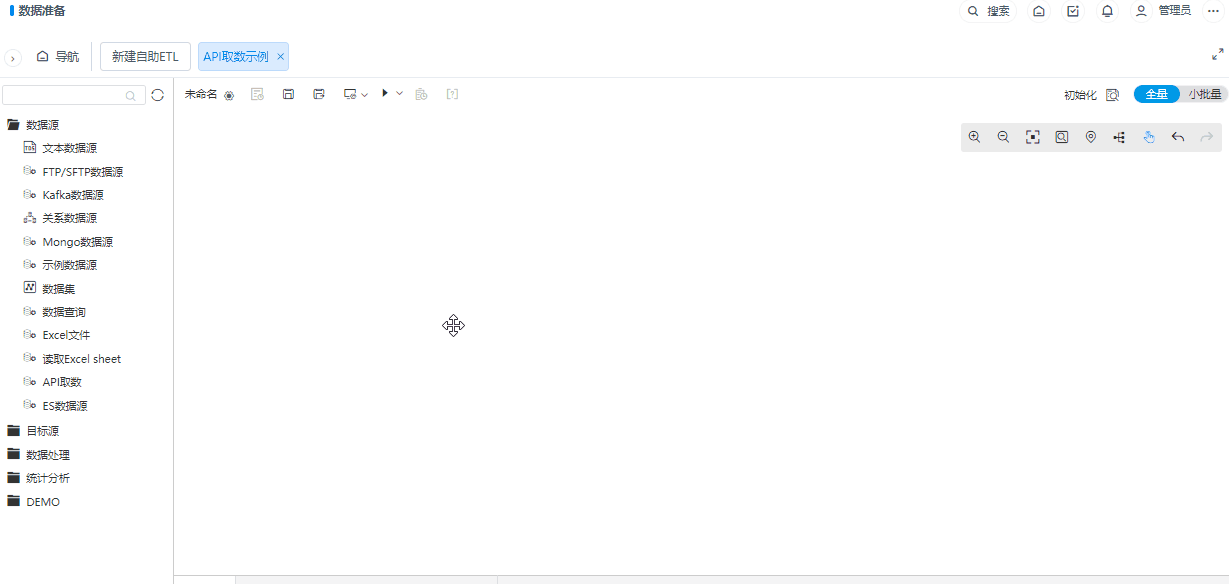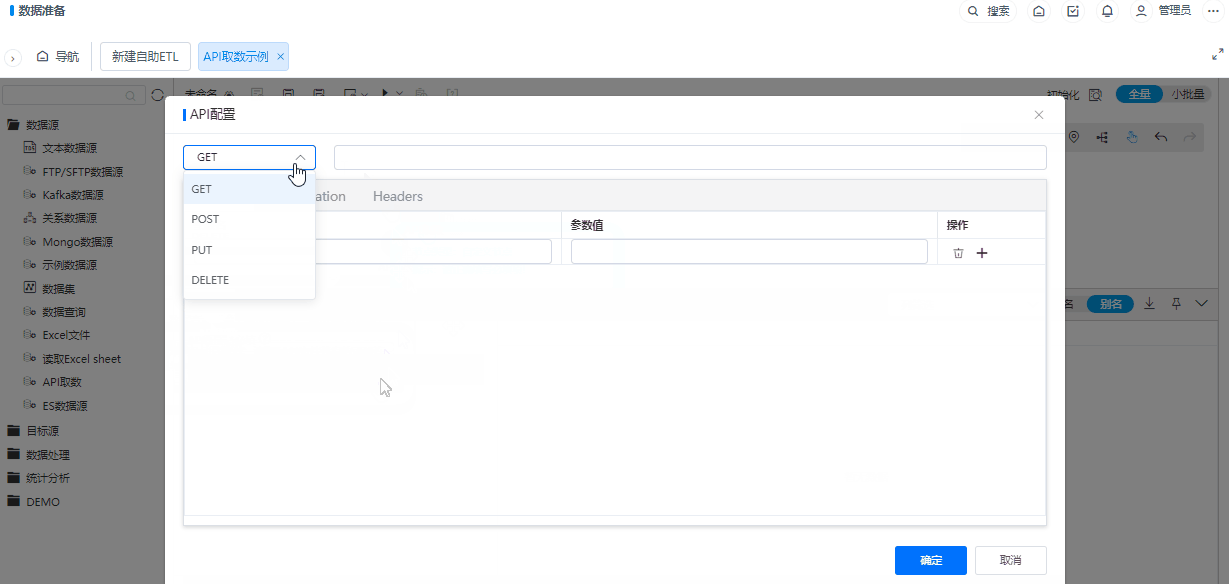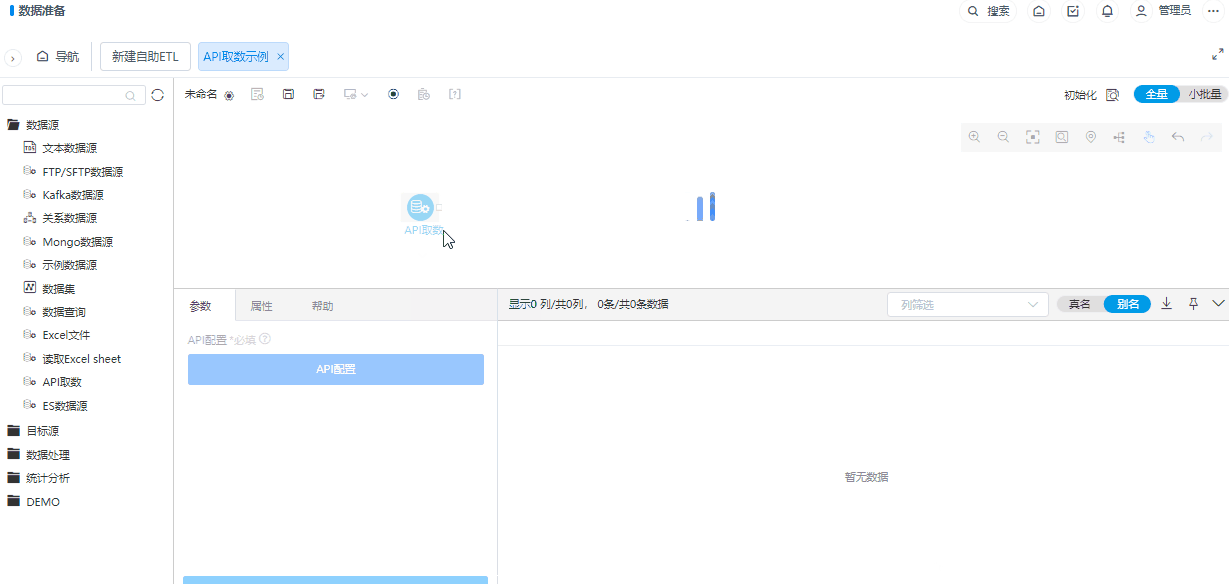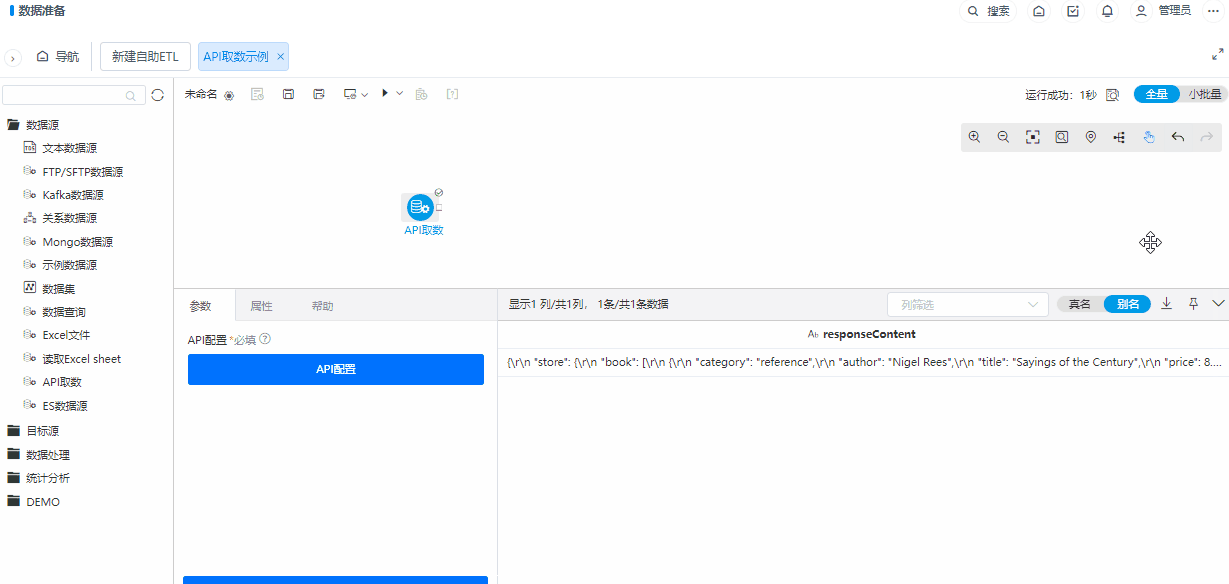
+数据源支持API取数
功能简介
为了丰富ETL的数据源读取节点,新增了API取数节点,用于读取API数据。
...
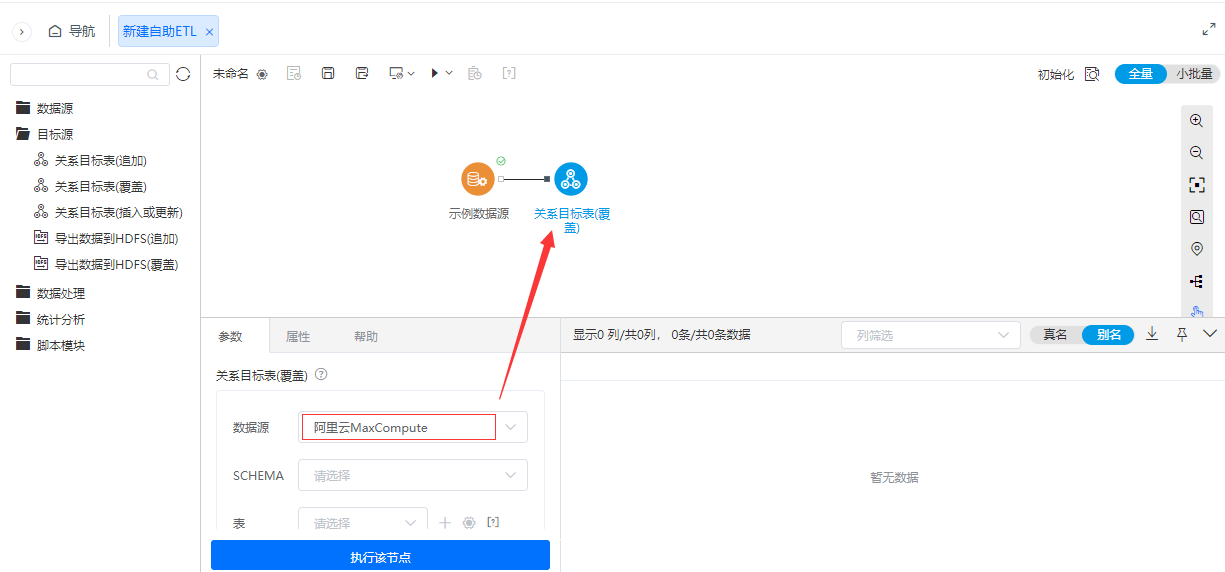
