V10版本数据准备的改进点如下:
+【数据准备】新增增强数据集,将所有查询结果归集并基于CUBE重新构建数据结构
背景介绍
随着市场竞争的日趋激烈,企业的决策更加强调及时性和准确性,越来越多的用户需要多维度、更加灵活的方式观察数据变化,以获得对数据更加深入的了解,从而更好的促进企业的发展。为了满足用户的需求,新版本产品新增增强数据集,可实现将所有查询结果归集后,基于CUBE模型重新构建数据结构。CUBE模型主要以“维度”和“度量”进行构建,同时增加了“成员”和“命名集”的创建,实现了增强数据集构建的灵活性及应用广泛性。
功能概述
新版本在 数据准备>数据集 中,新增“增强数据集”类型。

包含了以下功能:
私有查询
增强数据集可实现将所有数据集作为私有查询结果归集。
支持数据来源有:数据源表、数据文件、SQL查询、即席查询、脚本查询、存储过程查询和ETL高级查询。

重构数据结构
增强数据集基于CUBE模型重新构建了数据结构,CUBE模型主要以“维度”和“度量”进行构建,支持使用MDX表达式创建计算度量、计算成员、命名集。

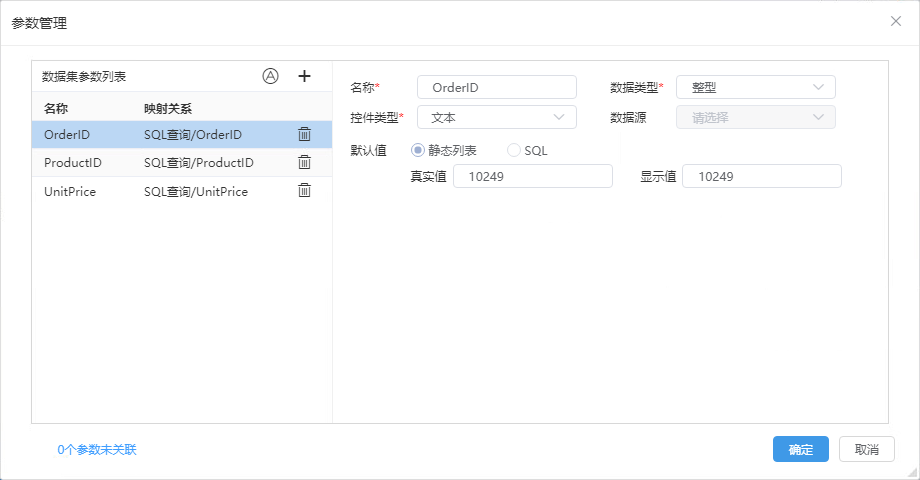
参数及参数管理
增强数据集支持设置每个私有查询的参数,可对整个数据集包含的参数进行管理。
应用于报表
增强数据集作为数据来源,可用于定制自助仪表盘和电子表格。

