Hadoop 分布式系统基础平台,主要存储计算任务的中间结果数据。
文档环境
集群部署数据挖掘组件环境如下:
| 服务器IP | 主机名 | 组件实例 | 部署目录 |
|---|---|---|---|
| 10.10.35.64 | 10-10-35-64 | 数据挖掘-1,Zookeeper-1,Python-1 | /data |
| 10.10.35.65 | 10-10-35-65 | 数据挖掘-2,Spark-1,Hadoop-1 | /data |
| 10.10.35.66 | 10-10-35-66 | Spark-2,Zookeeper-2,Hadoop-2 | /data |
| 10.10.35.67 | 10-10-35-67 | Spark-3,Zookeeper-3,Hadoop-3,Python-2 | /data |
| 10.10.204.250 | 10-10-204-250 | Smartbi-Proxy | /data |
注意事项
数据挖掘数据量2000万以下时,可以不单独部署hadoop组件,提高数据挖掘服务器配置即可
1、系统环境准备
1.1 防火墙配置
为了便于安装,建议在安装前关闭防火墙。使用过程中,为了系统安全可以选择启用防火墙,但必须启用服务相关端口。
1.关闭防火墙
临时关闭防火墙(立即生效)
systemctl stop firewalld
永久关闭防火墙(需重启后生效)
systemctl disable firewalld
查看防火墙状态
systemctl status firewalld
2.开启防火墙
相关服务及端口对照表:
| 服务名 | 需要开放端口 |
|---|---|
| Hadoop | 9864,9866,9867,9868,9870,9000 |
如果确实需要打开防火墙安装,需要给防火墙放开以下需要使用到的端口
开启端口:9864,9866,9867,9868,9870
firewall-cmd --zone=public --add-port=9864/tcp --permanent firewall-cmd --zone=public --add-port=9866/tcp --permanent firewall-cmd --zone=public --add-port=9867/tcp --permanent firewall-cmd --zone=public --add-port=9868/tcp --permanent firewall-cmd --zone=public --add-port=9870/tcp --permanent firewall-cmd --zone=public --add-port=9000/tcp --permanent
配置完以后重新加载firewalld,使配置生效
firewall-cmd --reload
查看防火墙的配置信息
firewall-cmd --list-all
3.关闭selinux
临时关闭selinux,立即生效,不需要重启服务器。
setenforce 0
永久关闭selinux,修改完配置后需要重启服务器才能生效
sed -i 's/=enforcing/=disabled/g' /etc/selinux/config
1.2 取消打开文件限制
修改/etc/security/limits.conf文件在文件的末尾加入以下内容:
vi /etc/security/limits.conf
在文件的末尾加入以下内容:
* soft nofile 65536 * hard nofile 65536 * soft nproc 131072 * hard nproc 131072
2、Hadoop集群安装
Hadoop集群节点说明
Hadoop集群节点:
| 主机名 | 组件 |
|---|---|
| 10-10-35-65 | Hadoop namenode、Hadoop datanode |
| 10-10-35-66 | Hadoop datanode |
| 10-10-35-67 | Hadoop datanode |
2.1 配置主机名映射
将数据挖掘组件中的服务器主机名映射到hosts文件中(所有节点均需执行此操作,如果添加过则无需重复添加)
vi /etc/hosts
文件末尾添加(根据实际环境信息设置):
10.10.35.64 10-10-35-64 10.10.35.65 10-10-35-65 10.10.35.66 10-10-35-66 10.10.35.67 10-10-35-67
2.2 配置系统免密登录
注意
Hadoop集群节点均需配置系统免密登陆
由于文档环境Spark和Hadoop部署在相同服务器,故而无需重复配置系统免密登陆。
①登陆服务器,生成密钥
ssh-keygen
输入ssh-keygen后,连续按三次回车,不用输入其它信息。
②复制本机公钥到其它机器
ssh-copy-id -i ~/.ssh/id_rsa.pub root@10-10-35-65 ssh-copy-id -i ~/.ssh/id_rsa.pub root@10-10-35-66 ssh-copy-id -i ~/.ssh/id_rsa.pub root@10-10-35-67
测试是否设置成功
ssh root@10-10-35-65 ssh root@10-10-35-66 ssh root@10-10-35-67
如果不用输入密码,表示配置成功
2.3 安装JAVA环境
注意
Hadoop集群节点均需配置JAVA环境
由于文档环境Spark和Hadoop部署在相同服务器,故而无需重复配置JAVA环境。
解压jdk到指定目录:
tar -zxvf jdk-8u181-linux-x64.tar.gz -C /data
添加环境变量
vi /etc/profile
在文件末尾添加下面内容:
export JAVA_HOME=/data/jdk1.8.0_181 export JAVA_BIN=$JAVA_HOME/bin export CLASSPATH=:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_BIN
让配置生效
source /etc/profile
验证安装
java -version
2.4 安装Hadoop
2.4.1.准备Hadoop数据目录
注意
Hadoop集群节点均需创建Hadoop数据目录
①创建临时目录
mkdir -p /data/hdfs/tmp
②创建namenode数据目录
mkdir -p /data/hdfs/name
③创建datanode 数据目录
注意:这个目录尽量创建在空间比较大的目录,如果有多个磁盘,可以创建多个目录
mkdir -p /data/hdfs/data
2.4.2.解压Hadoop到指定目录
在管理节点执行(10-10-35-65).
tar -zxvf hadoop-3.2.3.tar.gz -C /data
2.4.3.修改Hadoop配置
在管理节点执行(10-10-35-65).
①修改hadoop-env.sh
cd /data/hadoop-3.2.3/etc/hadoop vi hadoop-env.sh
找到"export JAVA_HOME",修改为如下所示(替换成实际环境的路径):
export JAVA_HOME=/data/jdk1.8.0_181

找到"export HDFS_NAMENODE_OPTS", 在下面添加一行
export HDFS_NAMENODE_OPTS="-XX:+UseParallelGC -Xmx4g"

添加启动用户, 在文件最后添加以下内容
export HDFS_DATANODE_USER=root export HDFS_NAMENODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root

关于启动用户
启动用户可根据实际环境替换成实际的用户名
②修改core-site.xml
cd /data/hadoop-3.2.3/etc/hadoop vi core-site.xml
内容如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- 注意替换成实际的主机名 -->
<value>hdfs://10-10-35-65:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 注意替换成实际的路径 -->
<value>file:/data/hdfs/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>100800</value>
</property>
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
</configuration>
④修改hdfs-site.xml
cd /data/hadoop-3.2.3/etc/hadoop vi hdfs-site.xml
内容如下:
<configuration>
<property>
<name>dfs.name.dir</name>
<!-- 注意替换成实际的路径 -->
<value>file:/data/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<!-- 注意替换成实际的路径 -->
<value>file:/data/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.web.authentication.simple.anonymous.allowed</name>
<value>false</value>
</property>
<property>
<name>dfs.webhdfs.user.provider.user.pattern</name>
<value>(?s)!(.+)</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>16384</value>
</property>
</configuration>
建议
dfs.data.dir尽量配置在空间比较大的目录,可以配置多个目录,中间用逗号分隔
⑤修改hadoop-policy.xml
cd /data/hadoop-3.2.3/etc/hadoop vi hadoop-policy.xml
内容如下:
<configuration>
<property>
<name>security.client.protocol.acl</name>
<value>*</value>
<description>ACL for ClientProtocol, which is used by user code
via the DistributedFileSystem.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<!-- 这里把实验引擎ip, python执行节点ip,spark部署机器ip,hadoop部署机器ip,SmartbiMPP部署服务器ip都加上-->
<!-- ETL/数据挖掘中的组合查询节点,需要SmartbiMPP访问hdfs-->
<!-- 增加以下配置 -->
<property>
<name>security.client.protocol.hosts</name>
<value>10.10.35.64,10.10.35.65,10.10.35.66,10.10.35.67</value>
</property>
<!-- end -->
<property>
<name>security.client.datanode.protocol.acl</name>
<value>*</value>
<description>ACL for ClientDatanodeProtocol, the client-to-datanode protocol
for block recovery.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<!-- 这里把实验引擎ip,python执行节点ip,spark部署机器ip,hadoop部署机器ip,SmartbiMPP部署服务器ip都加上-->
<!-- ETL/数据挖掘中的组合查询节点,需要SmartbiMPP访问hdfs-->
<!-- 增加以下配置 -->
<property>
<name>security.client.datanode.protocol.hosts</name>
<value>10.10.35.64,10.10.35.65,10.10.35.66,10.10.35.67</value>
</property>
<!-- end -->
<property>
<name>security.datanode.protocol.acl</name>
<value>*</value>
<description>ACL for DatanodeProtocol, which is used by datanodes to
communicate with the namenode.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<!-- hadoop-policy.xml配置文件以上部分需要修改 -->
<!-- hadoop-policy.xml后续配置无需修改和添加,此处省略,避免文档篇幅过长 -->
<!-- ... -->
</configuration>
注意
hadoop-policy.xml配置文件仅添加两处配置项;
新增的security.client.protocol.hosts,security.client.datanode.protocol.hosts两个配置项中的值,要替换成实际环境的IP地址;
此配置文件是限制可以访问hadoop节点的服务器ip,提高hadoop应用的安全性。
⑥配置workers
cd /data/hadoop-3.2.3/etc/hadoop vi workers
把所有datanode节点的机器名加到worker文件,参考如下:
10-10-35-65 10-10-35-66 10-10-35-67

