...
| 注意 | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||
集群部署数据挖掘组件环境如下:
|
1、系统环境准备
1.1防火墙配置1 防火墙配置
为了便于安装,建议在安装前关闭防火墙。使用过程中,为了系统安全可以选择启用防火墙,但必须启用服务相关端口。
1.关闭防火墙
临时关闭防火墙临时关闭防火墙(立即生效)
| 代码块 | ||
|---|---|---|
| ||
systemctl stop firewalld |
永久关闭防火墙永久关闭防火墙(重启后生效)
| 代码块 | ||
|---|---|---|
| ||
systemctl disable firewalld |
...
| 代码块 | ||
|---|---|---|
| ||
systemctl status firewalld |
2.开启防火墙
相关服务及端口对照表:
| 服务名 | 需要开放端口 |
|---|---|
| Spark | 8080,8081,7077,[30000-65535] |
如果确实需要打开防火墙安装,需要给防火墙放开以下需要使用到的端口
开启端口:8080,8081,7077,[30000-65535]
...
2、Spark集群安装
| 注意 | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
|
2.1 配置主机名映射
将数据挖掘组件中的服务器主机名映射到hosts文件中(所有节点均需执行此操作)
...
| 注意 | ||
|---|---|---|
| ||
| Spark集群节点均需配置系统免密登陆 |
①登陆服务器,生成密钥① 登陆服务器,生成密钥
| 代码块 | ||
|---|---|---|
| ||
ssh-keygen |
输入ssh-keygen后,连续按三次回车,不用输入其它信息。
②复制本机公钥到其它机器② 复制本机公钥到其它机器
假设当前的系统用户为root(注意,每台机器使用同一个用户来安装), 那命令如下:
...
| 代码块 | ||
|---|---|---|
| ||
10-10-35-65 10-10-35-66 10-10-35-67 |

③将Spark安装包分发到Spark Work节点(10-10-35-66(slave-1)、10-10-35-67(slave-2))
...
| 代码块 | ||
|---|---|---|
| ||
cd /data/spark-3.1.2-bin-hadoop3.2/sbin ./start-all.sh |

2.5 检查Spark
在浏览器中输入:http://master节点的IP:8080,查看集群状态
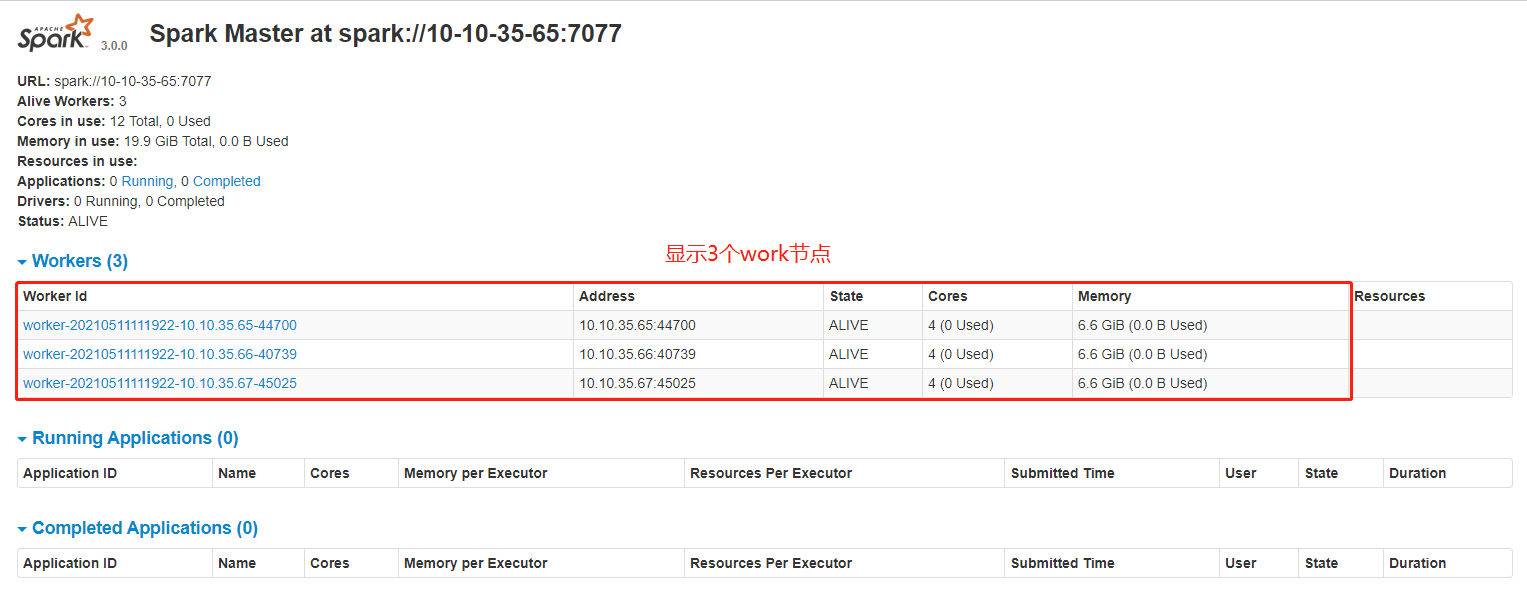
在spark节点提交任务测试进入/data/spark-3.1.2-bin-hadoop3.2/bin目录,执行以下命令(注意将”Spark-MasterIP”替换对应的IP或主机名)
| 代码块 |
|---|
./spark-submit --class org.apache.spark.examples.SparkPi --master spark://Spark-MasterIP:7077 /data/spark-3.1.2-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.0.0.jar 100 |
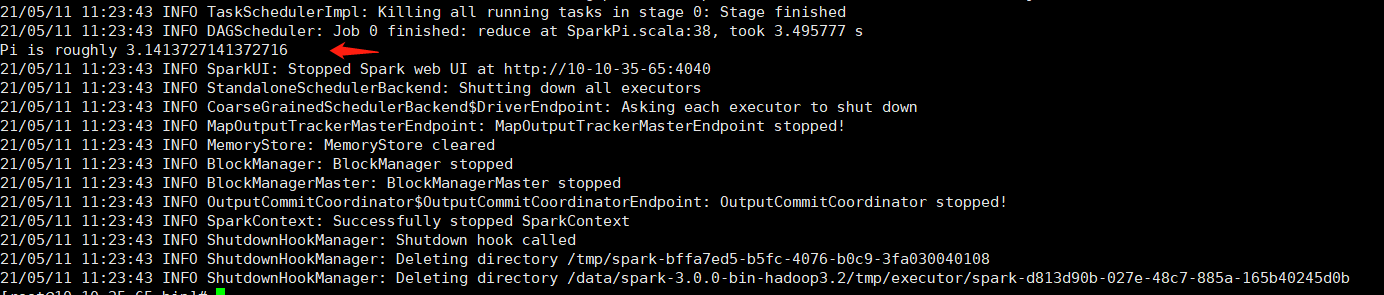
运行得出圆周率Pi的近似值3.14即部署成功。
...


