1. 界面介绍
在“系统选项”界面选择 高级设置 ,“高级设置”界面由文本编辑器、格式化代码和帮助按钮组成,如下图:
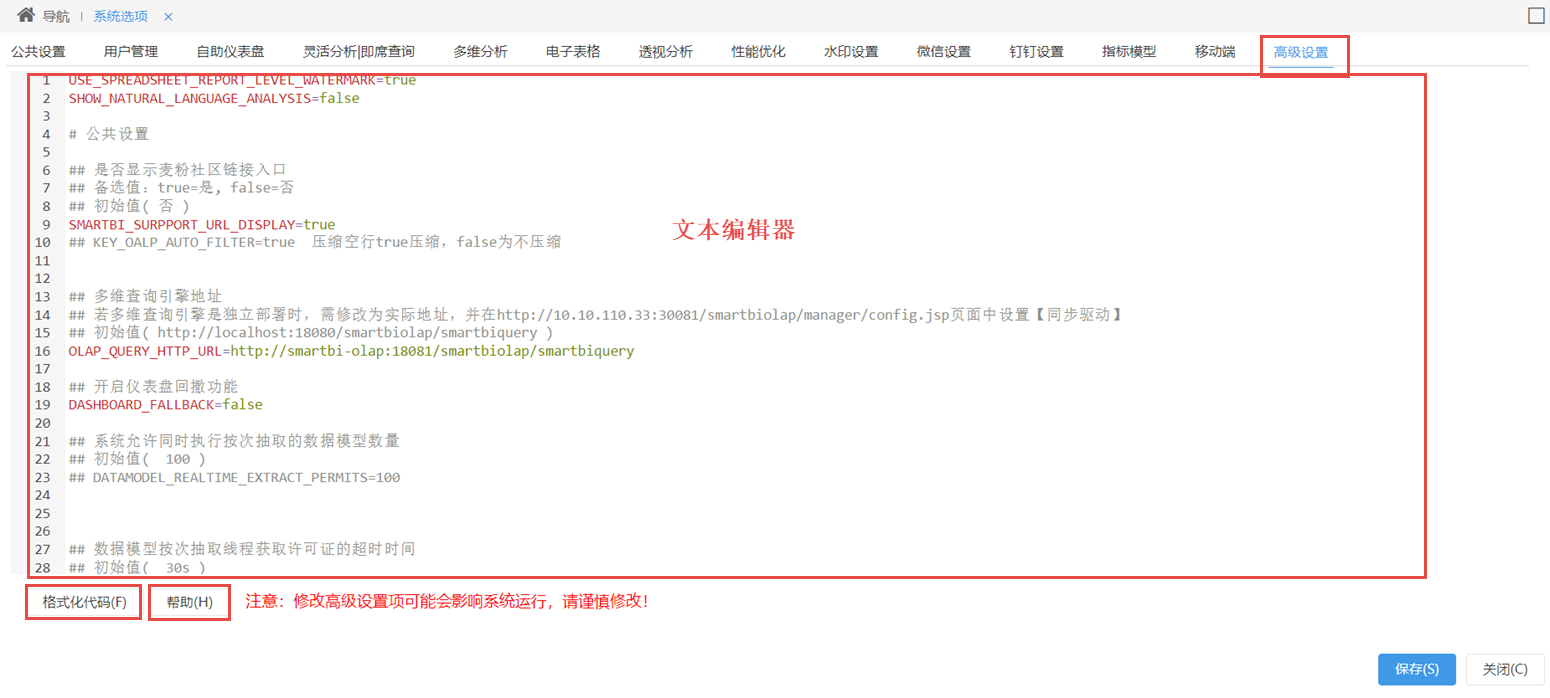
1.1文本编辑器
| 配置项 | 说明 | |
|---|---|---|
| 内容结构 |
| |
| 组名 | 每个分组的名称。 | |
| 配置项内容 | 配置项名称 | 该配置项的名称。 |
| 配置项说明 | 配置项的说明信息,包括备选值和初始值。 | |
配置项的值 | 由键值对“key = value”构成。
1、key值只能由字母、数字或下划线组成,如: NEW_TEST_KEY=VALUE。 2、key值不能以smartbi.和smartbix.为开始,如:smartbi.test(错误)。 3、不能有两个同名的key,如“test=value1”和“test=value2”。 关于设置配置项的值,有以下三种情况: 1、原配置项的值为修改值。 直接修改“=”后的值即可。 2、原配置项的值为默认值。
用户想要修改配置项的值,直接去除“##”,在“=”赋值即可。
3、恢复配置项的值为默认值,有以下三种方式: 1)将配置项的值修改为默认值,如下图: 2)在配置项前加“#”注释掉(推荐)。 3)直接删除配置项的键值对(建议慎用)。 当用户再次打开高级设置项页面时,恢复为默认值的项会显示为默认样式。
| |







(2)文本编辑器的内容较多时,我们可以通过Ctrl+F弹出搜索框,输入key值、描述等进行搜索。
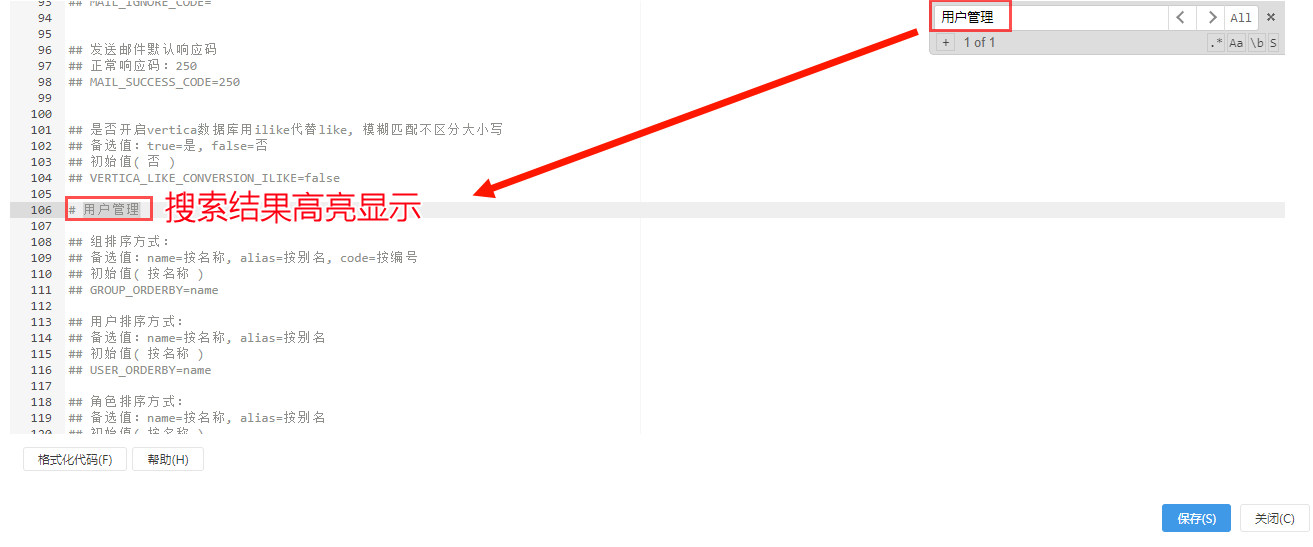
(3)在文本编辑器中我们还能添加“自定义属性”和“自定义注释”。
- 自定义属性:自定义属性需要后台有相应的处理逻辑才能生效,否则只是一个没有意义的键值对。如下所示:

- 自定义注释:用户可以使用“## ”在key的上方添加自定义注释,如下所示:

1、添加自定义属性之前需要与研发人员确认该属性是否生效。
2、自定义属性建议放置在高级设置项末尾,且添加空格加以和其他内容区别。
3、自定义注释建议独占一行,且在需要添加注释的行上方。
4、通常情况下如非必要,不推荐添加自定义注释,因为 格式化 操作会导致自定义注释消失。
1.2 格式化代码
功能简介:点击 格式化代码 按钮,会清除用户添加的自定义注释,且将所有的自定义属性移动至页面最下方。
使用场景:假如把初始的那些注释删掉了,点击 格式化代码 按钮,被删掉注释会重新生成回来。

1.3 帮助
点击 帮助 按钮,打开帮助中心,里面详细说明高级设置中每个设置项的作用和使用场景。
2. 设置项说明
“高级设置”中各设置项说明如下:
| 设置项 | 说明 | 默认值 | |
|---|---|---|---|
| 公共设置 | 是否显示麦粉社区链接入口 (SMARTBI_SURPPORT_URL_DISPLAY) | 用于设置产品系统右上角是否显示麦粉社区链接入口。 | 否 |
数据模型引擎地址 (OLAP_QUERY_HTTP_URL) | 用于配置多维查询引擎的地址,默认为内置安装Mondrian的地址。 若多维查询引擎为独立部署,需要修改实际地址,并在http://IP:端口/mondrian/manager/config.jsp页面中设置”同步驱动“,详情请参考 Windows 部署Smartbi OLAP Server、Linux 部署Smartbi OLAP Server。 | mondrian/smartbiquery | |
是否显示消息中心的社区栏 (SMARTBI_MESSAGECENTER_COMMUNITY_DISPLAY) | 用于配置消息中心面板“社区”栏是否显示。 注意 如果SMARTBI_SURPPORT_URL_DISPLAY=false,该项为true时也不会显示。 | 是 | |
数据模型加载时自动检测关系 (OLAP_QUERY_AUTO_ADD_CHECK_LINK) | 用于数据模型加载时是否自动检测及建立关系 | 是 | |
