1 背景
在当前业务场景中,许多客户的数据规模已达到千万甚至亿级别的庞大体量。如此海量的数据在查询过程中,往往会因数据处理量过大而导致查询速度缓慢,严重影响业务效率与用户体验。
为解决这一问题,Smartbi 产品提供了预聚合表(直连) 的解决方案,通过配置预聚合表可显著提升大数据量下的查询性能。需要注意的是,该功能目前仅支持多维引擎的聚合表,SQL 引擎暂未适配。
1.1 前提条件
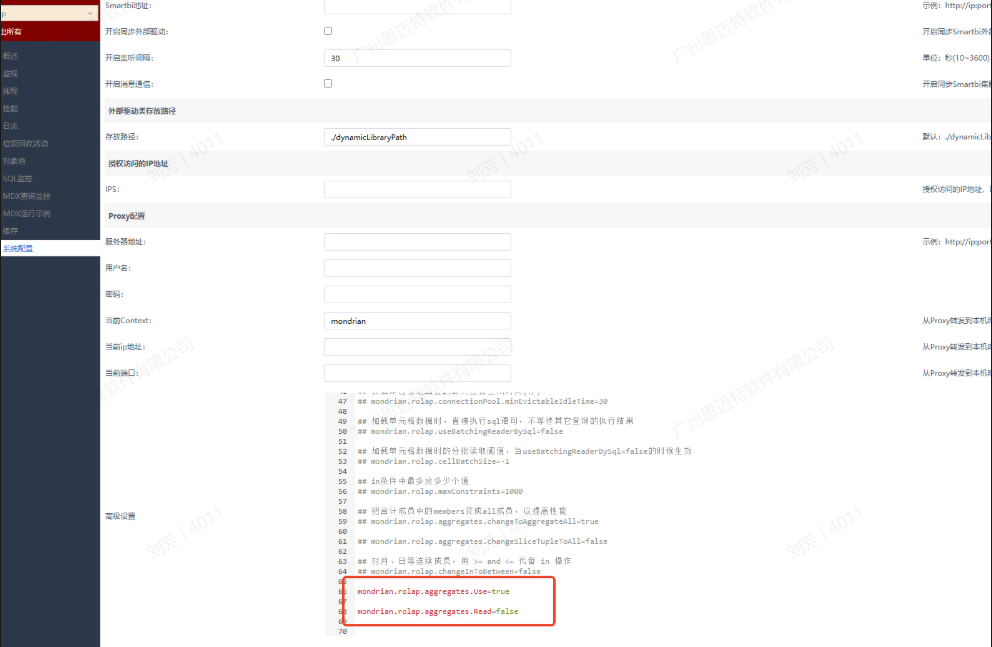
1、需要在系统运维/公共设置/高级系统选项设置:CONFIG_CENTER_SHOW_ENABLE=true。
2、在多维引擎中配置olap配置项:mondrian.rolap.aggregates.Use=true、mondrian.rolap.aggregates.Read=false。
2 示例说明
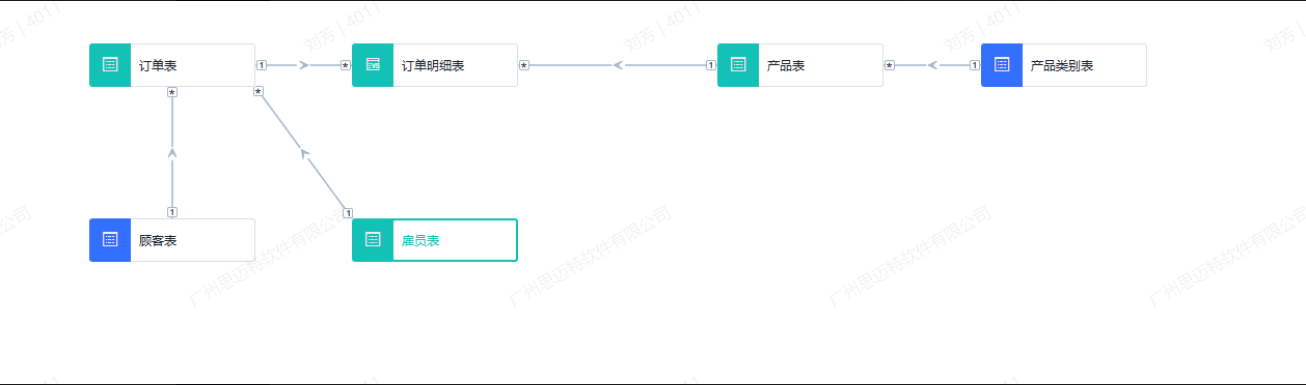
以产品内置的“订单模型”为例,如下图所示:
基于这个模型创建报表,如下图,为了更好的说明,加了很多维度进行查询),假设它的性能很慢,需要2-3分钟才能打开,现在我们要对其进行性能优化:

具体操作步骤
1、在对应的数据源上建预聚合表,表结构如下, 表中的数据,需根据业务要求插入(需要注意看下面对字段注释说明):
CREATE TABLE agg_1_orderdetails(
CategoryName VARCHAR(255),
ProductName VARCHAR(255),
OrderDate_Year VARCHAR(255),
OrderDate_Month VARCHAR(255),
ShipRegion VARCHAR(255),
ShipProvince VARCHAR(255),
ShipCity VARCHAR(255),
Discount double,
Quantity long,
UnitPrice DECIMAL(10,4),
viewName VARCHAR(255), // 事实表的真名
fact_count INT // 这个是必填的,olap要求一定要
);
3、配置预聚合表
界面路径:在系统监控>配置中心:
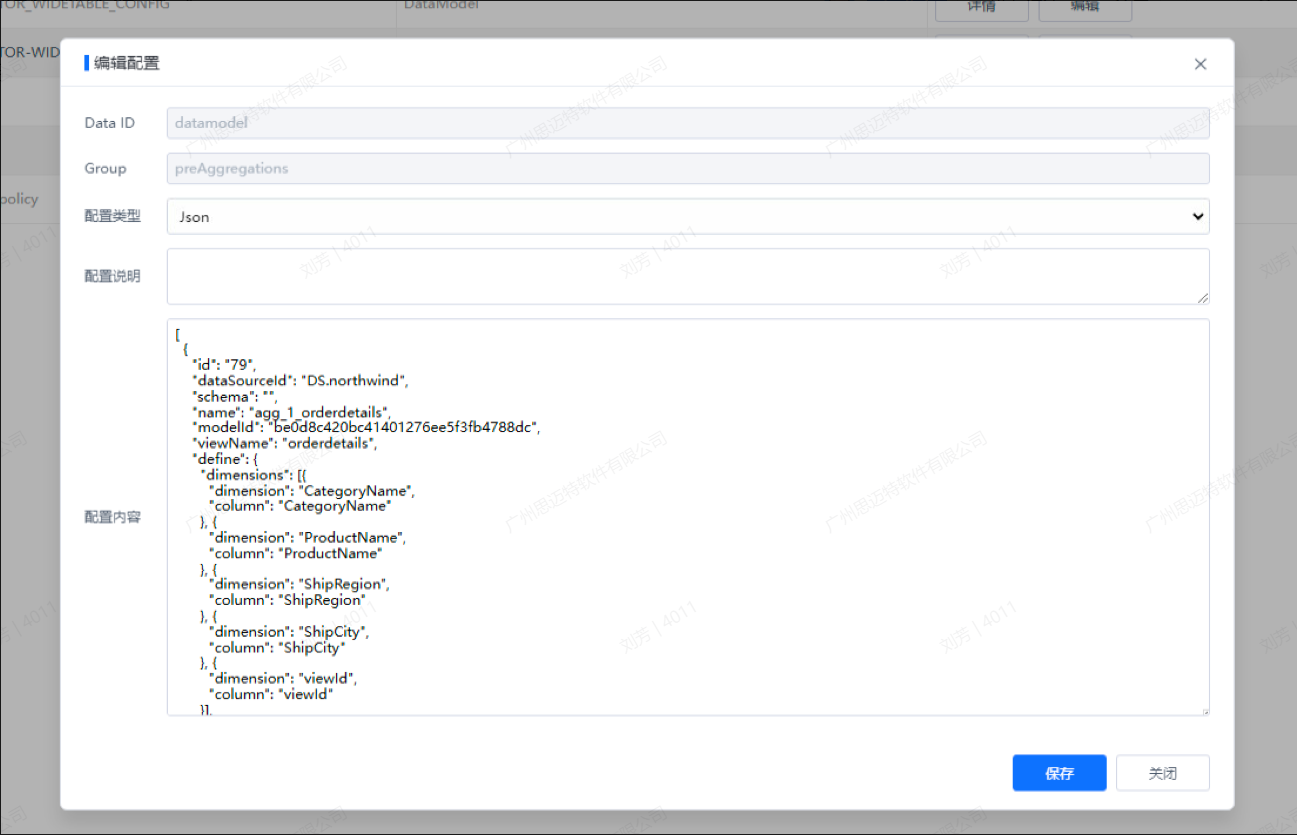
选项说明:
| 选项 | 选项值 |
|---|---|
| Data ID | 必填,datamodel(只能填写这个) |
| Group | 必填,PreAggregations(只能填写这个) |
| 配置类型 | Json, 一定是json |
| 配置说明 | 非必填 |
| 配置内容 | 需要遵循这个格式定义, 需要注意看下面对字段注释说明: |
配置好之后,重启一下BI。
4、重新查询报表,可以看到它的速度变快了,因为直接命中了聚合表的数据。
5、创建新报表,勾选预聚合用到的字段 ShipRegion,ShipCity,Discount

在系统监控中,查看运行的Schema信息:

在多维引擎监控中查看MDX生产的sql语句如果查询的是上面定义的预聚合表,那么说明命中了预聚合,否则没有命中:



