数据挖掘引擎V95到Beta版本升级内容如下:
| 数据挖掘组件 | V95版本 | Beta版本V10版本 | 更新内容 | 备注 |
|---|
| 实验引擎 | √ | √ | 数据挖掘引擎版本更新 |
|
| 服务引擎 | √ | √ | 数据挖掘引擎版本更新 |
|
| Spark | √ | √ | Spark版本由2.4升级到3.0版本 | 需要使用Smartbi提供的安装包 |
| Python执行节点 | √ | √ | 数据挖掘引擎版本更新,新增代理程序启动用户。 |
|
| Hadoop | × | √ | 新增Hadoop组件,用于节点中间数据存储。 | 需要使用Smartbi提供的安装包 |
数据挖掘引擎包更新
获取新版本的数据挖掘引擎安装包。
新数据挖掘引擎安装包解压缩后;
先备份<数据挖掘安装目录>/engine目录;
再删除<数据挖掘安装目录>/engine目录,然后上传新的engine目录,并重启数据挖掘引擎。
数据挖掘引擎安装包版本要和smartbi的war包版本一致,更新时需要同步更新Python节点中的引擎包。
Spark版本升级
1、停止spark1、Spark版本升级
| 注意 |
|---|
|
需要使用Smartbi提供的Spark3.0安装包部署 |
1. 停止旧版本Spark
进入spark安装目录,执行命令停止spark2.4服务
| 代码块 |
|---|
|
cd /data/spark-2.4.0-bin-hadoop2.7/sbin/ #注意进入实际spark部署目录
./stop-all.sh
|
2、安装spark32.
0上传新的spark3.0安装包到服务器,并解压到指定目录(安装目录可自定义)配置系统免密登陆
登陆服务器,生成密钥
| 代码块 |
|---|
| linenumberslanguage | truebash |
|---|
|
tar -zxvf spark-3.0.0-bin-hadoop2.7.tgz -C /opt
|
3、配置spark3.0
| 代码块 |
|---|
|
cd /opt/spark-3.0.0-bin-hadoop2.7/conf
cp spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.conf |
在配置文件末尾添加以下内容,保存
| 代码块 |
|---|
|
spark.authenticate true
spark.authenticate.secret kW9y@5yheyJ&IMlD41Dlv#lHFKi7fg7# |
 Image Removed
Image Removed
| 注意 |
|---|
|
其中 kW9y@5yheyJ&IMlD41Dlv#lHFKi7fg7# 是默认spark认证密钥, 支持更改成自定义的字符串(大小写英文字母+数字+英文符号构成)。
如不使用默认值,需要在部署实验引擎时, experiment-application.properties文件修改配置项(如果没有该配置项则需要添加)。
spark.authenticate.secret=你修改的密钥 |
4.启动Spark3.0
①启动Spark master
输入ssh-keygen后,连续按三次回车,不用输入其它信息。
复制公钥到文件中:
| 代码块 |
|---|
|
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys |
测试是否设置成功
示例:
| 代码块 |
|---|
|
ssh root@10-10-204-249 |
如果不用输入密码,表示配置成功
3.安装Spark
解压Spark到指定目录
| 代码块 |
|---|
|
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /data |
启动Spark
| 代码块 |
|---|
|
cd /data/spark-3.0.0-bin-hadoop2hadoop3.72/sbin
./start-masterall.sh -h 主机名 |