ZIP编码设置 (ZIP_CODE_SETTING) | 用于设置ZIP编码。如GBK、BIG5等等 | GBK | |
(JSP_PROCESSOR_TYPE) | 用于设置扩展包JSP处理器。包含默认和嵌入式。 | 嵌入式 | |
控制右上角多语言的切换是否显示 ENABLE_LANGUAGE_SETTINGS | 用于控制右上角多语言的切换入口是否显示。 | 否 | |
文件导出最大执行时长 (MAXIMUM_FILE_EXPORT_TIME) | 用于设置文件导出最大执行时长。初始值为15,单位为分,值可以是数值型或false,值为false时表示不限制导出时间。 | 15 | |
资源树加载数量 (NUMBER_OF_RESOURCES_LOADED) | 用于设置资源树加载数量。值必须为正整数,值为0时表示不限制加载数量。 | 1000 | |
参数搜索时,待搜索的备选值数量限制 (MAXIMUM_NUMBER_OF_SEARCH_LINES) | 用于参数搜索时,限制待搜索的备选值数量。值必须为正整数,值为0时表示不限制搜索备选值数量。 | 200000 | |
Cookie路径 (COOKIE_PATH) | 用于第三方系统通过服务器端SDK方法进行单点登录时,配置默认的cookie路径,保证第三方系统、浏览器使用的cookie的path是相同的。 | ||
可重定向的URL配置 (REDIRECTABLE_URL_CONFIGURATION) | 用于限制产品对站外网址的访问,配置指定的可跳转的站外URL。 | {"startWith":"","equal":""} | |
(NETWORK_TRANSNISSION_ALGORITHM) | 用于统一设置网络传输数据时,具体采用哪种加密算法。 | SF1 | |
离线导出并发数 (OFFLINE_EXPORT_CONCURRENT_NUMBER) | 用于设置系统导出的并发数量。在推荐配置项下,导出报表(20列 X 20000行),建议并发数设置为40,值设置过大可能会导致系统宕机。 | 40 | |
(UNIFIED_PROMPT_INFORMATION) | 用于自定义一个统一指引信息作为运行时错误的提示信息。若值为false使用系统默认的提示,,如需自定义,,请直接输入所需的文字描述。 | false | |
大数据作图允许的最大输出行数 (NUMBER_OF_BIGDATAECHARTS_OUTPUTROWS) | 图形设置选择“大数据作图”时,可输出的最大行数。值必须为正整数。 | 500000 | |
是否切换为V8的操作权限 (FUNCTION_IN_V8_MODE) | 用于切换用户管理中操作权限体系结构的新旧模式。 | 否 | |
通过openresource方式访问报表时,showLeftTree缺省值 (LEFTTREE_DEFAULT_SETTING) | 用于配置openresource.jsp方式集成打开即席查询未配置showLeftTree参数时,左侧树的默认展开方式。 | 是 | |
流程版本设置 (WORKFLOW_VERSION) | 用于设置流程的新旧版本。 | new | |
发送邮件忽略响应码 (MAIL_IGNORE_CODE) | 用于设置发送邮件忽略响应码。 | ||
发送邮件默认响应码 (MAIL_SUCCESS_CODE) | 用于设置发送邮件成功时的响应码。 | 250 | |
是否开启vertica数据库用ilike代替like,模糊匹配不区分大小写 (VERTICA_LIKE_CONVERSION_ILIKE) | 用于条件筛选,设置是否启用模糊匹配不区分大小写,只针对vertica业务库生效。影响范围如下: 自助数据集-筛选器-条件:模糊匹配、不匹配、开头为、结尾为、开头不为、结尾不为。 自助仪表盘-筛选器-操作符:模糊匹配、不匹配、开头为、结尾为、开头不为、结尾不为。 透视分析-过滤字段-过滤条件:开头为、结尾为、包含、不包含。 即席查询-条件字段-过滤条件:开头为、结尾为、包含、不包含。 | 否 | |
