本节介绍smartbi连接数据挖掘执行引擎集群、服务引擎集群、Spark、Hadoop、Python以及测试服务是否正常运行。
文档环境
集群部署数据挖掘组件环境如下:
| 服务器IP | 主机名 | 组件实例 | 部署目录 |
|---|---|---|---|
| 10.10.35.64 | 10-10-35-64 | 数据挖掘-1,Zookeeper-1,Python-1 | /data |
| 10.10.35.65 | 10-10-35-65 | 数据挖掘-2,Spark-1,Hadoop-1 | /data |
| 10.10.35.66 | 10-10-35-66 | Spark-2,Zookeeper-2,Hadoop-2 | /data |
| 10.10.35.67 | 10-10-35-67 | Spark-3,Zookeeper-3,Hadoop-3,Python-2 | /data |
| 10.10.204.250 | 10-10-204-250 | Smartbi-Proxy | /data |
1、数据挖掘集群高可用测试
1.1 测试执行引擎主备切换
①浏览器访问Smartbi,打开系统运维–数据挖掘配置–引擎设置,引擎地址修改成执行引擎主备节点地址,点击测试,提示平台和引擎双向连通 即可
引擎地址示例:http://执行引擎节点1:8899,执行引擎节点2:8899
Python代理器启动命令示例:./agent-daemon.sh start --master http://执行引擎节点1:8899,执行引擎节点2:8899 --env python