例如:主机名为smartbi-spark,则执行:
| 代码块 |
|---|
|
./start-master.sh -h smartbi-spark |
②启动Spark work
注意:参数 -c 为分配给spark work 节点的cpu核数,-m 为分配给spark work节点内存值
4. 检查Spark
在浏览器中输入:http://master节点的ip:8080,查看集群状态
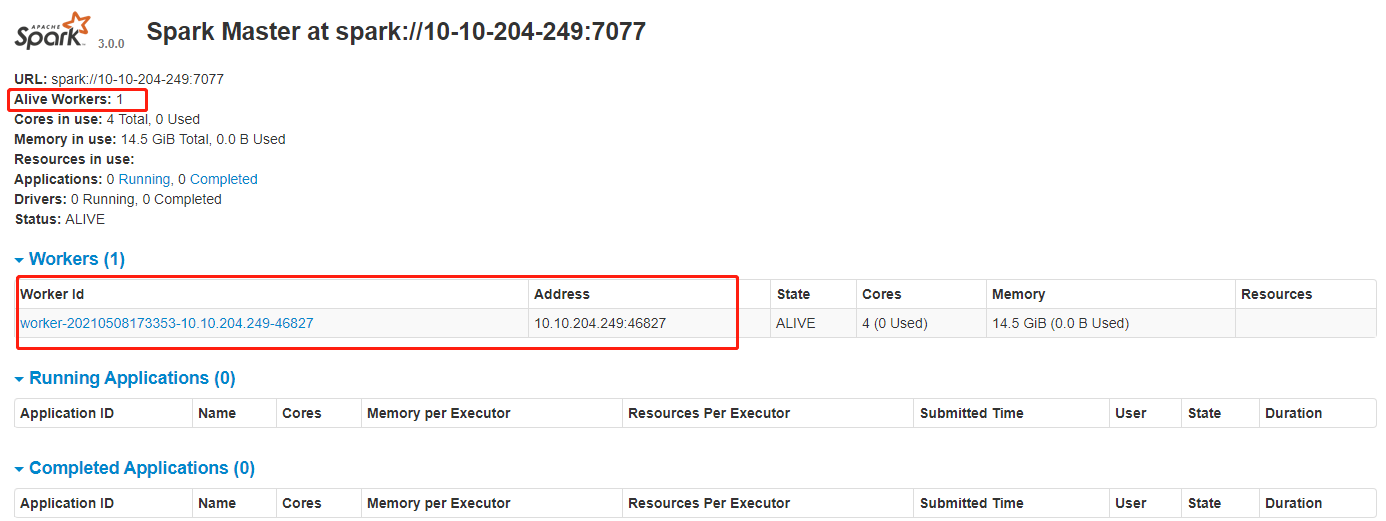 Image Added
Image Added
在spark节点提交任务测试进入/data/spark-3.0.0-bin-
hadoop2hadoop3.
7/sbin
./start-slave.sh spark://master节点的主机名:7077 -c 配置的cpu数 -m xg 配置的内存数(g为单位)| 注意 |
|---|
Work 节点最低配置为 1 核 8G 内存。 cpu 和内存比值建议为 1:8 ,即一个 cpu 配置 8G 的内存 |
例如:worker节点为8核,64G内存的配置,master的主机名为smartbi-spark,2核16G留给系统跟hadoop,剩下的资源留给spark。则执行:
| 代码块 |
|---|
|
./start-slave.sh spark://smartbi-spark:7077 -c 6 -m 48g |
5.检查Spark
在浏览器中输入:http://master节点的ip:8080,查看集群状态
 Image Removed
Image Removed
在master节点提交任务,执行以下命令(注意将”节点的IP”替换对应的IP或主机名)
| 代码块 |
|---|
|
cd /opt2/bin目录,执行以下命令(注意将”节点IP”替换对应的IP或主机名)
| 代码块 |
|---|
./spark-submit --class org.apache.spark.examples.SparkPi --master spark://节点IP:7077 /data/spark-3.0.0-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.0.0.jar 100 |
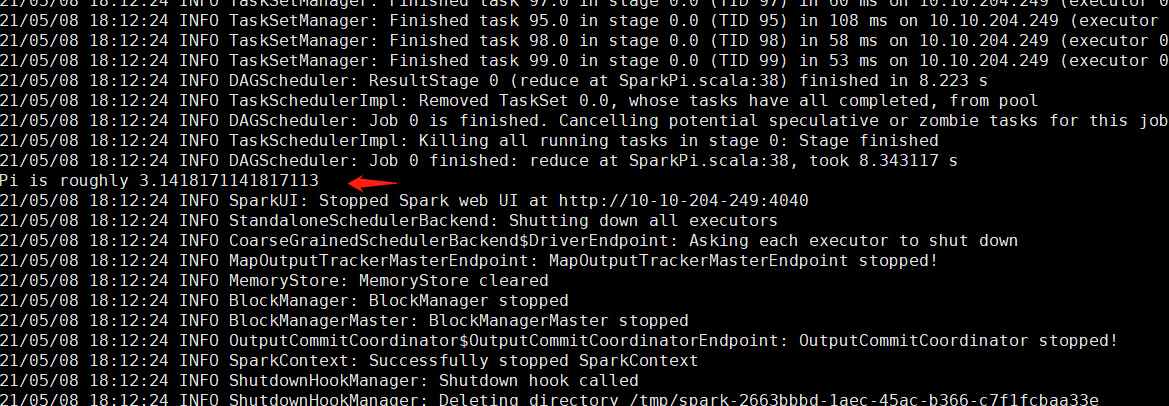 Image Added
Image Added
运行得出圆周率Pi的近似值3.14即部署成功。
5. 运维操作
启动/停止spark服务
| 代码块 |
|---|
cd /data/spark-3.0.0-bin-hadoop2hadoop3.72/binsbin
./spark-submit --class org.apache.spark.examples.SparkPi --master spark://节点的ip:7077 /opt/spark-3.0.0-bin-hadoop2.7/examples/jars/spark-examples_2.12-3.0.0.jar 100 |
 Image Removed
Image Removed
运行得出圆周率Pi的近似值3.14即部署成功。
安装Hadoop组件
数据挖掘V96版本增加了节点中间数据存储,所以需要安装Hadoop组件。
系统环境设置
单机或集群部署Hadoop集群,均需设置系统环境
1.开放防火墙端口
| 服务名 | 需要开放端口 |
|---|
Hadoop | 50090,50070,9000,50010,50075,50020 |
如果确实需要打开防火墙安装,需要给防火墙放开以下需要使用到的端口开启端口:50090,50070,9000,50010,50075,50020start-all.sh #启动spark
./stop-all.sh #停止spark |
Spark集群部署参考文档:部署Spark集群
2、安装Hadoop组件
数据挖掘V10版本增加了Hadoop节点中间数据存储,可根据需要部署。
1、系统环境准备
1.1防火墙配置