⑦将Hadoop安装包分发到其他节点
假设当前的系统用户为root命令如下:
scp -r /data/hadoop-3.2.3 root@10-10-35-66:/data/ scp -r /data/hadoop-3.2.3 root@10-10-35-67:/data/
2.4.4.配置Hadoop环境变量
注意
Hadoop集群节点均需设置环境变量
vi /etc/profile
在文件末尾添加下面内容:
export HADOOP_HOME=/data/hadoop-3.2.3 export PATH=$PATH:$HADOOP_HOME/bin
让配置生效
source /etc/profile
2.4.5.启动Hadoop
注意
①格式化Hadoop
cd /data/hadoop-3.2.3/ ./bin/hdfs namenode -format
仅第一次启动时需要执行格式化Hadoop操作,后续启动无需进行此操作
②启动Hadoop
cd /data/hadoop-3.2.3/ ./sbin/start-dfs.sh
③创建中间数据存储目录
hdfs dfs -mkdir /mining hdfs dfs -chown mining:mining /mining
2.4.6.验证安装
①在浏览器输入: http://Hadoop管理节点IP:9870/dfshealth.html#tab-overview 检查集群状态
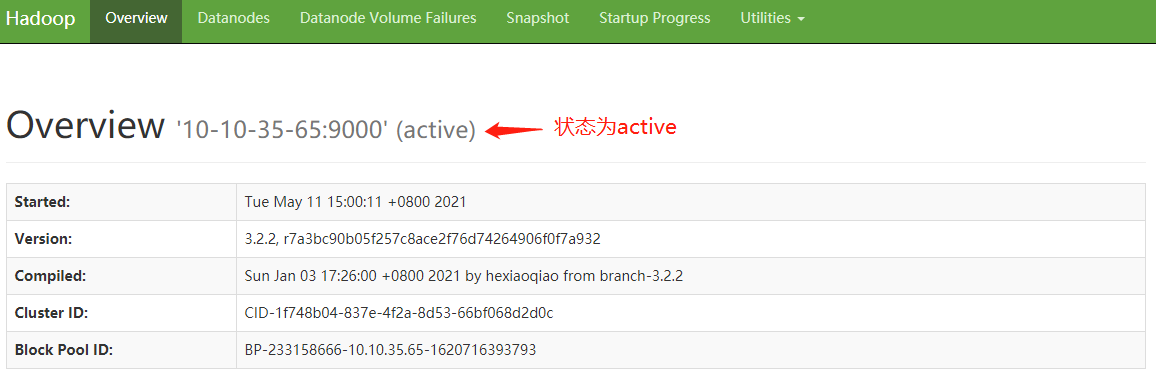
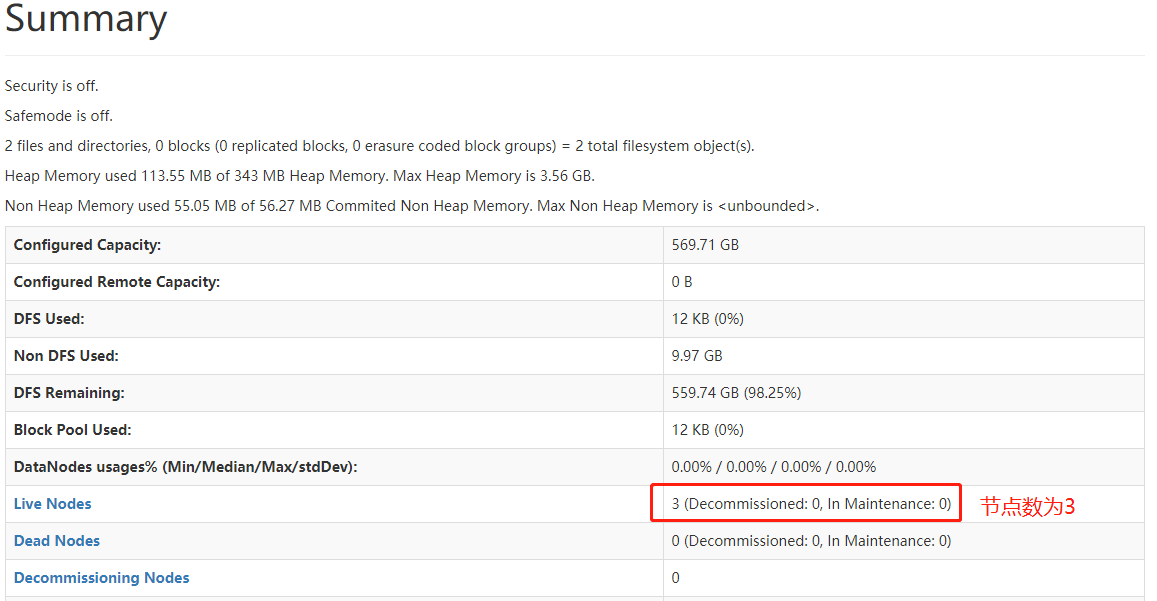
②检查mining目录是否创建成功
hdfs dfs -ls / #显示创建的/mining即表示创建成功

2.5 运维操作
在管理节点执行(10-10-35-65).
停止Hadoop集群
cd /data/hadoop-3.2.3/ ./sbin/stop-dfs.sh
启动Hadoop集群
cd /data/hadoop-3.2.3/ ./sbin/start-dfs.sh
查看日志
Hadoop的日志路径:/data/hadoop-3.2.3/logs
安装部署或者使用中有问题,可能需要根据日志来分析解决。