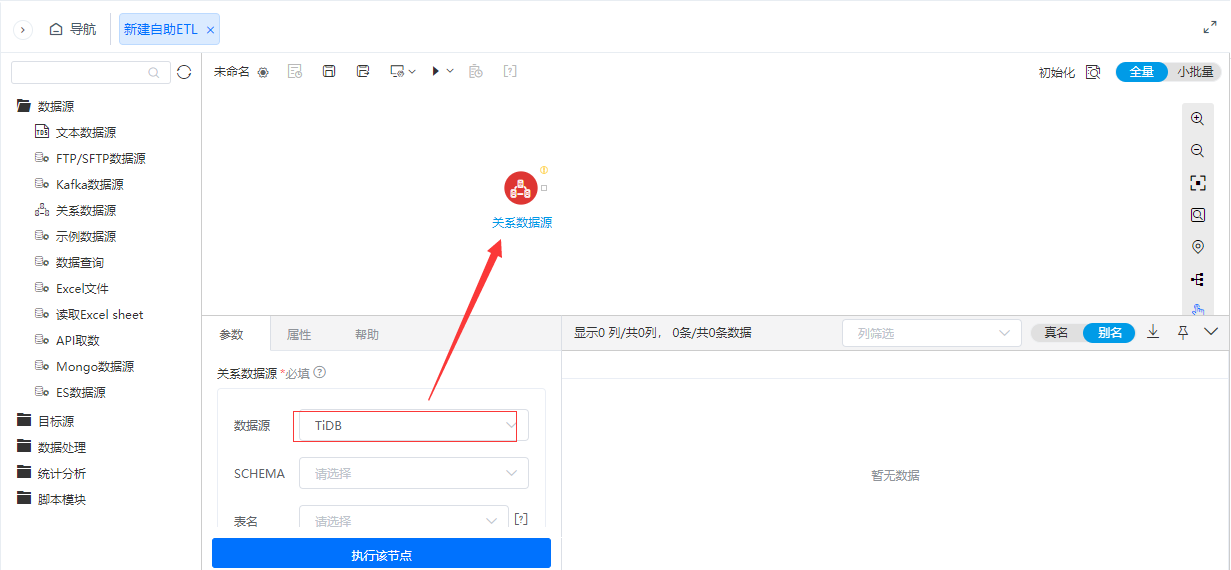
+目标源支持阿里云MaxCompute
功能简介
为了丰富ETL的目标源导出节点功能,新增了阿里云MaxCompute, 用于阿里云MaxCompute数据库导出操作。
...
...
+数据源和目标源支持PanWeiDB数据库
功能简介
为了丰富ETL的数据源和目标源节点功能,新增了PanWeiDB数据库,用于PanWeiDB数据库数据库读取和写入操作。

...
