1、字符串判断
函数 | 描述 | |
|---|---|---|
| 1 | coalesce(expr1, expr2, ...) :空值处理 | 函数说明:返回第一个非空参数,类似ifnull(expr1, expr2),可以设置多个表达式 示例:如果处理部门为空,则填充发起部门。
|
| 2 | nullif(expr1, expr2) :等值判定为空 | 函数说明:如果expr1等于expr2,则返回null,否则返回expr1; 示例: > SELECT nullif(2, 2); NULL |
| 3 | nvl(expr1, expr2) :空值处理 | 函数说明:如果为null,则返回值;支持2个表达式 示例:如果处理部门为空,则填充发起部门。
|
| 4 | nvl2(expr1, expr2, expr3) :空值处理 | 函数说明:如果不为null,则返回值,支持3个表达式 示例: > SELECT nvl2(NULL, 2, 1); 1 |
| 5 | endswith(left, right) :结尾判断 | 函数说明:返回布尔值。如果从左往右,以右侧字符串结尾,则该值为True。如果任一输入表达式为NULL,则返回NULL。否则,返回False。左边或右边都必须是STRING或BINARY类型。 示例: > SELECT endswith('Spark SQL', 'SQL');
true
> SELECT endswith('Spark SQL', 'Spark');
false
|


2、字符串拼接
函数 | 描述 | |
|---|---|---|
| 1 | concat(col1, col2, ..., colN) :拼接字符串 | 函数说明:连接字符串col1, col2, ..., colN 示例: > SELECT concat('Spark', 'SQL');
SparkSQL
|
| 2 | concat_ws(sep,[column2],…,[columnN]) | 函数说明: concat_ws(“sep”,[column2],…,[columnN]):返回这N列拼接的带分隔符的字符串。 concat_ws(“sep”, str1, str2,…, strN):返回这N个字符串拼接后的字符串。
示例: >SELECT concat_ws(' ', 'Spark', 'SQL');
Spark SQL
|
3、字符串长度
函数 | 描述 | |
|---|---|---|
| 1 | length(expr) :字符串长度 | 函数说明:返回字符串的长度 示例: > SELECT length('Spark SQL ');
10
> SELECT length(x'537061726b2053514c');
9
|
| 2 | CHAR_LENGTH(expr) :字符串长度 | 函数说明:返回字符串的长度 示例: > SELECT CHAR_LENGTH('Spark SQL ');
10
|
| 3 | CHARACTER_LENGTH(expr) :字符串长度 | 函数说明:返回字符串的长度 示例: > SELECT CHARACTER_LENGTH('Spark SQL ');
10
|
4、字符串查找、截取
函数 | 描述 | |
|---|---|---|
| 1 | instr(str, substr) | 函数说明:返回从1开始的字符出现索引 示例: > SELECT instr('SparkSQL', 'SQL');
6
|
| 2 | left(str, len) | 函数说明:返回第一个 n 字符 示例: > SELECT left('Spark SQL', 3);
Spa
> SELECT left(encode('Spark SQL', 'utf-8'), 3);
Spa
|
| 3 | locate, position | 函数说明:返回子字符串第一次出现的位置 示例: > SELECT locate('bar', 'foobarbar');
4
> SELECT locate('bar', 'foobarbar', 5);
7
> SELECT POSITION('bar' IN 'foobarbar');
4
|
| 4 | parse_url | 函数说明:提取URL的一部分 示例: > SELECT parse_url('http://spark.apache.org/path?query=1', 'HOST');
spark.apache.org
> SELECT parse_url('http://spark.apache.org/path?query=1', 'QUERY');
query=1
> SELECT parse_url('http://spark.apache.org/path?query=1', 'QUERY', 'query');
1
|
| 5 | repeat | 函数说明:返回将给定字符串值重复n次的字符串。 示例: > SELECT repeat('123', 2);
123123