注意事项
执行引擎在部署的时候已经配置好相关的地址,点击测试,可以直接测试连接成功
如果提示“平台到引擎连接成功,引擎到平台连接失败,请检查引擎配置”,请打开系统运维–数据挖掘配置--执行引擎 检查相关配置
②停止执行引擎主节点
登陆到执行引擎主节点服务器,停止执行引擎服务
cd /data/smartbi-mining-engine-bin/engine/sbin/ ./experiment-daemon.sh stop
③检查是否正常
注意事项
执行引擎主备切换可能会需要等待1分钟左右(可能时间更长),并非实时切换,点击测试,提示平台和引擎双向连通,即表示切换完成。
重新打开smartbi 的系统运维–系统选项—引擎设置

1.2测试服务引擎负载均衡
①浏览器访问Smartbi,打开系统运维–数据挖掘配置–引擎设置,配置服务地址修和服务代理地址,并点击保存
配置如下(注意替换成实际地址):
服务地址示例:https://服务引擎节点1:8900,服务引擎节点2:8900
服务地址:https://10.10.35.64:8900
服务代理地址:http://10.10.204.250:8080/smartbi

点击测试,提示平台和服务双向连通,即可

注意事项
服务引擎在部署的时候已经配置好相关的地址,点击测试,可以直接测试连接成功
如果提示“平台到服务连接成功,服务到平台连接失败,请检查服务配置”,请打开系统运维–数据挖掘配置--服务引擎 检查相关配置
②系统监控-服务监控列表可以看到多个服务引擎节点:

③停止服务引擎节点
登陆到服务引擎节点服务器(10-10-35-64),停止服务引擎
cd /data/smartbi-mining-engine-bin/engine/sbin/ ./experiment-daemon.sh stop
④检查是否切换节点
重新打开smartbi 的系统运维–系统选项—引擎设置
2、Spark节点资源配置
打开系统运维–数据挖掘配置–执行引擎--计算节点配置,
注意事项
执行引擎在部署的时候已经配置好Spark相关连接信息,无需重复配置,检查配置即可
配置Spark节点资源,点击一键推荐,系统会根据Spark work节点的服务器资源,生成推荐的配置(如果使用推荐值,记得点击保存,否则配置不生效):

注意事项
执行引擎主备切换后,可以重新点击一键推荐 确保spark节点资源配置正常
3、运行数据挖掘示例
1.测试数据挖掘执行引擎
打开数据挖掘–案例--波士顿房价预测,点击运行,如下图显示运行成功即可
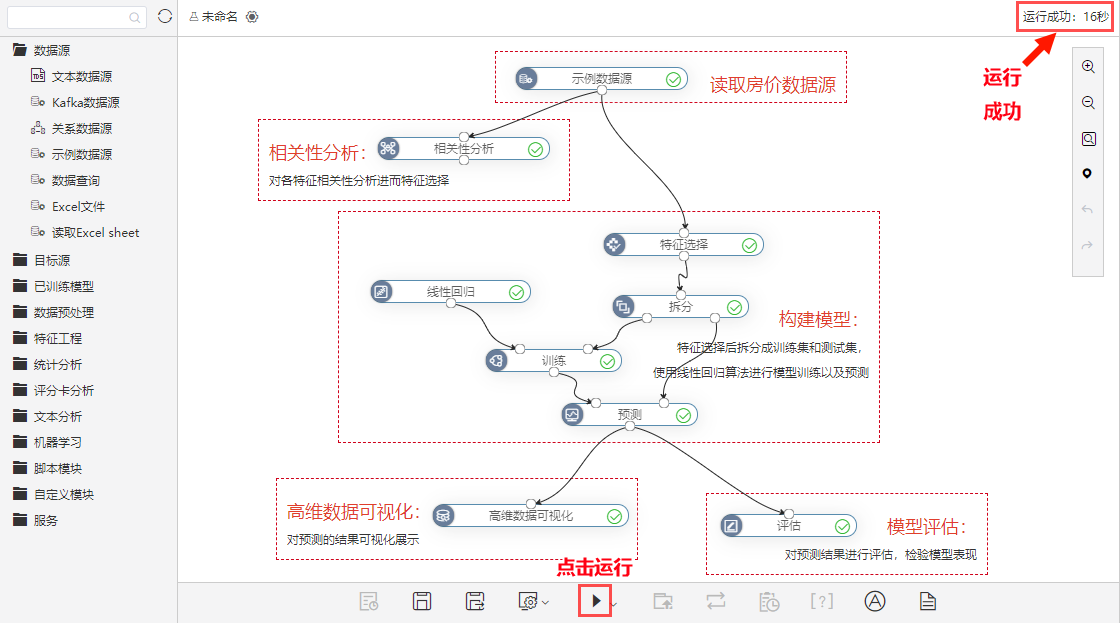
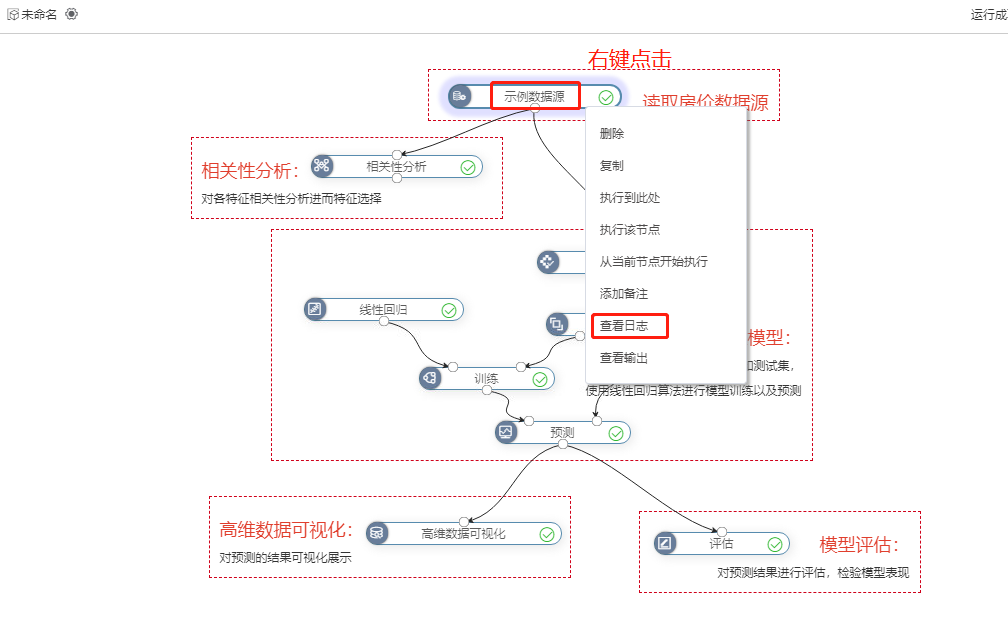
如果某个节点运行失败,可以右键点击节点,选择查看日志分析错误原因:
2.测试数据挖掘服务引擎
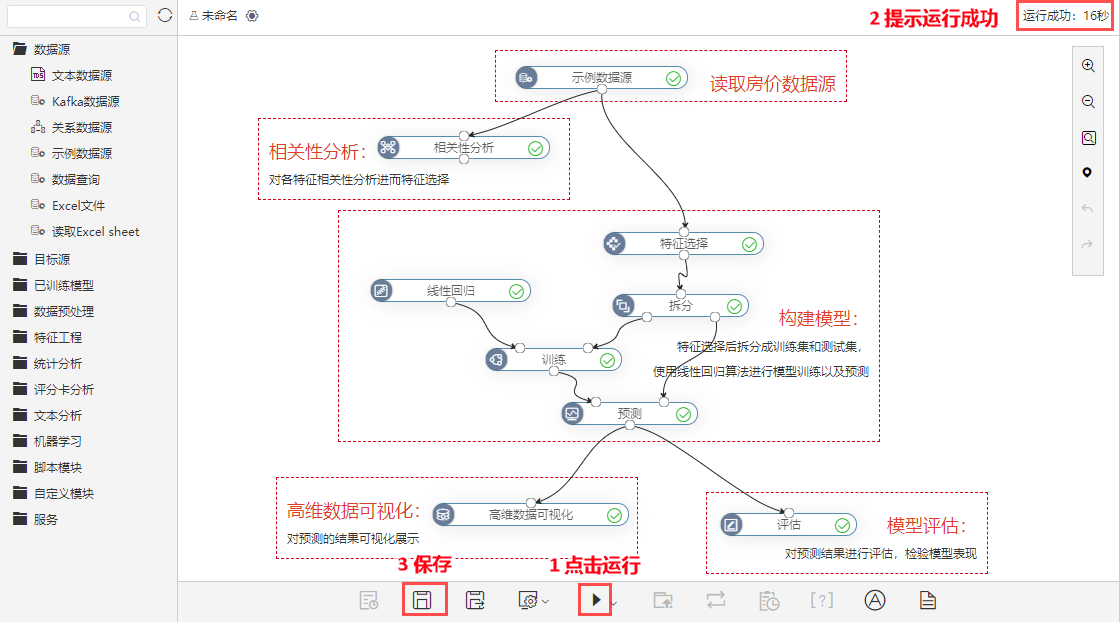
①打开数据挖掘–案例--波士顿房价预测,点击运行,如下图显示运行成功,并点击保存案例
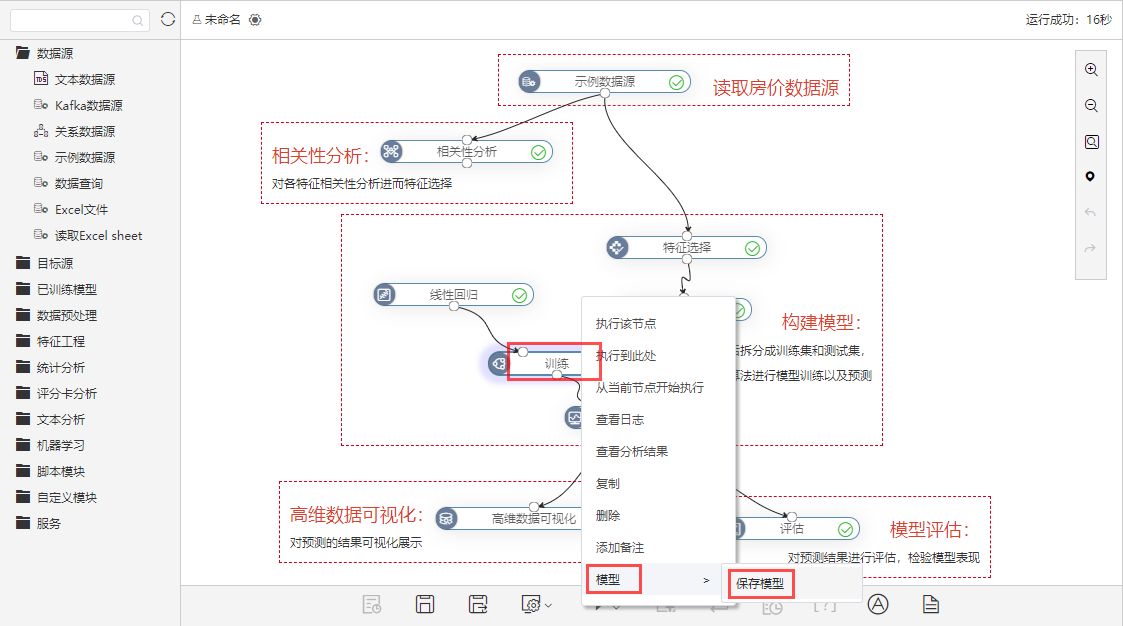
②右键点击 训练--模型--保存模型 ,如下图所示
③保存的的模型可以在左侧导航栏的”已训练模型”中查看。右键删除”线性回归”,”训练”。
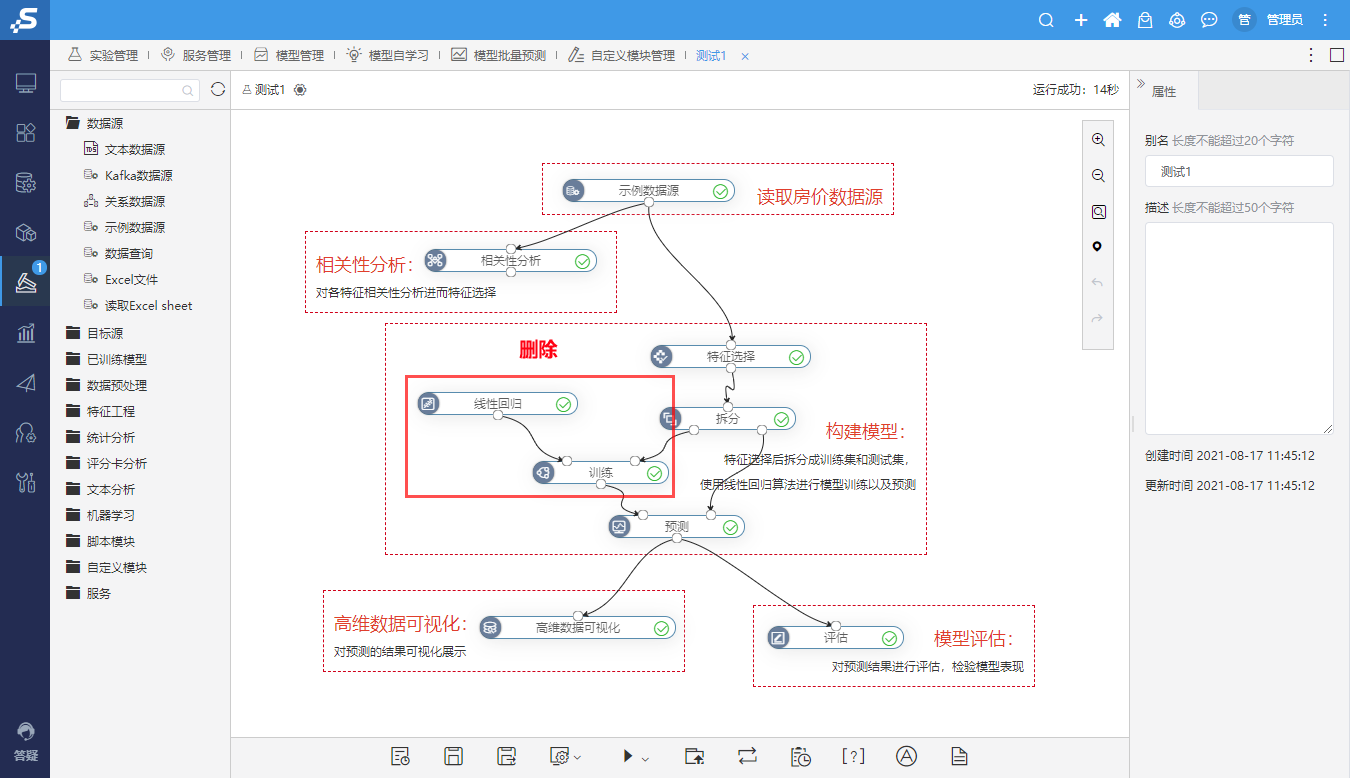
④将保存的模型拖入,并与”预测”连线。
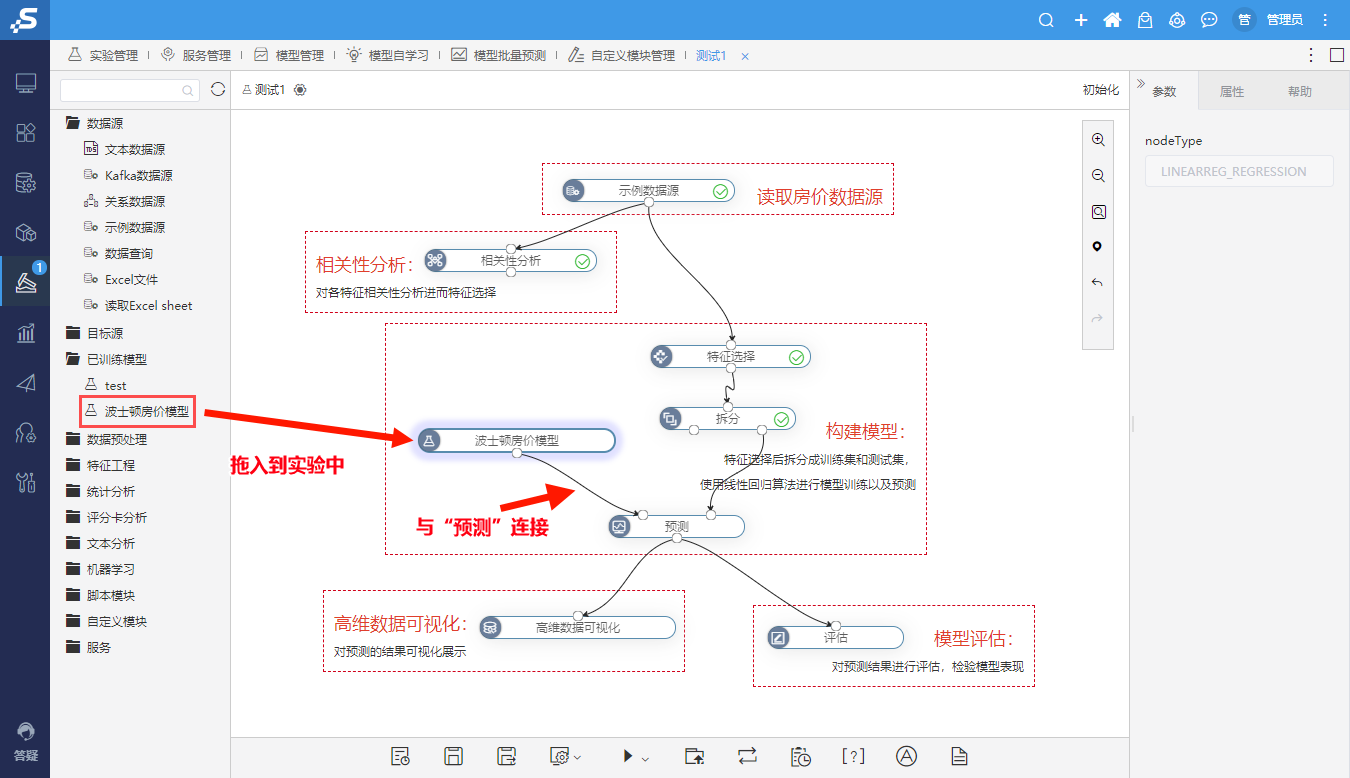
⑤导航栏-服务-拖入 服务输入、服务输出,并连线,运行成功后点击部署服务
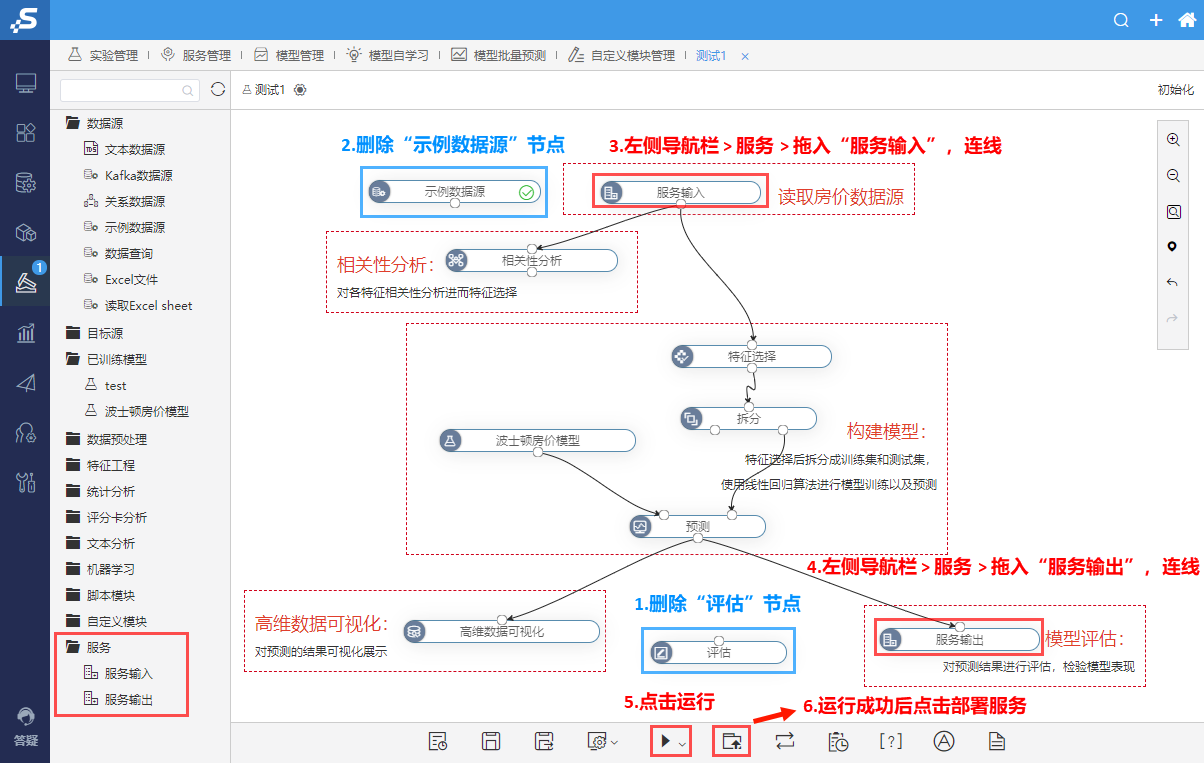
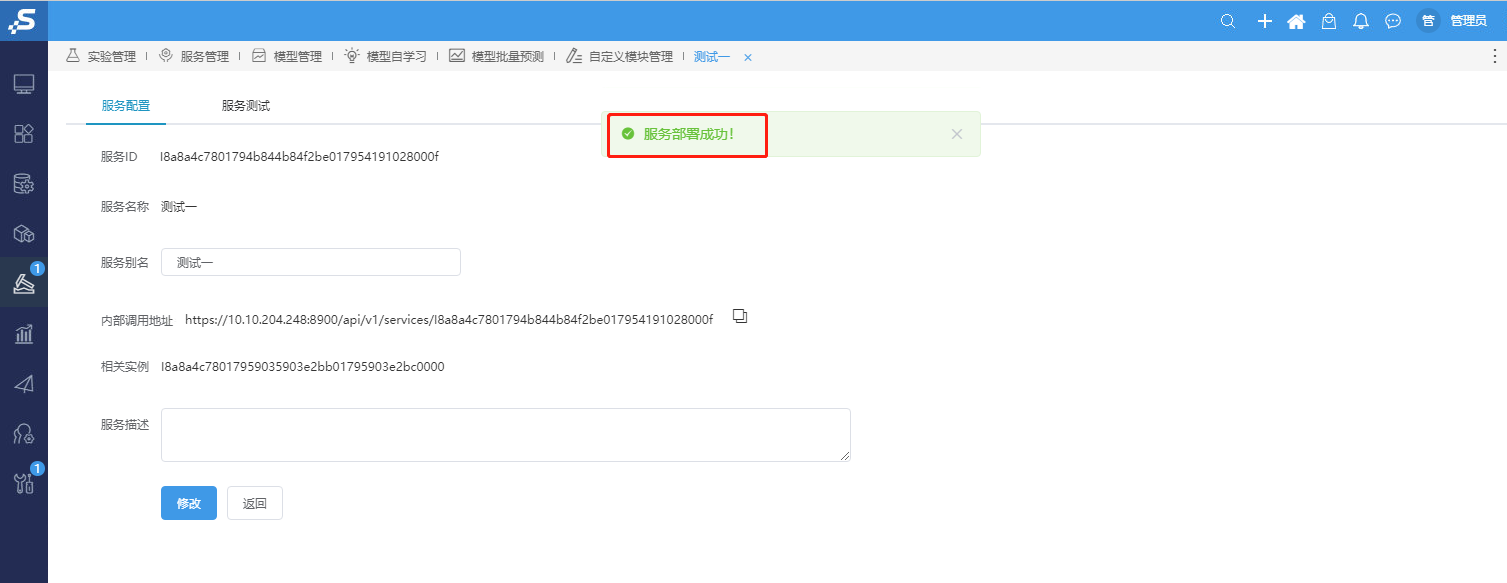
⑥显示部署成功
⑦点击服务测试,会显示测试结果
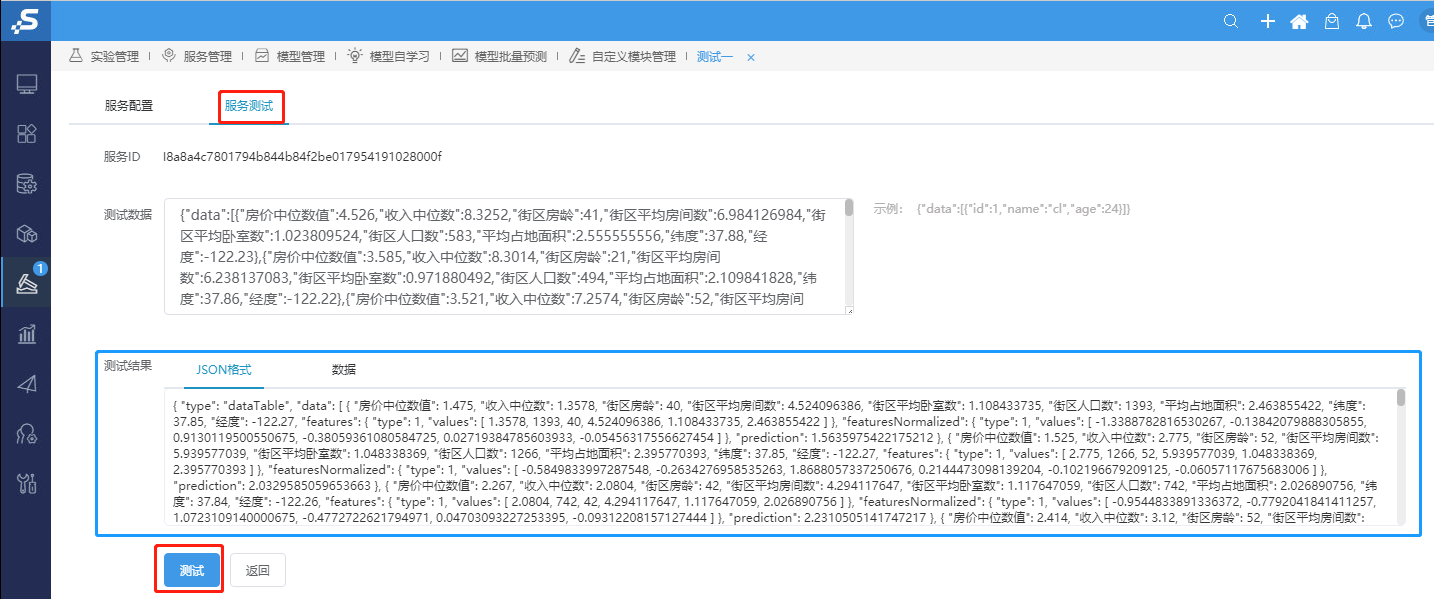