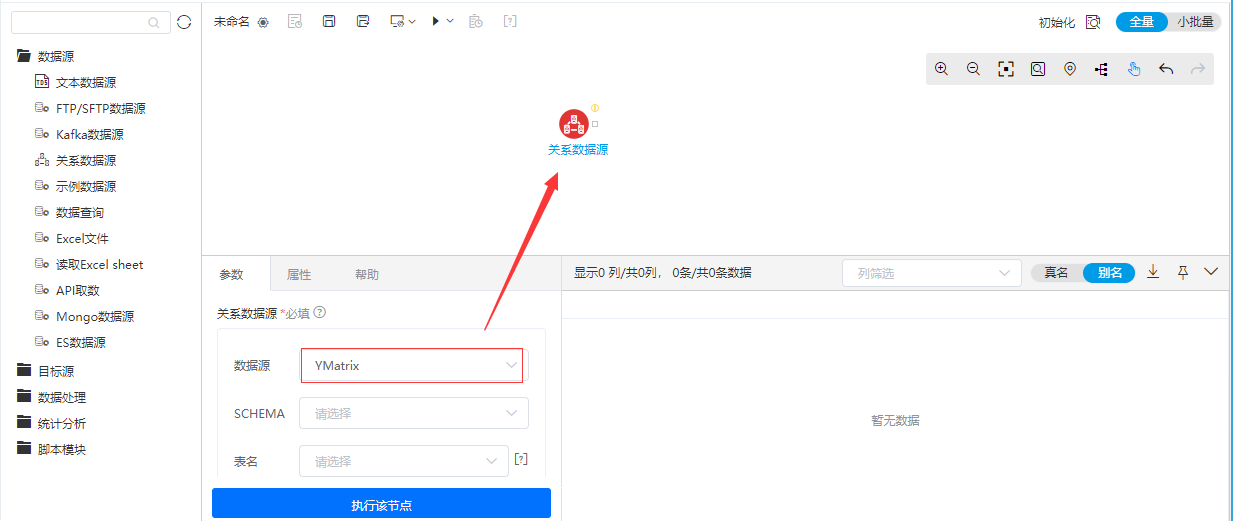
+【ETL】 数据源和目标源支持YMatrix数据库
功能简介
为了丰富ETL的数据源和目标源节点功能,新增了YMatrix数据库,用于YMatrix数据库数据库读取和写入操作。
...
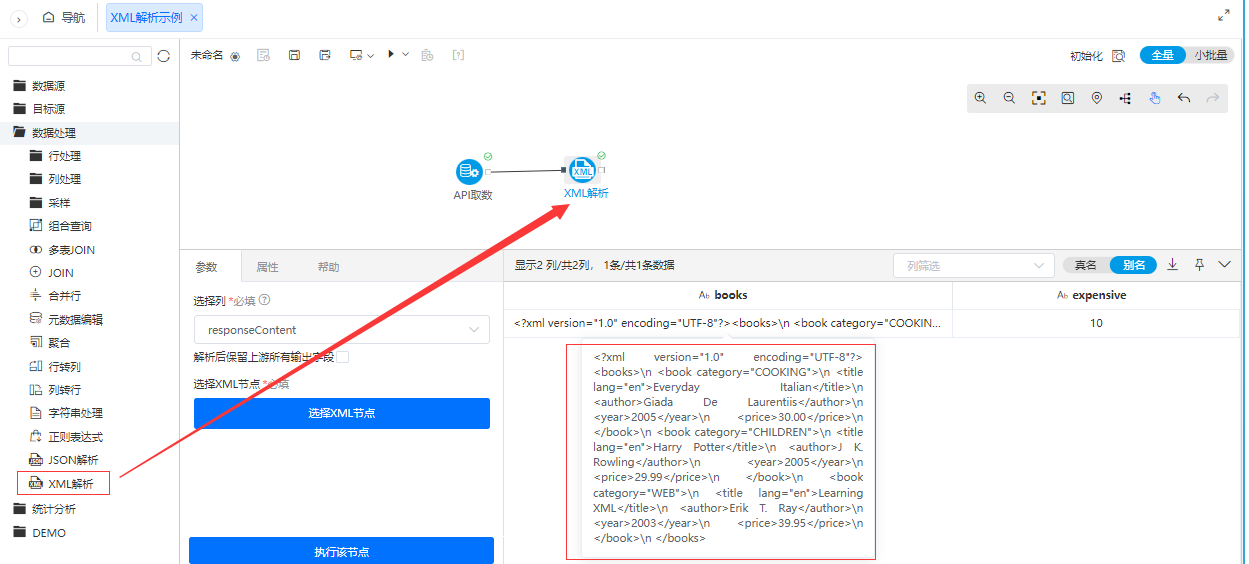
+数据处理支持XML解析
功能简介在列数较多或者前节点输出列不固定的情况下,都可以使用正则匹配的方式进行列选择,使选择列方式更加灵活。
+ 数据处理支持XML解析
...
为了丰富ETL的数据处理节点功能,新增了XML解析,用于XML的解析。
...