是否为新用户,关闭旧数据集的新建入口 DISABLE_OLD_DATASET_NEW_ENTRY | 用于判断用户是否为新用户。新用户或设置为true,关闭旧数据集的新建入口。 旧数据集:原生SQL数据集、SQL数据集、可视化数据集、存储过程数据集、Java数据集(包含Java数据源)、多维数据集、即席查询、透视分析 | true | |
参数搜索时,待搜索的备选值数量限制 MAXIMUM_NUMBER_OF_SEARCH_LINES | 用于限制参数搜索时最大搜索备选值的数量。值必须为正整数,值为1时表示不限制搜索备选值数。 如果参数类型为SQL类型,搜索逻辑为先获取备选值SQL的所有搜索结果,然后遍历搜索结果与搜索值进行匹配。 如果用户没有配置此设置项,系统默认是200000,即只查找前200000个备选值中满足搜索条件的结果。如果想要搜索出全部满足条件的结果,需要将选项的值设置为0。 | 200000 | |
用户管理 | 组排序方式 (GROUP_ORDERBY) | 用于设置用户管理模块中“组”的排序方式,主要有:按名称、按别名、按编号。 | 按名称 |
| 用户排序方式 (USER_ORDERBY) | 用于设置用户管理模块中“用户”的排序方式,主要有:按名称、按别名。 | 按名称 | |
角色排序方式 (ROLE_ORDERBY) | 用于设置用户管理模块中“角色”的排序方式,主要有:按名称、按别名。 | 按名称 | |
| 不允许调用没有用权限的服务接口 (AUTHORITY_CONTROL_SWITCH) | 用于控制越权访问,控制操作权限设置。 | 否 | |
允许调用DataSourceService的executeUpdate方法 (ALLOW_CALL_EXECUTEUPDATE_METHOD) | 控制是否能调用DataSourceService的执行sql的方法(通过RMIServlet来调用)。 | 是 | |
允许调用UserService的getPassword方法以及获取sessionAttribute中的password (ALLOW_CALL_GET_PASSWORD_METHOD) | 控制是否允许调用UserManagerModule中的getPassword方法;是否允许通过StateModule获取session属性的方式获取密码(通过RMIServlet来调用)。 2023年8月4号之后的版本,只能获取到自己的密码。 | 是 | |
允许设置的sessionAttribute的key(用英文逗号分隔) (ALLOW_SET_SESSION_ATTRIBUTES) | 允许通过调用CommonService: setSessionAttribute接口设置的属性 | mobileClientType,PortalRightFrameHeight,ShowPath | |
允许获取的sessionAttribute的key(用英文逗号分隔) (ALLOW_GET_SESSION_ATTRIBUTES) | 允许通过调用StateModule: getSessionAttribute接口获取的属性 | mobileClientType,user | |
(EXTEND_DEPARMENT_AND_USER_CLASS) | 用于控制组管理员角色可管理的用户组范围。备选值如下:
| default | |
| 索引设置 | 索引服务器URL地址 (INDEX_SERVER_URL) | 用于配置索引服务器URL地址(当索引服务器单独部署时填写此地址,否则留空)。 通常情况下索引服务器默认与Smartbi服务器部署在一起,此时不需要设置索引服务器URL地址。 当索引服务器与 Smartbi服务器分开部署时,则需要设置索引服务器的URL地址。常用于Smartbi应用服务器需要集群部署时,索引服务器不支持集群,此时需要将索引服务器单独部署。 | |