|
| 6 | substring(str, pos[, len]) substr(str, pos[, len]) | 函数说明:返回str从pos开始、长度为len的子字符串,或字节数组从pos结束、长度为len的切片。 示例: > SELECT substr('Spark SQL', 5);
k SQL
> SELECT substr('Spark SQL', -3);
SQL
> SELECT substr('Spark SQL', 5, 1);
k
> SELECT substr('Spark SQL' FROM 5);
k SQL
> SELECT substr('Spark SQL' FROM -3);
SQL
> SELECT substr('Spark SQL' FROM 5 FOR 1);
k
> SELECT substr(encode('Spark SQL', 'utf-8'), 5);
k SQL
|
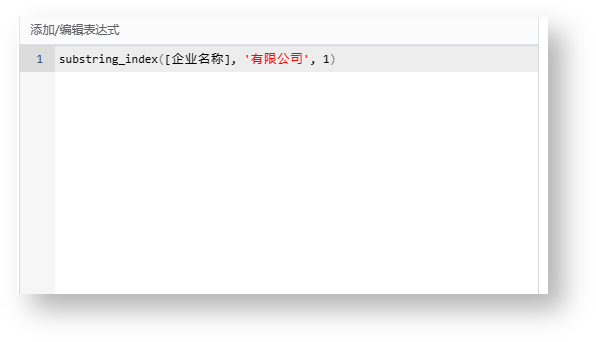
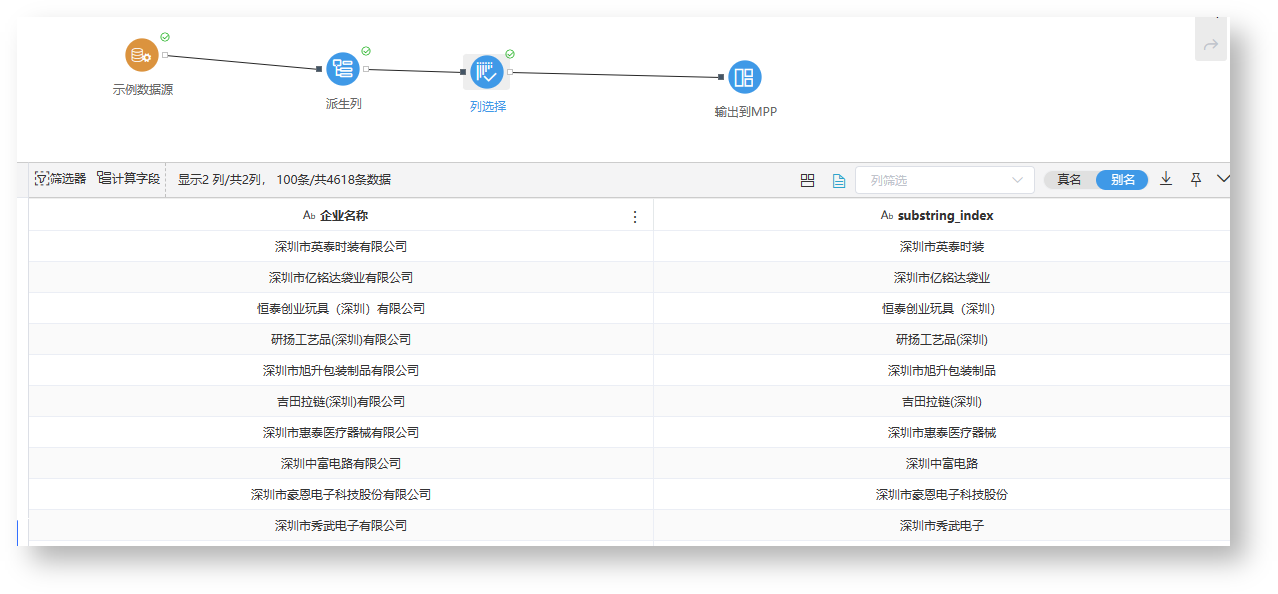
| 7 | substring_index(str,delim,count) | 函数说明:返回子字符串的索引。substring_index(str,delim,count),str:要处理的字符串;delim:分隔符;count:计数 示例:substring_index([企业名称], '有限公司', 1)
|
| 8 | split(str, regex, limit) | 函数说明:拆分字符串。在匹配regex的出现处拆分str,并返回长度最多为limit的数组 示例:split(str, regex, limit)
> SELECT split('oneAtwoBthreeC', '[ABC]');
["one","two","three",""]
> SELECT split('oneAtwoBthreeC', '[ABC]', -1);
["one","two","three",""]
> SELECT split('oneAtwoBthreeC', '[ABC]', 2);
["one","twoBthreeC"]
|
5、字符串替换
spark sql 正则通配符请参考:spark的正则 sparksql正则匹配_mob6454cc6b413f的技术博客_51CTO博客
函数 | 描述 | |
|---|---|---|
| 1 | regexp_extract(str, regexp, idx) | 函数说明:提取与正则表达式匹配的内容,将字符串按照指定规则拆分为组后,返回指定组的字符串。 str:是待拆分的字符串 regexp:是常量或正则表达式 idx:是数组里要的下标值 示例 > SELECT regexp_extract('100-200', '(\\d+)-(\\d+)', 1);
100
> SELECT REGEXP_EXTRACT('8d99d8', '8d(\\d+)d8', 1);
99
|
| 2 | regexp_replace(strA,strB,strC ) | 函数说明:返回替换匹配正则表达式的内容 将字符串A中的符合java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符,类似oracle中的regexp_replace函数 示例 > SELECT regexp_replace('100-200', '(\\d+)', 'num');
num-num
|
| 3 | replace(str, search, replace) | 函数说明:替换字符串的所有实例 示例 > SELECT replace('ABCabc', 'abc', 'DEF');
ABCDEF
|
| 4 | translate(input, from, to) | 函数说明:替换字符串中的值。通过将[from]中的字符串中的字符替换为[to]中的字符串中的相应字符来翻译[input]字符串。 示例 > SELECT translate('AaBbCc', 'abc', '123');
A1B2C3
> SELECT translate("2.10.100.103.3","2.10","");
33
|


6、字符串补位
函数 | 描述 | |
|---|---|---|
| 1 | initcap(str) | 函数说明:将字符串更改为标题大小写 |
| 2 | lcase(str), lower(str) | 函数说明:将字符串更改为全部小写 |
| 3 | lpad(str) | 函数说明:垫住字符串的左侧 |
| 4 | rpad(str) | 函数说明:将字符串的右侧填充 |
| 5 | rtrim(str) | 函数说明:删除尾随空格 |
| 6 | trim(str) | 函数说明:删除前导字符和尾随字符 |
| 7 | ucase(str), upper(str) | 函数说明:将字符串更改为全部大写 |