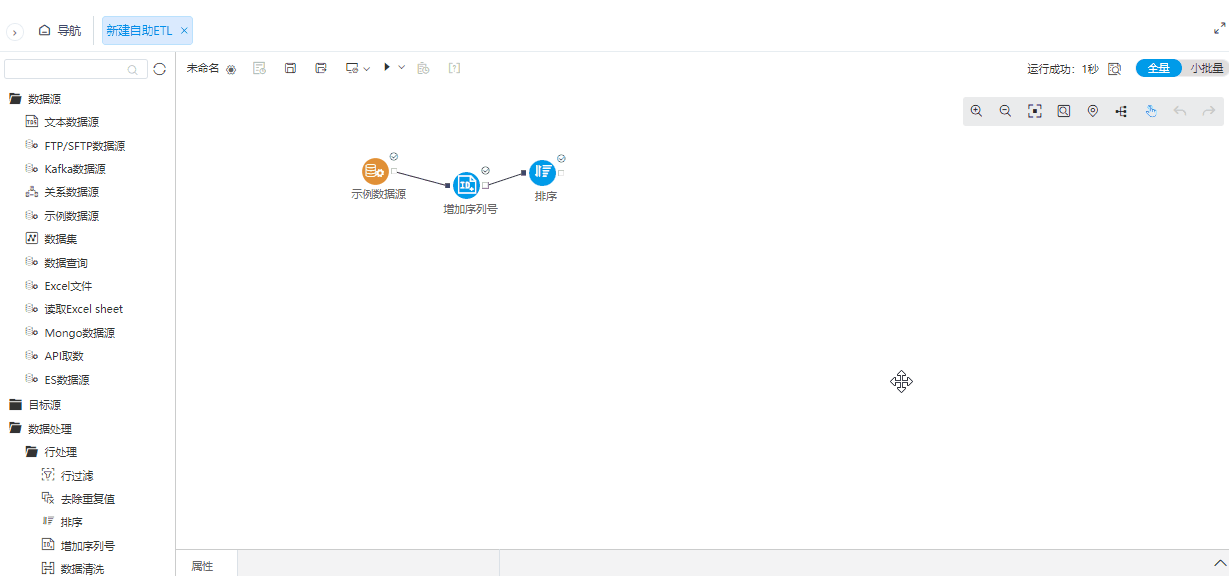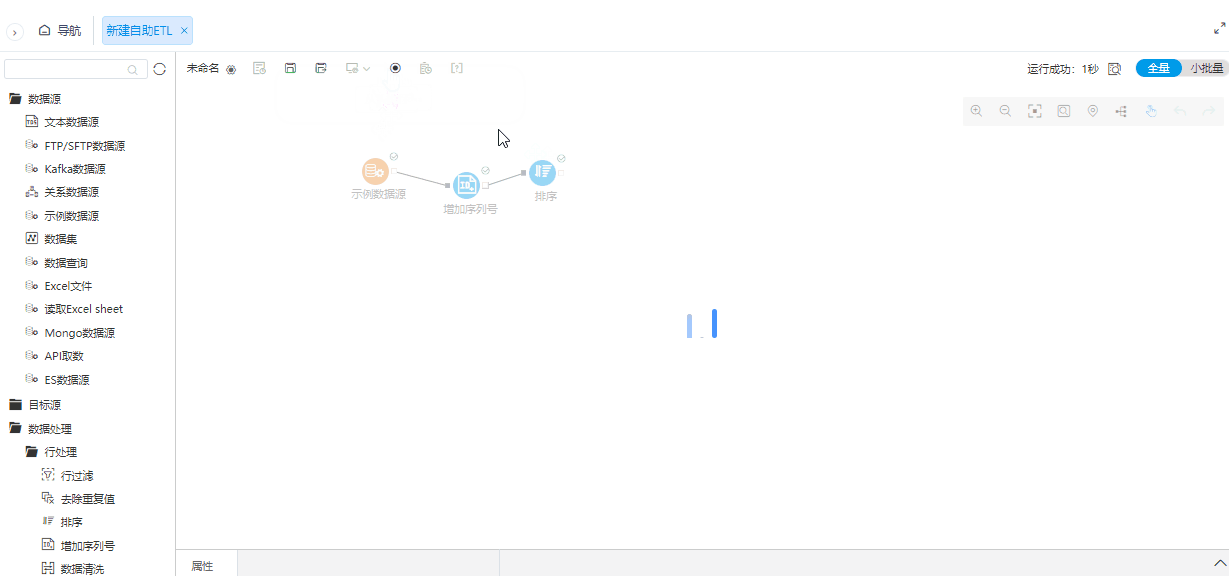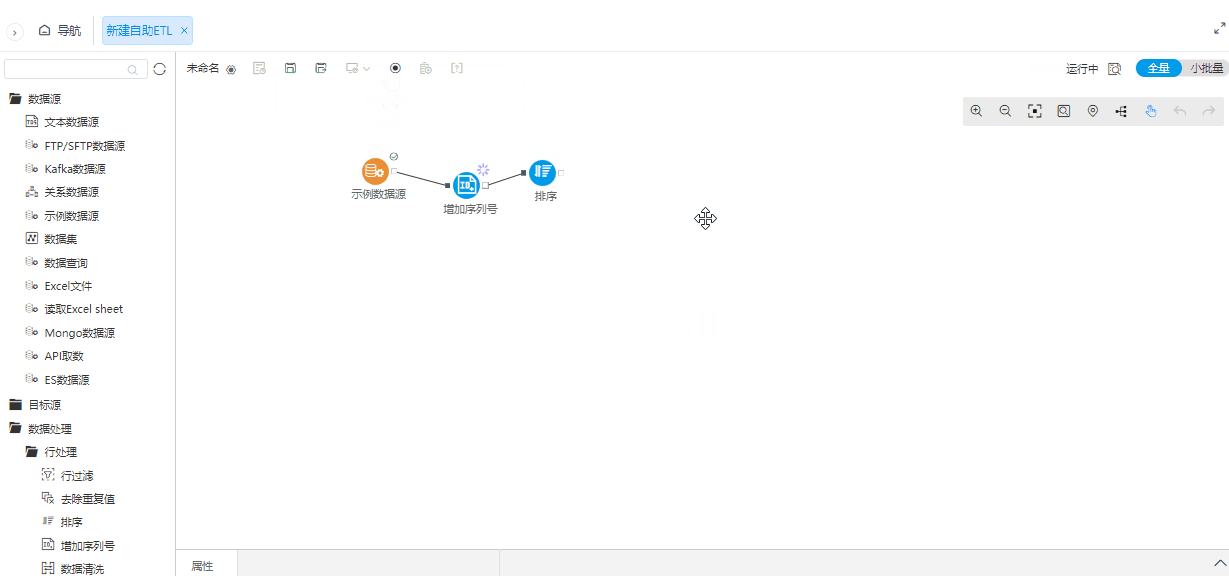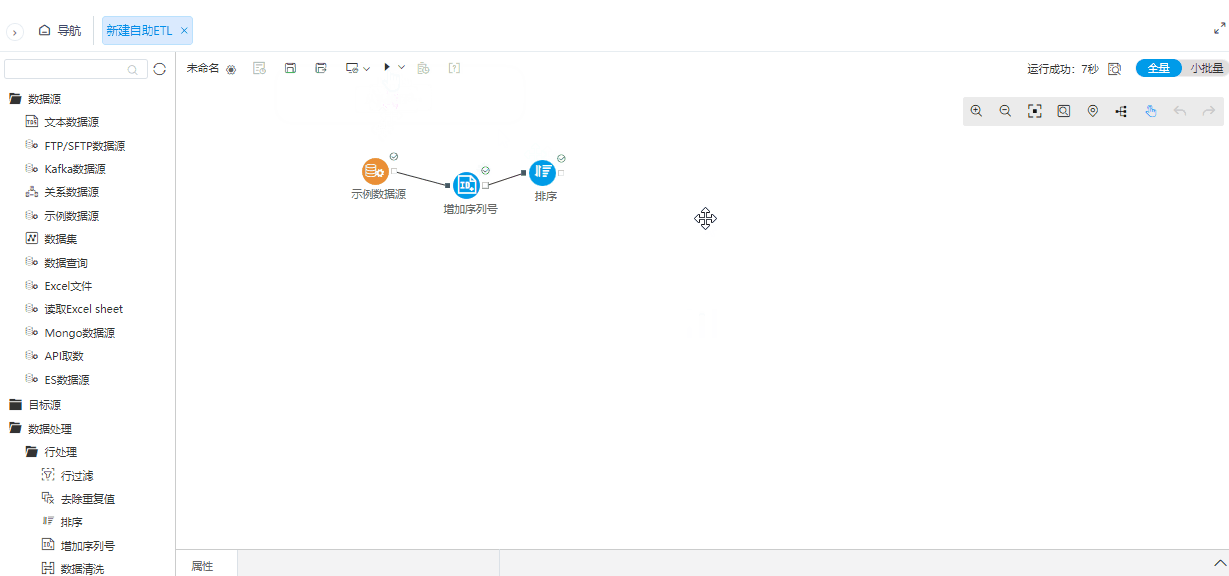
^画布工具栏中移动画布按钮支持画布拖拽
背景介绍
通过滚动条来调整ETL流程图的位置操作起来不方便,为了简化拖拽方式,增加鼠标的拖拽方式。
功能简介
当画布中的鼠标指针为十字箭头时,表示当前为拖拽功能。默认鼠标指针功能为拖拽功能,可以点击画布中移动画布按钮进行功能切换。
...