索引在服务器上的保存目录 (INDEX_SAVE_DIRECTORY) | 用于设置索引在索引服务器中的保存目录。 | ||
索引搜索每页显示行数 (INDEX_SEARCH_ROWS_PER_PAGE) | 用于设置进行元数据搜索时,搜索结果在每页显示的记录行数,其中每个资源的完整说明才算是一行记录。 | 20 | |
| 性能优化 | 内存数据库最大返回行数 (MEMDB_MAXROW) | 用于设置默认从数据库中返回多少条记录放到缓存中。默认记录是1000条。此值设置越大,则内存占用越多。 | 1000 |
数据集查询Fetchsize (MEMDB_FETCH_SIZE) | 数据集查询时setfetchsize设置的数量。如果设置的值太大,会导致内存溢出。 | 5000 | |
是否设置Statement的最大行数 (SET_STATEMENT_MAX_ROWS) | 用于设置是否限制Statement从数据库中取数的最大行数,能够避免取数过大导致系统内存溢出,限制方式一般是抛错、返回空等。 最大行数:通过性能优化的“数据集单次查询最大单元格数”设置项限制。
Statement 是 Java 执行数据库操作的一个重要接口,用于在已经建立数据库连接的基础上,向数据库发送要执行的SQL语句。 | 是 | |
清理闲置缓存时间间隔 (POOL_MIN_EVICTABLE_IDLE_TIME_MILLIS) | 用于自定义缓存的最长闲置时间,若指定时间内无调用该缓存则将其回收清理。 当【线程运行清空缓存时间间隔】值大于0时生效,设置后需清空系统缓存。 | 30(单位:分钟) | |
线程运行清空缓存时间间隔 (POOL_TIME_BETWEEN_EVICTION_RUNS_MILLIS) | 用于设置在空闲连接回收器线程运行期间休眠的时间值。 若设置其值为负数,则不运行空闲连接回收器线程,即不清除闲置缓存。 | -1(单位:毫秒) | |
脱敏规则最大缓存单元格数量 (MASKING_RULE_CACHE_MAX_QUANTITY) | 用于设置脱敏规则最大缓存单元格数量。初始值(1000),请根据系统可用的内存进行调整。 | 1000 | |
参数备选值最大返回行数 (PARAM_SV_MAXROW) | 用于设置参数备选值的最大返回行数。 | 10000 | |
报表个人参数数量 (USER_PARAMS_MAX_COUNT) | 用于设置单个报表中个人参数的最大数量。 | 5 | |
业务数据缓冲池/对象最大激活个数 (DBSQLRESULTSTOREPOOL_MAXACTIVE) | 用于设置业务数据对象最大允许设置的最大对象总数。 | -1 | |
数据集定义对象池/对象最大激活个数 (BUSINESSVIEWBOPOOL_MAXACTIVE) | 用于设置数据集定义对象最大允许设置的最大对象总数。 | -1 | |
是否启用告警 (ALERT_ENABLE) | (1)适用场景:当用户查询的数据量巨大容易会引起内存溢出,为了确保系统的稳定性,可启用“告警”实时监控查询单元格数量和预警。 (2)功能说明:启用告警可实时监控全系统报表的单元格数量,当超过设置的阈值后,终止用户查询后并给管理员自动发送告警信息。 (3)告警监控的报表类型:数据集、透视分析、电子表格。 | 是 | |
告警提示方式 (ALERT_MODE) | (1)用于设置告警的提示方式,分为站内信和邮件提示,可多选。 (2)邮件地址可通过 系统选项>公共设置的【系统运维信息收件地址】设置。 | 站内信 | |
参数缓存 (PARAM_AUTOCACHE) | (1)效果:用于控制参数数据是否需要缓存。 (2)参数缓存:用来存储参数默认值和备选值数据信息。属于系统全局设置,默认针对所有参数生效。点击此处查阅详情。 (3)注意事项:产品支持对局部参数设置是否需要缓存;参数自身的缓存设置优先级>系统选项中全局参数缓存设置的优先级。 | 是 | |
