1. 概述
我们在建设数据仓库、数据集市的过程中,通常使用 ETL 工具把数据从“源库”抽取到“目标库”。“源库”中的历史数据,通常数据量特别大,比如有几千万甚至数亿条记录,而历史数据通常又不发生变化。在抽取数据的过程中,如果我们选择全量抽取,对于那些根本不会发生变化的历史数据,也抽取一遍,不仅没有任何意义,还要浪费大量的资源和时间。尤其是当有数亿条数据、并且需要进行复杂的数据加工时,很可能要耗费数小时,根本无法满足数据加工的时效性要求。因此,我们可以选择在进行 ETL 抽取的过程中,对数据进行 增量抽取,只抽取发生变化的部分。这样就可以让数据抽取的数据量变少,数据加工的时间变短,从而满足时效性要求。
2. 场景说明
我们在把数据从“源库”抽取到“目标库”的过程中,需要仔细分析要抽取的数据的变化情况。
- 对于很多“维度表”数据,比如产品、机构、客户等,它们可能随时都会发生变化,比如某个属性值改变。而如果源库中又不标识发生变化的时间戳,对于此种情况,我们只能选择全量抽取。
- 但对于很多“事实表”数据,比如订单表、订单明细表,通常只有最近的数据会发生变化。或者此类表中,我们会标记发生变化的那些记录,其表中有一个数据变更的时间戳字段。对于这些情形,我们就可以选择增量抽取了。
下面我们要抽取的数据是这样一张表,“每日主流热销车销售数据”表,其中有一个“销售日期”字段,此表的数据每天更新,但只更新前一日数据,更早的历史数据不会发生变化。下面我们就以此表为例,介绍如果通过 Smartbi “自助ETL/作业流”完成数据的增量抽取。
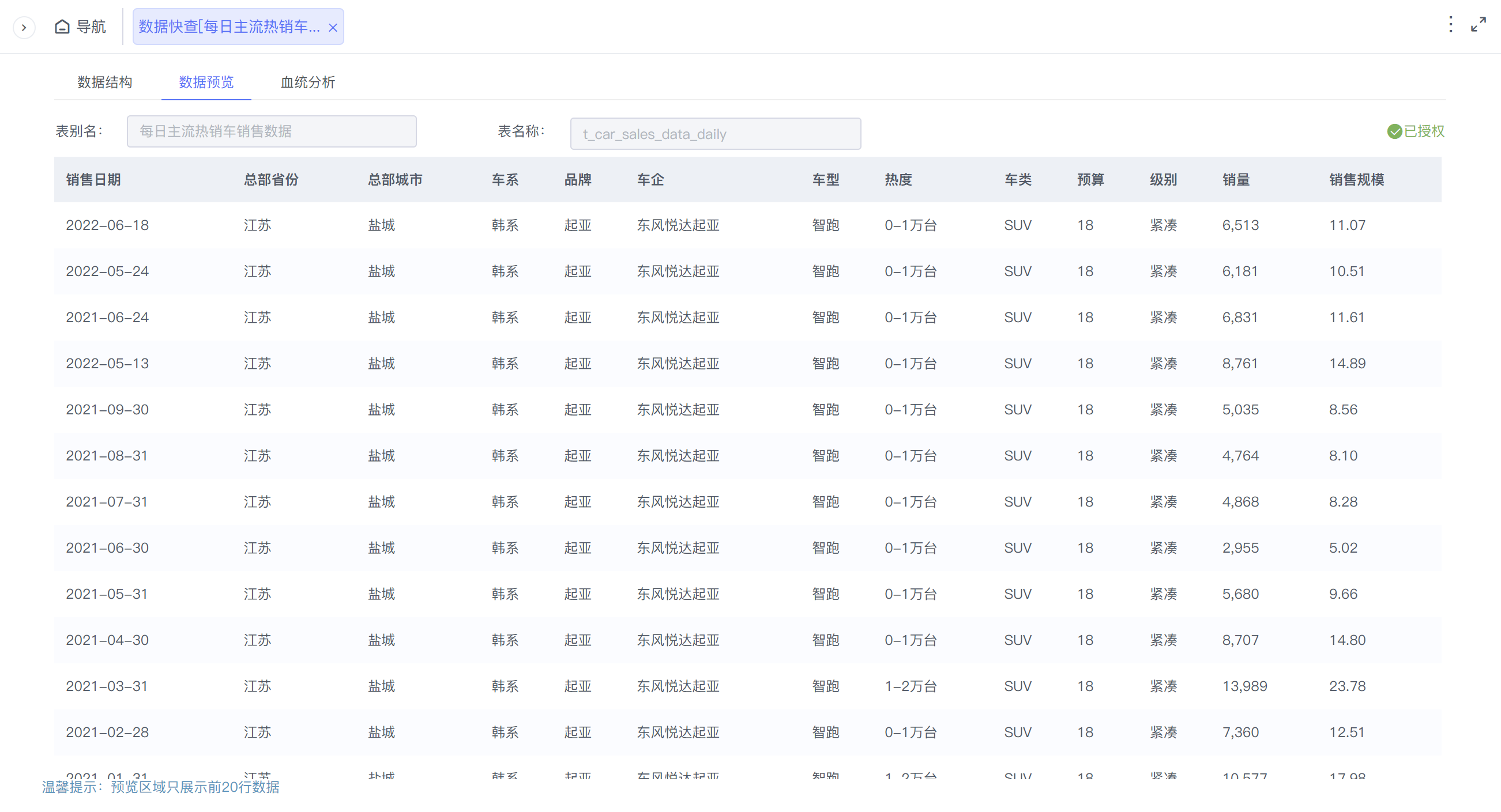
3. 自助ETL中配置增量抽取
在自助ETL中,要进行数据的增量抽取,需要借助“参数”的帮助,并在数据的“输入”节点上配置数据过滤。详细过程说明如下。
3.1
1. 概述
1. 概述
1. 概述
1. 概述
1. 概述
详情请参考:数据挖掘-参数设置