^小批量支持自动运行
背景介绍
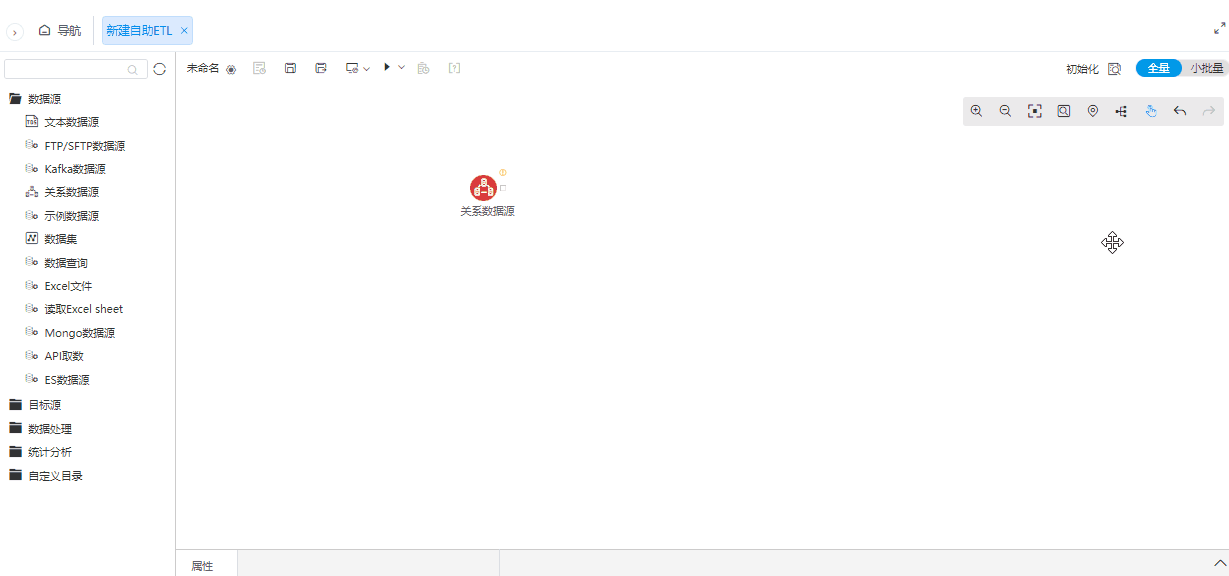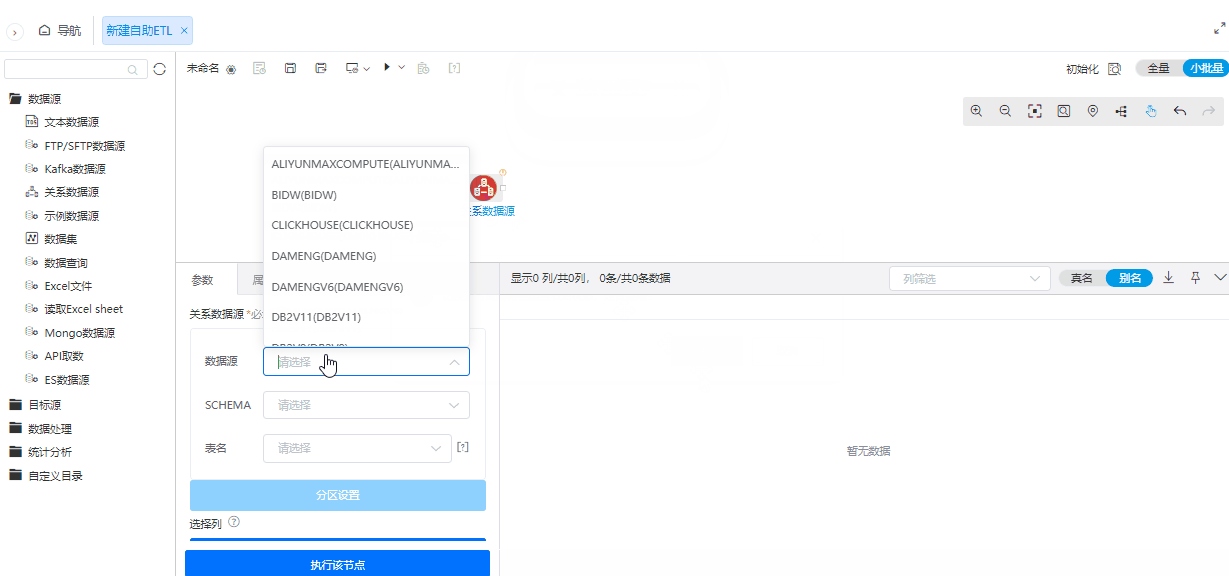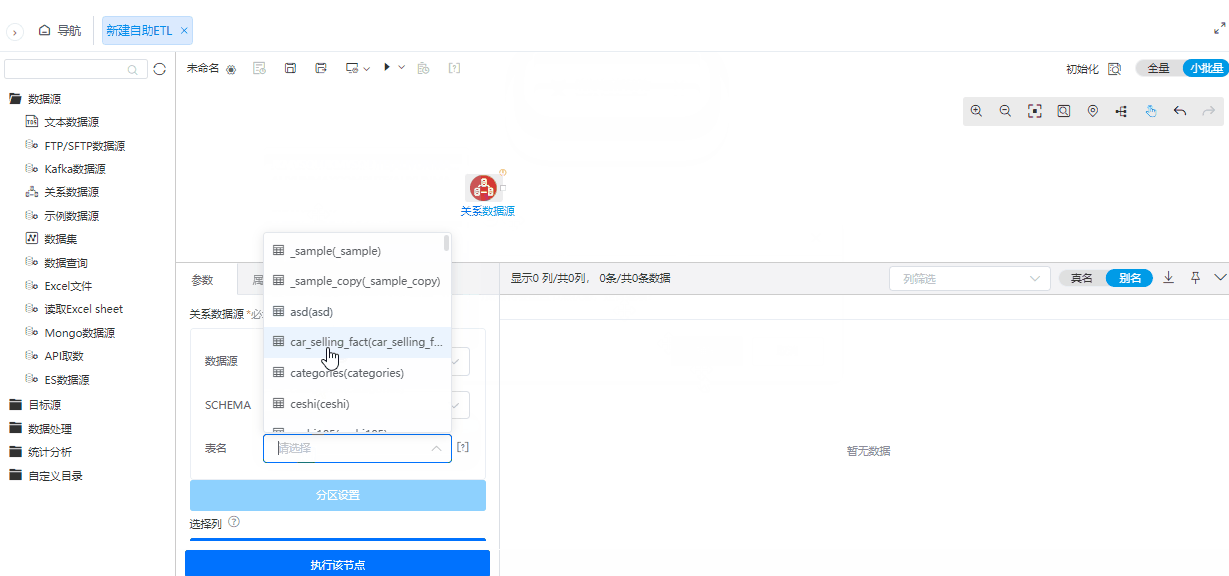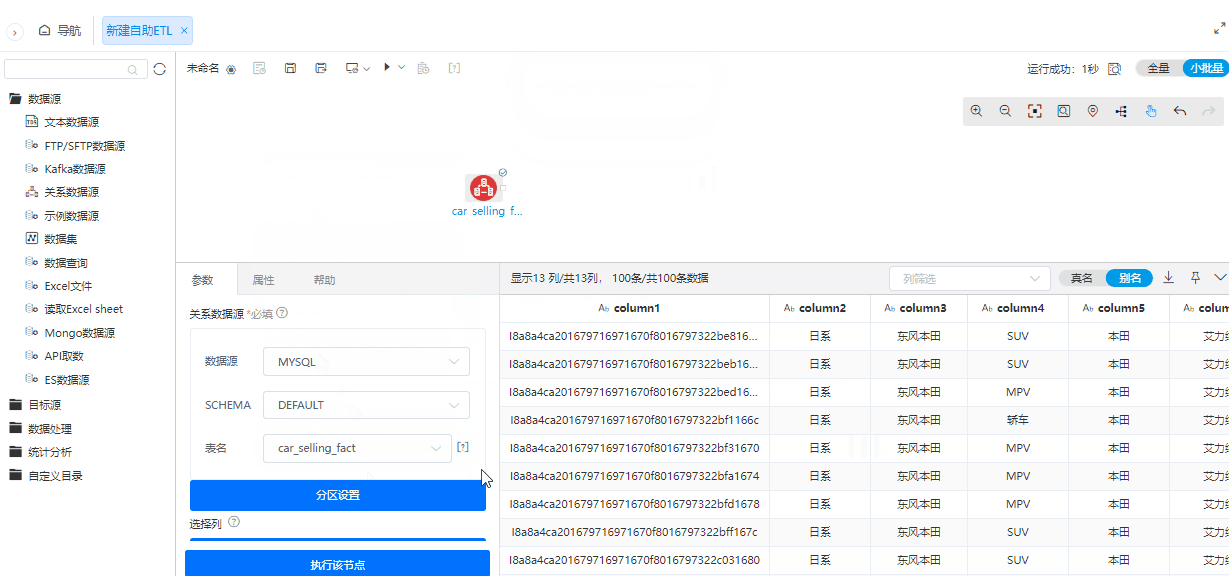
为了简化操作流程,在小批量配置情况下,大部分数据源支持自动执行节点。
功能简介
在首次配置数据源节点时,如果读取配置为小批量且该数据源支持小批量,那么配置完数据源节点后会自动执行节点。在配置为小批量且该数据源支持小批量前提下,修改数据源节点参数后,也会自动执行节点。
...
^全局执行增加是否使用缓存选项
背景介绍
行策略主要是优化客户在全部执行的时候,希望能够不使用缓存,否则数据会没有任何变化。
功能简介
ETL全局执行增加执行策略:一种是不使用缓存执行,一种是使用系统默认设置执行。在不使用缓存时,执行会重新运行所有节点。
...
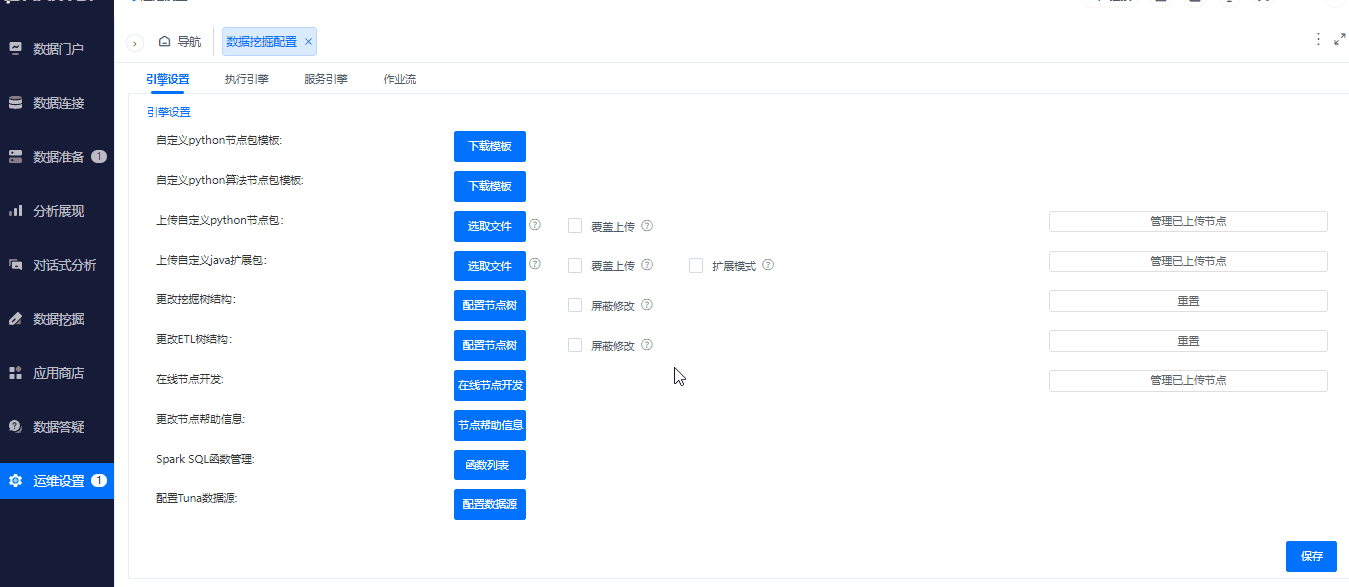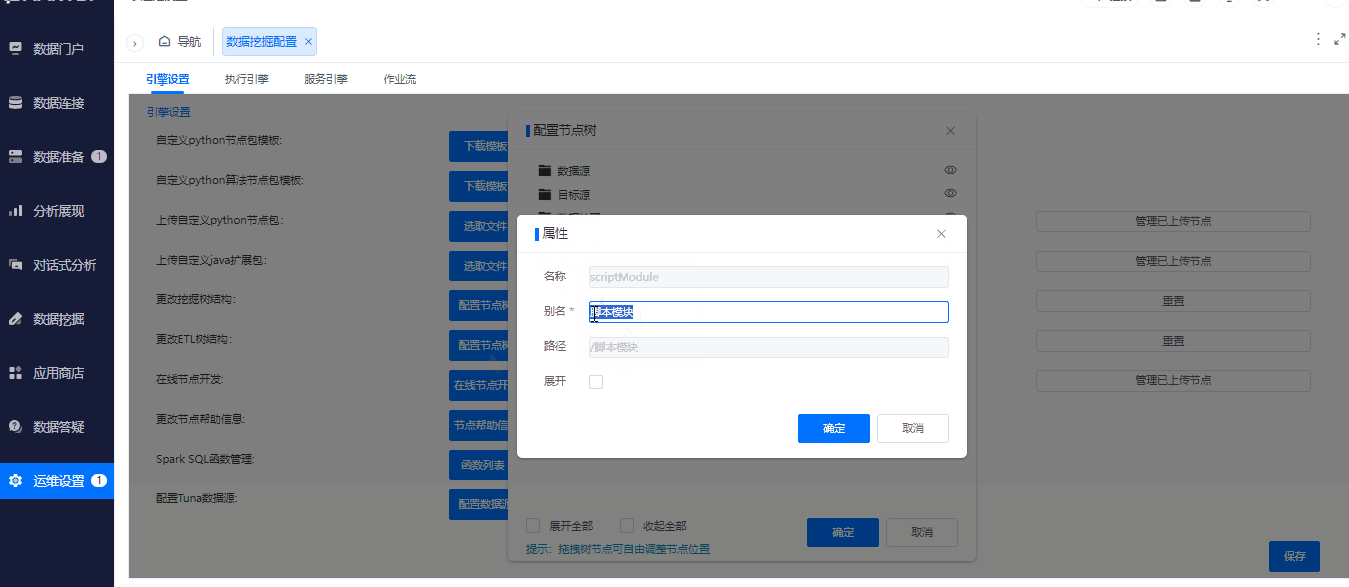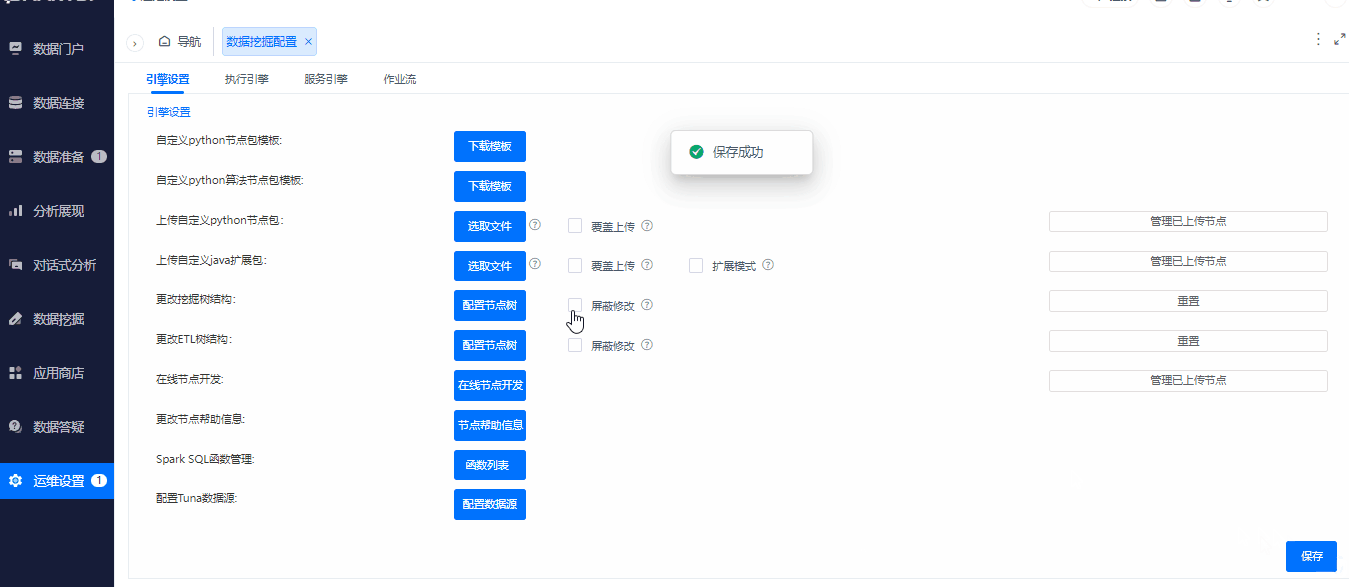