参考文档
关于增强数据集的功能,详情请参考 数据模型 。
+【数据准备】自助ETL新增Python脚本节点
背景介绍
随着大数据时代的到来,Python已经在数据处理、数据可视化、机器学习等领域受到广泛应用。V10版本的ETL功能支持用户编写Python脚本,利用其丰富的科学计算扩展库,满足更多数据处理和分析场景,提高生产效率。
功能概述
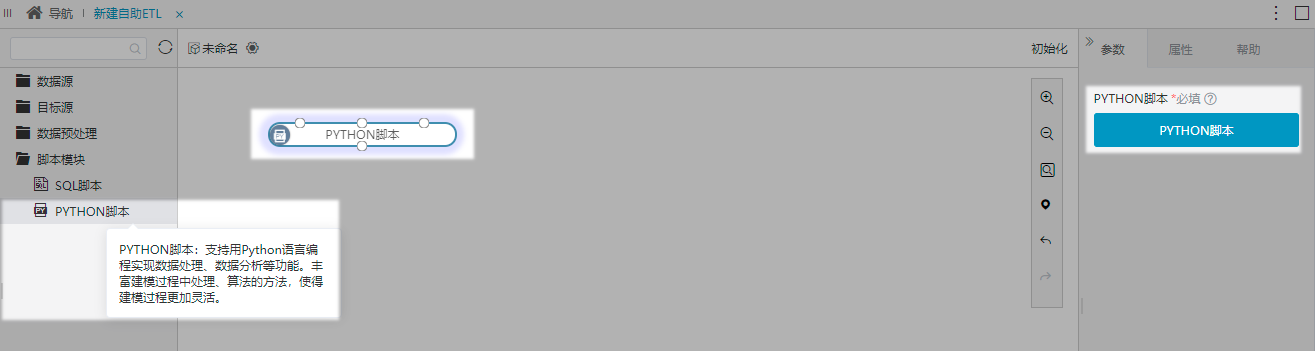
Python脚本节点,支持用户编写Python代码,以便实现更自由、更高效的数据处理、数据分析操作,丰富了数据建模过程。
参考文档
关于Python脚本的功能,详情请参考 Python脚本 。
+【数据准备】新增作业流功能,实现多ETL实验之间执行依赖关系
背景介绍
在数据准备中,从原始数据到最终展现数据需要经过多个ETL实验处理,这些ETL实验的执行调度存在着依赖关系,也就是多个ETL实验需要按照指定的顺序和条件调度执行。新版本,产品在自助ETL中新增作业流功能,是一个轻量级的调度功能,多个ETL实验可按照指定的顺序和条件调度执行,实现了多ETL之间执行依赖关系。
功能简介
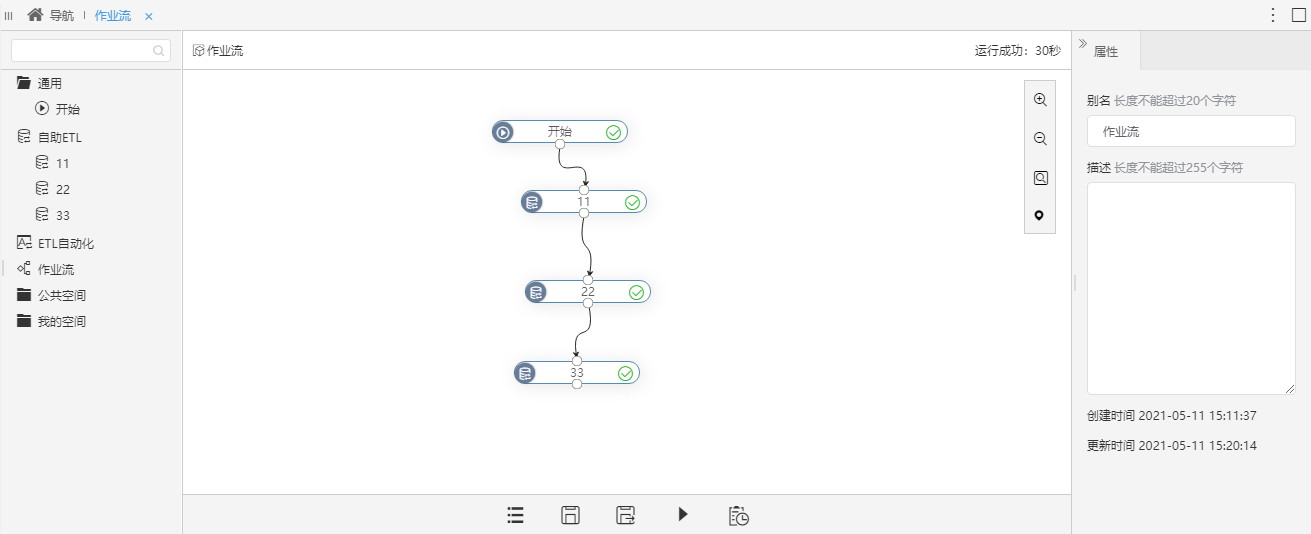
新版本,产品在自助ETL中新增作业流功能,可将自助ETL、作业流实验当做作业执行。
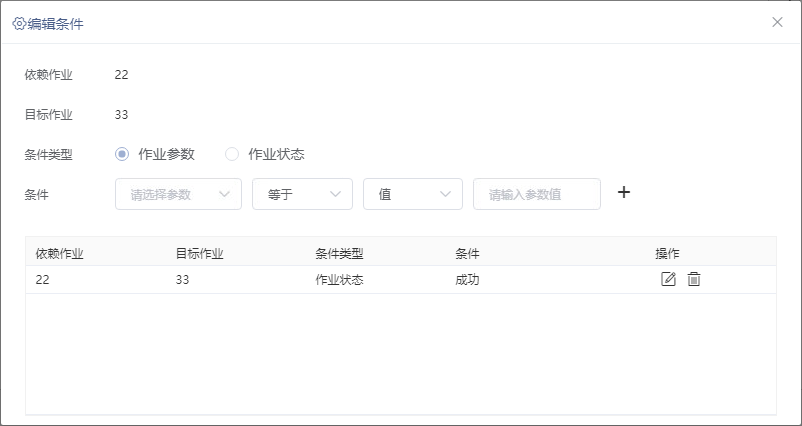
并支持设置分支条件,作业只有满足设置的条件才会继续执行。
系统运维人员可通过作业流监控,对作业流的运行情况进行监控。
参考文档
关于作业流的功能,详情请参考 作业流 。