导入并发数 (SystemImportThreadSize) | 用于设置导入的并发数。根据系统内存和最大允许导入的文件大小,计算出一个数值。配置的数值不允许超过计算出的数值。导入并发数必须为正整数或-1。 | -1 | |
| 抽取 | 透视分析临时表个数 (INSIGHT_MAX_TEMPTABLE) | 用于设置抽取的临时表数量(临时表在配置的高速缓存库中创建)。 | 100 |
(BACKUP_TAB_RETAIN_NUM) | 用于设置在数据抽取中数据库保留的备份表的个数。 | 5 | |
系统允许同时执行按次抽取的数据模型数量 (DATAMODEL_REALTIME_EXTRACT_PERMITS) | 用于设置限制数据模型中按次抽取的并发数。 | 100 | |
数据模型按次抽取线程获取许可证的超时时间 (DATAMODEL_REALTIME_EXTRACT_WAIT_TIMEOUT) | 用于设置数据模型中按次抽取的限制时间。 | 30 | |
页面 | 电脑边框设置 (DASHLET_TITLE_AND_BORDER_DISPLAY) | 用于设置在电脑上仪表盘中是否显示承载资源的DashLet的皮肤内容,选项有:显示边框和按钮、只显示按钮、只显示边框和都不显示。 | 显示边框和按钮 |
移动设置边框设置 (IPAD_DASHLET_TITLE_DISPLAY) | 用于设置在移动设备上仪表盘中是否显示承载资源的DashLet的皮肤内容,选项有:不显示边框和显示边框。更多信息如下:
| 不显示边框 | |
导出值类型 (PAGE_EXPORT_VALUETYPE) | 用于设置导出的内容是显示值还是真实值,选项有真实值和显示值。 | 真实值 | |
分析报告 | 开启资源丢失提示 (OFFICE_REPORT_LOSE_RESOURCES) | 用于是否开启资源丢失提示。 | 否 |
(OFFICE_REPORT_MAX_SEMAPHORE_NUM) | 用于设置打开分析报告加载资源方式为串行,或者控制并发运行的最大线程数。 | 无限制 | |
分析报告打开线程超时时间 (OFFICE_REPORT_OPEN_TIMEOUT) | 用于设置分析报告打开线程超时时间。打开分析报告,超过系统选项设置超时时间后,会中断线程,提示执行异常,系统监控日志会打印异常信息。值可以是正整数或OFF,值为OFF时表示无超时时间。 | 无限制 | |
| 电子表格 | 移动端URL控件缩放方式 (MOBILE_URL_RESOURCE_SCALE) | 用于设置电子表格的URL控件在移动端的缩放方式
| 默认 |
回写数据大小限制 (SSR_WRITEBACK_DATA_LIMIT) | (1)适用场景:为了避免用户回写数据太多、回写操作大量单元格导致系统宕机。 (2)功能说明:用于限制用户每次回写的数据单元格的数量。
| 1400~1500 | |
设置电子表格excel插件提交方式 (SPREAD_SHEET_EXCELADDIN_REPORT_PUBLISH_UPLOADTYPE) | 插件发布报表请求内容长度大于500000时的提交方式,小于时都使用FormUpload提交。
| MultipartMerge | |
(SPREAD_SHEET_EXCELADDIN_REPORT_SHOW_SYSTEMDATASET) | 用于设置excel插件中是否开启电子表格旧资源数据集。 | false | |
| 透视分析 | 透视分析聚合函数扩展 (INSIGHT_AGGREGATION_FUNCTION) | 用于当计算字段设置为无聚合时,其表达式可以使用除sum,avg,max,min,count,distinct count之外的聚合或分析函数。 格式:函数名称[,函数名称...] | |
| 移动端 | 允许移动端首页更多菜单显示调试 (MOBILE_HOME_DEBUG_ENABLED) | 用于配置是否允许移动端首页更多菜单显示调试。 | 是 |
SmartbiMpp | (CLICK_HOUSE_AOTU_CONVERT_NULL) | 用于回写、导入、抽取等操作时自动处理NULL值。 | 否 |