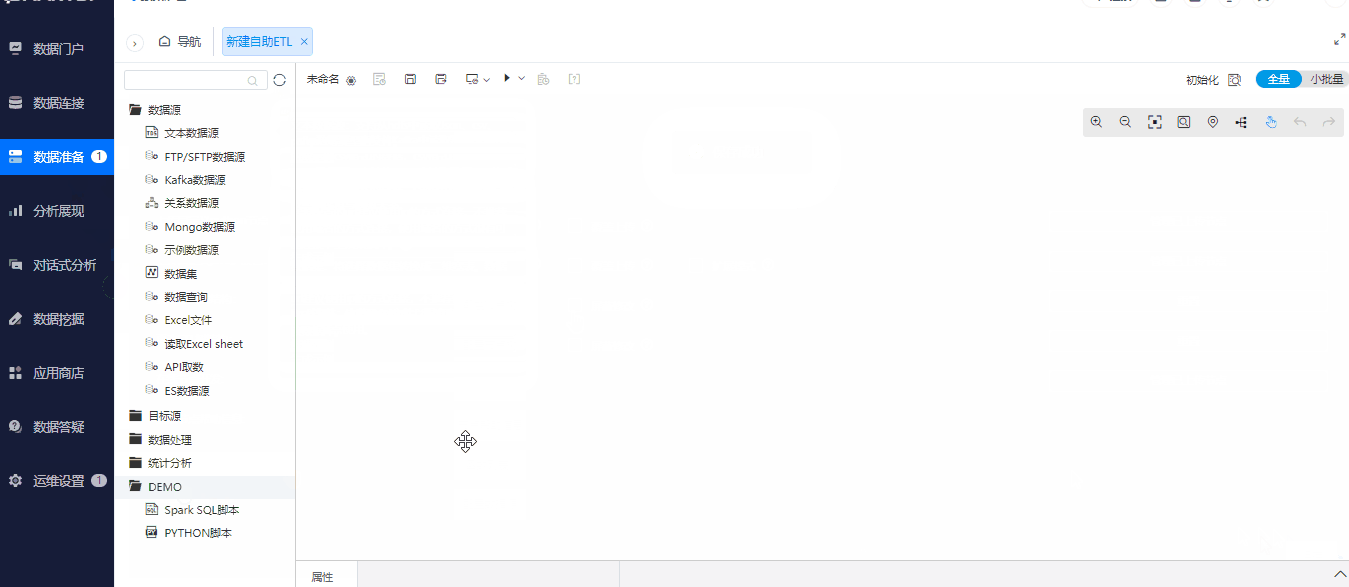
^节点目录支持改名称
背景介绍
在项目中经常会有修改节点目录名称的需求,增加节点目录修改名称满足了定制化需求。
功能简介
支持对节点树进行目录新建、名称修改、移动、隐藏操作。
...
^历史记录支持恢复
背景介绍
在项目中经常会遇到ETL最新图被修改问题,如果想恢复之前的图,只能重新拖一遍,比较繁琐。
功能简介
- 在历史中增加恢复按钮,点击恢复按钮则把该历史覆盖掉当前ETL流程图。
- 增加导出历史ETL流程图。

...
...