⑧提供外部程序调用的服务地址
登录smartbi,数据挖掘–服务管理,打开部署的服务可查看外部调用服务地址,如下图
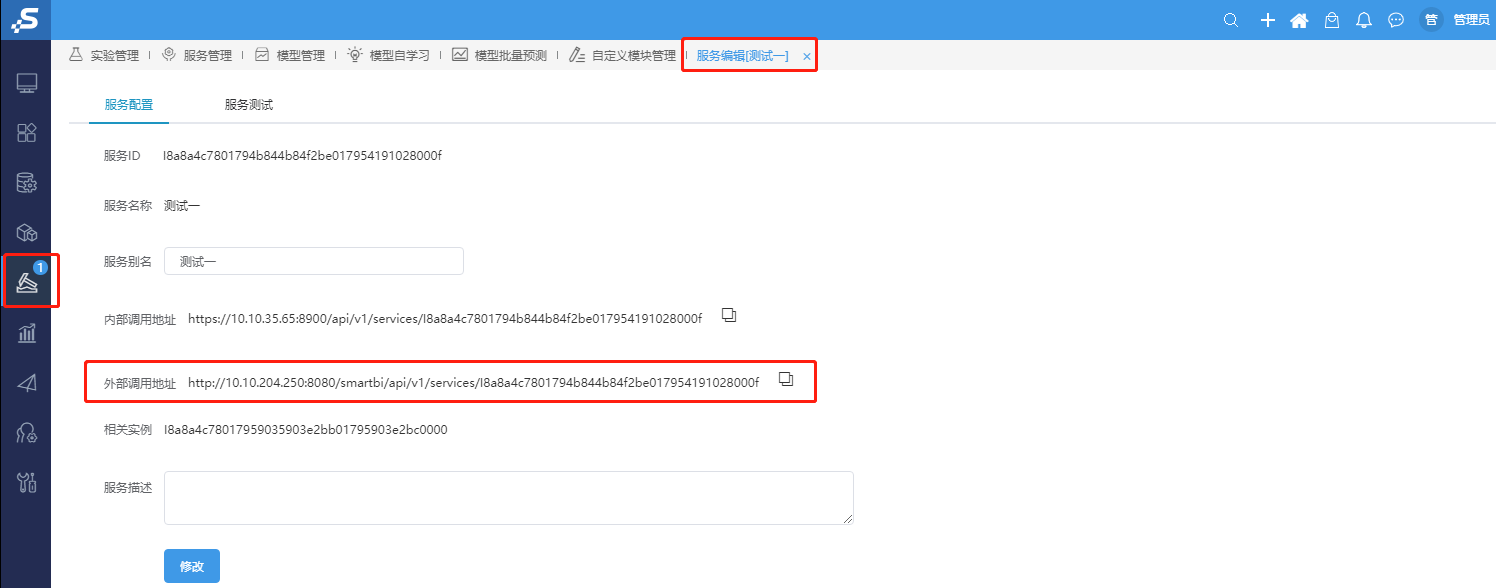
通过外部调用地址来调用服务,即可实现服务引擎的负载均衡
3.测试数据挖掘Python计算
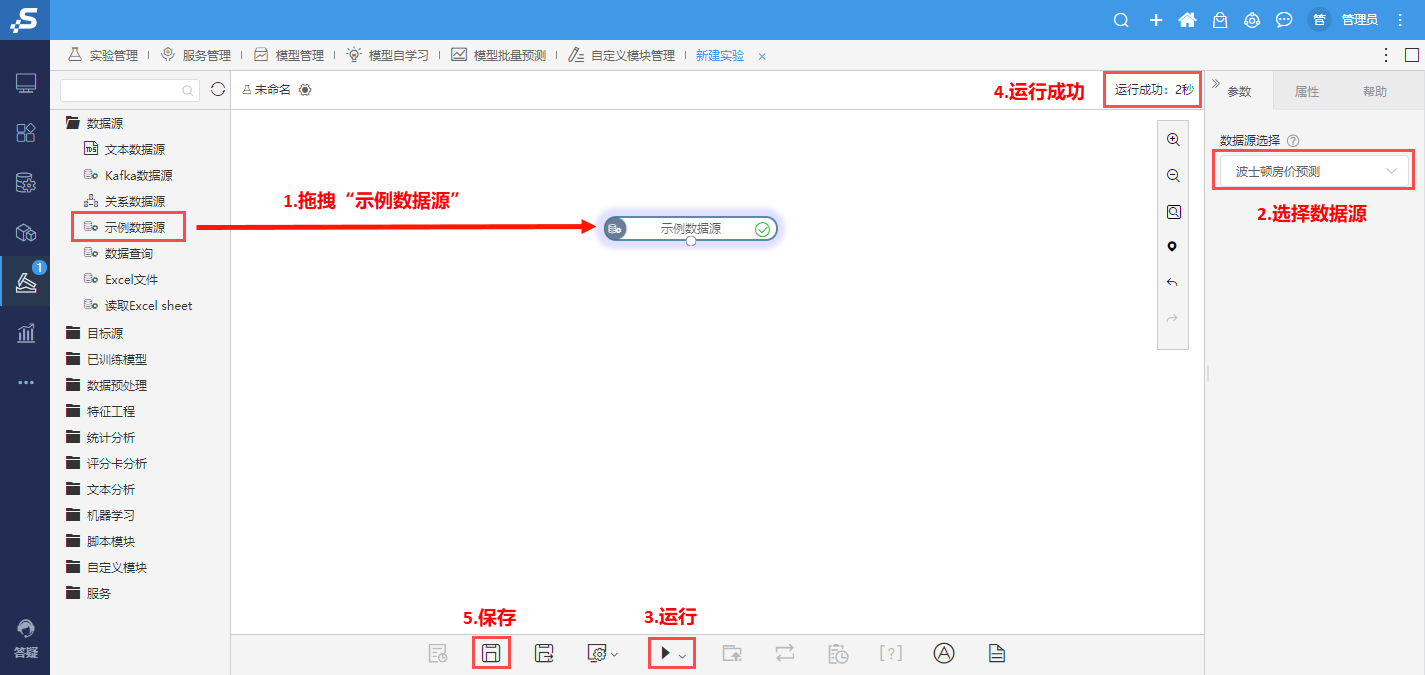
①打开数据挖掘--新建实验

②拖拽“示例数据源”,选择数据源 - 保存 - 运行 - 运行成功--保存
③拖拽PYTHON脚本,与示例数据源连线,点击运行,如果显示运行成功则表示Python计算节点正常
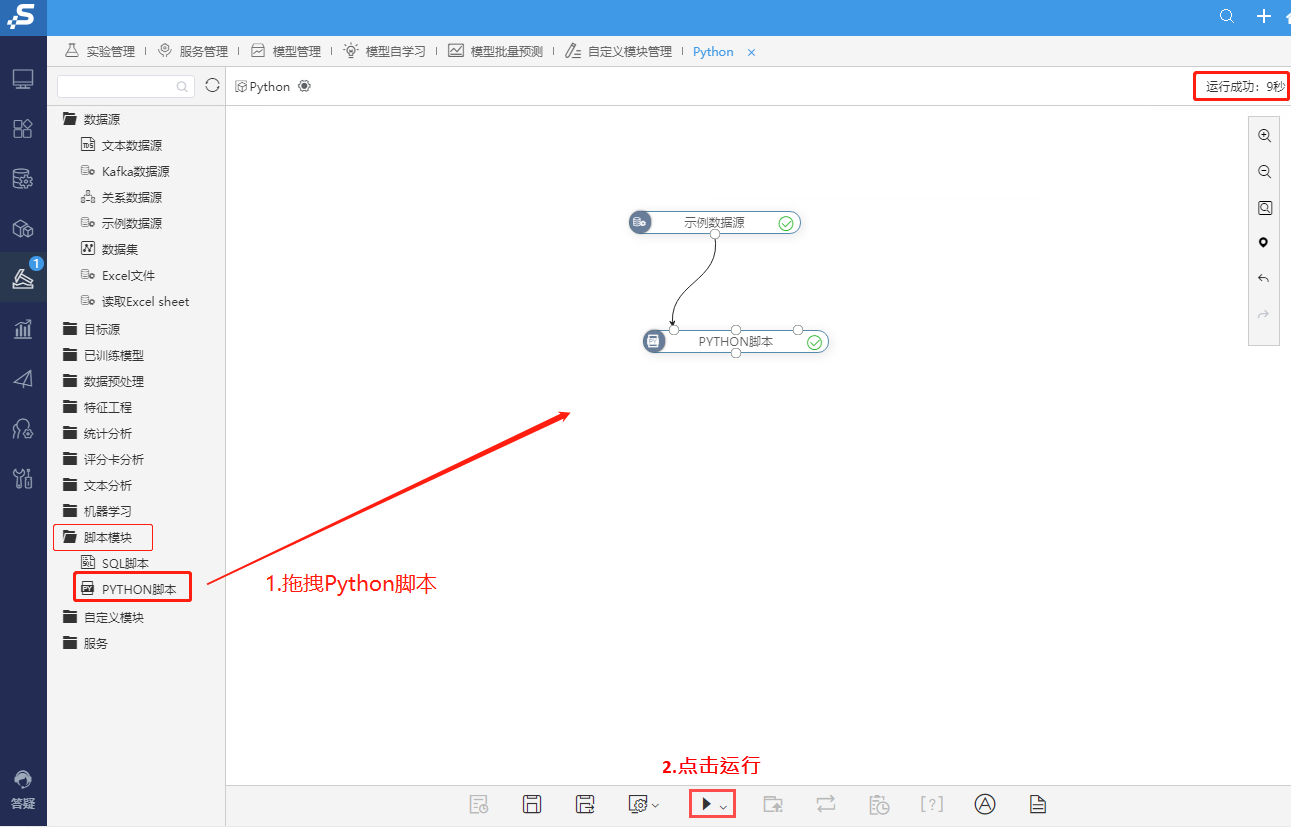
数据挖掘及其组件测试完成。