| 数据安全 | RAW_SQL_APPLY_MASKING_RULE | 如果在源表设置了脱敏规则,通过原生SQL数据集、SQL查询等方式取数,如果开启了该项,能正常继承到对应的脱敏规则,从而对数据进行脱敏处理; 系统系统默认false,即不开启(不生效);设置成true,则是开启。 | 否 |
| RAW_SQL_APPLY_ROW_PERMISSIONS | 如果在源表设置了行权限,通过原生SQL数据集、SQL查询等方式取数,并且开启了该设置项,能正常继承到源表的行权限,从而控住数据的泄露; 系统系统默认false,即不开启(不生效);设置成true,则是开启。 | 否 | |
| RAW_SQL_APPLY_ROW_PERMISSIONS_CHECK_TABLE | 如果在源表设置了资源权限(表或列权限),通过原生SQL数据集、SQL查询等方式取数,如果开启了该项,能正常继承到对应的资源权限,从而对数据进行控制; 原生SQL数据集资源权限;系统系统默认false,即不开启(不生效);设置成true,则是开启。 | 否 | |

2.1 扩展包JSP处理器
| 功能说明 | “JSP_PROCESSOR_TYPE”用于加载扩展包时指定JSP的处理器是使用服务器自带,还是产品内书写的。 |
|
|---|---|---|
| 使用场景 | 当同一个扩展包,有的服务器可以加载成功,有的服务器其JSP加载报错。 此时则要考虑加载不成功的服务器是因为使用的JSP处理器有问题。可通过修改JSP处理器的处理方式,如是默认则改为嵌入式。 | |
修改此选项并保存后,需要重启服务器此设置才会生效。 | ||

2.2 网络传输加密算法
| 功能说明 | “NETWORK_TRANSNISSION_ALGORITHM”用于统一设置网络传输数据时,具体采用哪种加密算法。 |
|
|---|---|---|
| 设置说明 |
| |
| 使用方法 | 一般情况下默认使用算法1。 当用户遇到以下情况时,需要测试算法2或算法3,哪个能解决问题就使用对应的算法: 某些用户的服务器存在防火墙策略,导致一些携带了特殊字符的请求被拦截,无法发送请求到smartbi系统。 修改设置项的算法后,WEB端需要刷新页面,移动端需要重新登录,设置项才能生效。 | |

2.3 分析报告最大并发处理线程数
适用场景 | 在打开word分析报告时,避免同时加载其过多的引用资源占用大量内存,导致服务器内存溢出。 |
|
|---|---|---|
功能说明 | 用于设置打开分析报告加载资源方式为串行,或者控制并发运行的最大线程数。 | |
注意事项 | 该设置项会影响分析报告类型:Word分析报告。(PPT分析报告不受影响)。 |

(1)线程数配置说明
输入类型 | 输入内容 | 效果 | 说明 |
|---|---|---|---|
有限制 | 1 | 表示串行方式加载。 | 有助于解决线程同时被占用过多,减轻服务器压力。 |
大于1的整数 | 表示最多同时开启设置线程数,进行并发加载。 | ||
无限制 | OFF | 表示不限制线程数并行加载资源。 | 若分析报告复杂引用过多资源且多人打开情况,可能会出现内存溢出。 |
(2)线程数配置建议
报表情况 | 服务器内存 | 建议配置数 |
|---|---|---|
假设每张分析报告引用50个电子表格, | 16G | 20 |
32G | 40 | |
注意:上表建议仅供参考,实际配置时需要综合考虑分析报告资源引用资源数量、每个引用资源的大小因素。 | ||
2.4 SmartbiMPP
2.4.1 插入数据时自动处理NULL值
| 背景 | SmartbiMPP作为业务库,并支持代替vertica、infobright作为系统的联合数据源使用。 | |
|---|---|---|