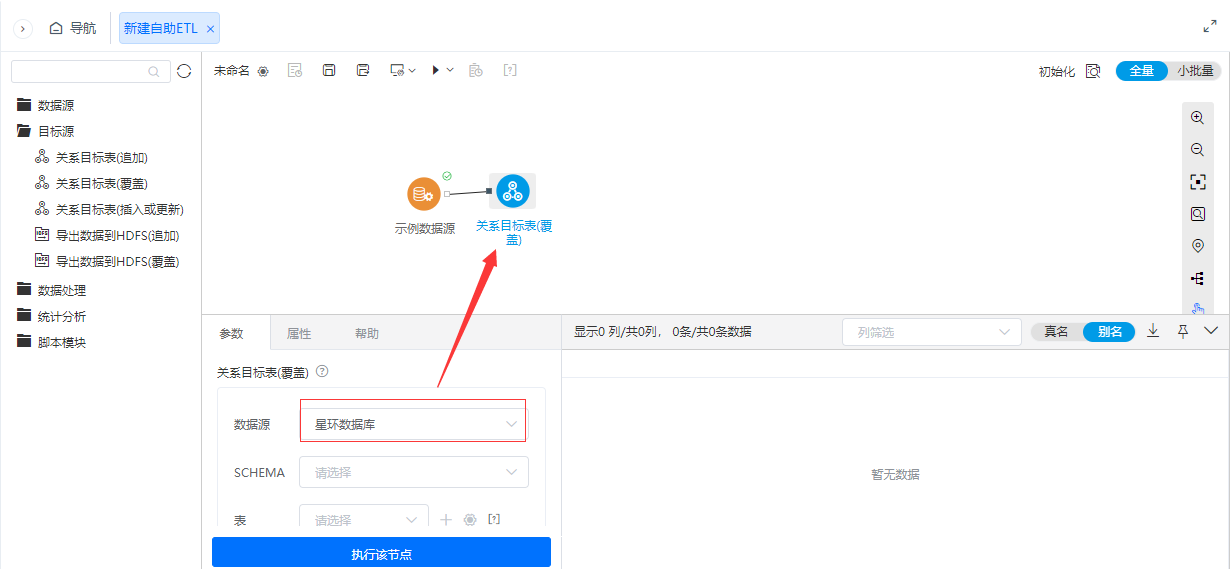
^目标源支持星环数据库建表
功能简介
为了丰富ETL的目标源导出节点功能,新增了星环数据库建表,用于星环数据库建表。
...
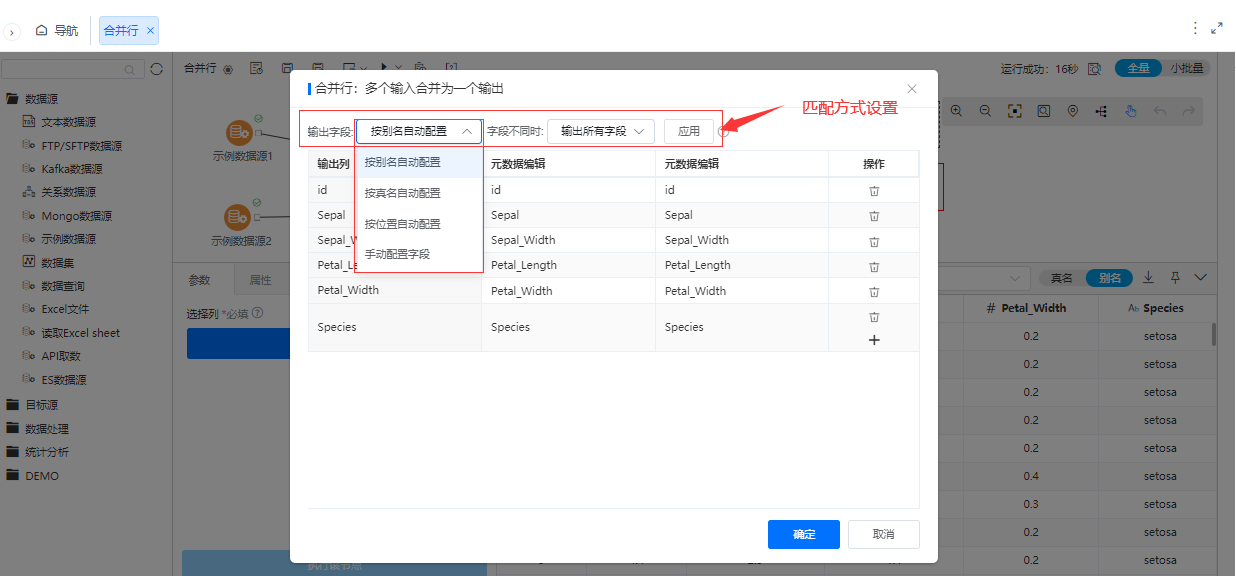
^ 合并行优化选择列弹窗新增列匹配机制
背景介绍
为了使列匹配更加灵活和易用,新增了列匹配机制。
功能简介
列匹配方式提供多种方式:
- 按别名自动匹配
- 按别名自动匹配
- 按位置自动匹配
- 手动配置字段
交互式仪表盘
...
^ 小批量支持自动运行
...
为了简化操作流程,在小批量配置情况下,大部分数据源支持自动执行节点。
- 在首次配置数据源节点时,如果读取配置为小批量且该数据源支持小批量,那么配置完数据源节点后会自动执行节点;
- 在配置为小批量且该数据源支持小批量前提下,修改数据源节点参数后,也会自动执行节点。
^ 全局执行增加是否使用缓存选项
...
在全部执行时,希望能够不使用缓存,否则数据会没有任何变化。
ETL全局执行增加执行策略:不使用缓存执行、使用系统默认设置。在不使用缓存时,执行会重新运行所有节点。

^ 历史记录支持恢复
...
在实际项目场景中,经常会遇到ETL最新图被修改问题,如果想恢复之前的图,只能重新拖一遍,比较繁琐。
在新版本中,支持在历史信息中恢复按钮则把该历史覆盖掉当前ETL流程图,且支持导出历史ETL流程图。

^ 画布工具栏中移动画布按钮支持画布拖拽
...
通过滚动条来调整ETL流程图的位置操作起来不方便,为了简化拖拽方式,增加鼠标的拖拽方式。当画布中的鼠标指针为十字箭头时,表示当前为拖拽功能。
^节点目录支持改名称
...
在实际项目场景中,经常会有修改节点目录名称的需求,增加节点目录修改名称满足了定制化需求。支持对节点树进行目录新建、名称修改、移动、隐藏操作。

+ SQL函数支持通过EXCEL导入方式增加
...
Spark SQL函数列表增加EXCEL导入功能,方便用户进行维护,如果需要进一步丰富内置Spark SQL函数,可以通过此方法补充更多Spark SQL函数。

3.5 交互式仪表盘
+ 新增指标拆解树组件
...
背景介绍
业务用户在做管理过程中,要解决一个业务层面的问题,需要将相关因素进行层层分解,来定位影响核心指标的关键因素。
...
指标拆解树组件支持添加核心指标和其相关维度,通过层层拆解来进行即席探索和进行根本原因分析。详见:指标组件 ⬝ 指标拆解树。

锚 新增多选输入框筛选器 新增多选输入框筛选器
+ 新增多选输入框筛选器
| 新增多选输入框筛选器 | |
| 新增多选输入框筛选器 |
...