| 功能 | “CLICK_HOUSE_AOTU_CONVERT_NULL”可控制Smartbi MPP 插入数据时是否自动处理NULL值。默认为“否”,即不处理NULL值。 | 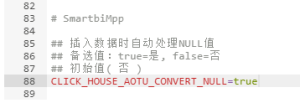 |
| 适用场景 | 一般在回写导入抽取等有NULL值的时候就会报错(如图),此时需要设置配置项的值为“true”,默认处理NULL值。 |
|

2.4.2 抽取目标表备份上限
背景 | 为了避免丢失高速缓存库中历史数据,产品支持备份抽取目标表和数据,方便后续恢复数据,有效提高数据安全。 | |
|---|---|---|
功能 | "BACKUP_TAB_RETAIN_NUM "用于设置在数据抽取中数据库保留的备份表的个数,默认为5个。 备份规则:在抽取数据之前,默认备份抽取表(第一次不备份)到数据库中,每抽取一次进行滚动备份,备份到设置的上限后,下次备份则移除最旧的备份表。
在数据抽取中只要清空抽取表的数据,系统就会自动备份。 | |

2.5 是否开启vertica数据库用ilike代替like,模糊匹配不区分大小写
| 背景 | 在Vertica数据库中,原先是通过修改数据库大小写配置,实现字段条件不区分大小写筛选的效果,但是这样会影响数据库性能。可以使用ILIKE代替LIKE操作符,既能实现效果,也不会影响数据库性能。 |
|---|---|
| 功能说明 | “VERTICA_LIKE_CONVERSION_ILIKE”用于Vertica数据库中能否使用ILIKE代替LIKE操作符,实现在字段条件不区分大小写筛选的效果。 生效范围:自助数据集筛选器条件、自助仪表盘筛选器条件、透视分析的条件面板参数过滤条件、即席查询的条件面板参数过滤条件。
关于连接Vertica数据源,详情请参考 关系数据源-连接Vertica数据源 。 |
| 示例 | 来源于Vertica数据源的透视分析中,想要通过“a”筛选出包含“A”、”a”的值,此时可以设置“VERTICA_LIKE_CONVERSION_ILIKE=true”,效果如下:
|
注意事项 | SQL语句定义LIKE后面的内容不受此设置项的影响。 |


2.6 统一提示信息自定义
| 功能说明 | 通过直接输入所需的文字描述自定义一个统一指引信息作为运行时错误的提示信息。
其中设置项的备选值包括:
|
|---|---|
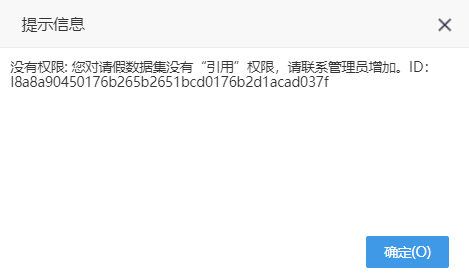
| 示例 | (1)设置“UNIFIED_PROMPT_INFORMATION=false”
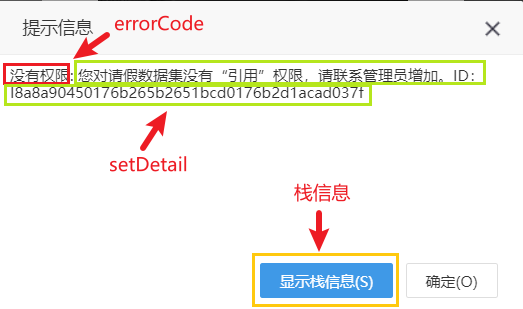
当用户无“错误详情”操作权限,在访问资源没有权限时错误提示如下:
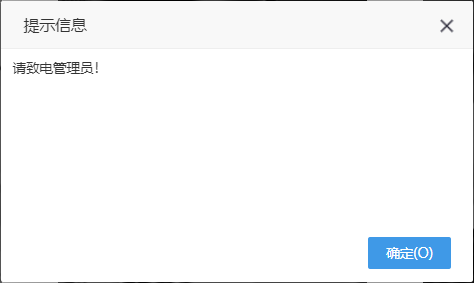
(2)设置“UNIFIED_PROMPT_INFORMATION=请致电管理员!”,当用户无“错误详情”操作权限,在访问资源没有权限时错误提示如下:
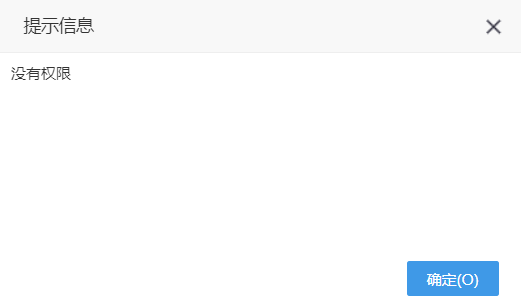
(3)设置“UNIFIED_PROMPT_INFORMATION=NOT_DETAIL”,当用户无“错误详情”操作权限,在访问资源没有权限时错误提示如下:
|
| 注意事项 | (1)该系统设置项对有“错误详情”操作权限的用户不生效,仅对无“错误详情”操作权限的用户生效; (2)统一提示信息自定义的文字描述无长度限制; (3)设置项的“NOT_DETAIL”备选值在V10.5.8及以上版本新增; (4)如果用户没有错误详情的操作权限,针对SQL报错设置false和NOT_DETAIL效果是一样的,只提示errorcode; |


2.6 控制组管理员角色可管理的用户组范围
用于控制组管理员角色可管理的用户组范围。

备选值如下:
| 备选值 | 功能说明 |
|---|---|
| default | 采用系统默认效果。例如: EXTEND_DEPARMENT_AND_USER_CLASS=default; |
| builtin | 组管理员角色只管理默认组下的用户和角色。例如: EXTEND_DEPARMENT_AND_USER_CLASS=default; |
填写扩展包内 自定义的Class全类名 | 当以上备选值的用户组范围无法满足需求,可通过编写扩展包自行定义用户组范围。 例如:EXTEND_DEPARMENT_AND_USER_CLASS=smartbi.usermanager.DefaultExtendDepartmentsAndUser。 定制方法 在扩展包中新建一个类,继承接口“IExtendDepartmentsAndUser”,根据需求进行重写方法 “getDepartmentsOfUser” 和 “isGroupAdminOfRootGroup”。 类示例如下(扩展包示例源码下载): 该示例仅供参考,具体需根据实际情况进行扩展改写。 public class DefaultExtendDepartmentsAndUser implements IExtendDepartmentsAndUser {
// 返回当前用户的默认组
@Override
public List<Group> getDepartmentsOfUser(String userId) {
UserBO userBO = new UserBO(UserDAO.getInstance().load(userId));
List<Group> defaultGroups = new ArrayList<>();
defaultGroups.add(userBO.getDefaultGroup());
return defaultGroups;
}
// 当用户的默认组是根组"DEPARTMENT"时,才能显示并操作根组。不同场景下判断是否拥有根组权限的逻辑都不一样,需根据实际情况改写
@Override
public boolean isGroupAdminOfRootGroup(String userId) {
IDepartment defaultDepartment = UserManagerModule.getInstance().getDefaultDepartment(userId);
if ("DEPARTMENT".equals(defaultDepartment.getId())) {
return true;
}
return false;
}
}
|
2.5 设置电子表格excel插件显示旧资源数据集
| 背景 | 从旧版本升级到V10.5版本,用户如果想继续使用旧版本数据集,可通过此设置项设置。 |
|---|---|
| 功能说明 | “SPREAD_SHEET_EXCELADDIN_REPORT_SHOW_SYSTEMDATASET”用于设置excel插件中是否开启电子表格旧资源数据集,默认为不开启。
设置该设置项等于true,并清空服务器缓存、重启插件。然后在电子表格插件中,数据集面板的数据来源会有“系统数据集”和“报表数据集”两种类型,选择“系统数据集”就可以使用旧版本数据集:
如果选择“报表数据集“则可以创建并使用模型查询、SQL查询。 由于“系统数据集”和“报表数据集”使用的是两种不同方式实现,因此两种类型的数据集之间不能混合使用。 |


2.6 设置WEB电子表格显示旧资源数据集
| 背景 | 从旧版本升级到V10.15版本,用户如果想继续使用旧版本数据集,可通过此设置项设置。 |
|---|---|
| 功能说明 | “WEB_SHEET_SHOW_SYSTEMDATASET=true”用于设置WEB电子表格中是否开启旧资源数据集,默认为不开启。
设置该设置项等于true,并清空服务器缓存,然后在编辑WEB电子表格的界面中,数据集面板的数据来源会有“系统数据集”和“报表数据集”两种类型,选择“系统数据集”就可以使用旧版本数据集:
如果选择“报表数据集“则可以创建并使用模型查询、SQL查询。 由于“系统数据集”和“报表数据集”使用的是两种不同方式实现,因此两种类型的数据集之间不能混合使用。 |