为了便于安装,建议在安装前关闭防火墙。使用过程中,为了系统安全可以选择启用防火墙,但必须启用服务相关端口。
1.关闭防火墙
临时关闭防火墙
| 代码块 |
|---|
|
systemctl stop firewalld
|
永久关闭防火墙
| 代码块 |
|---|
|
firewall-cmd --zone=public --add-port=50090/tcp --permanent
systemctl disable firewalld
|
查看防火墙状态
| 代码块 |
|---|
|
systemctl status firewalld
|
2.开启防火墙
相关服务及端口对照表:
| 服务名 | 需要开放端口 |
|---|
| Hadoop | 9864,9866,9867,9868,9870 |
如果确实需要打开防火墙安装,需要给防火墙放开以下需要使用到的端口
开启端口:9864,9866,9867,9868,9870
| 代码块 |
|---|
|
firewall-cmd --zone=public --add-port=500709864/tcp --permanent
firewall-cmd --zone=public --add-port=90009866/tcp --permanent
firewall-cmd --zone=public --add-port=500109867/tcp --permanent
firewall-cmd --zone=public --add-port=500759868/tcp --permanent
firewall-cmd --zone=public --add-port=500209870/tcp --permanent
|
配置完以后重新加载firewalld,使配置生效
查看防火墙的配置信息
| 代码块 |
|---|
|
firewall-cmd --list-all
|
23.
取消打开文件限制修改/etc/security/limits.conf文件在文件的末尾加入以下内容:关闭selinux
临时关闭selinux,立即生效,不需要重启服务器。
| 代码块 |
|---|
language |
|---|
|
vi setenforce 0
|
永久关闭selinux,修改完配置后需要重启服务器才能生效
| 代码块 |
|---|
|
sed -i 's/=enforcing/=disabled/g' /etc/selinux/config |
1.2取消打开文件限制
修改/etc/security/limits.conf文件在文件的末尾加入以下内容:
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
vi /etc/security/limits.conf |
在文件的末尾加入以下内容:
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072 |
Hadoop单节点安装2、Hadoop单节点安装
如果部署Hadoop集群,则跳过该章节,查看Hadoop集群部署章节。
1.设置免密登陆
生成密钥2.1 配置主机名映射
将数据挖掘组件中的服务器主机名映射到hosts文件中
| 代码块 |
|---|
| 代码块 |
|---|
|
tar -zxvf hadoop-2.7.3. |
ssh-keygen |
输入ssh-keygen后,连续按三次回车,不用输入其它信息
复制公钥
| 代码块 |
|---|
|
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys |
测试是否设置成功,例如:
如果不用输入密码,表示成功。
2.安装Hadoop
创建hadoop相关目录
创建临时目录
| 代码块 |
|---|
|
mkdir -p /opt/hdfs/tmp |
创建namenode数据目录
| 代码块 |
|---|
|
mkdir -p /opt/hdfs/name |
创建datanode目录
注意这个目录尽量创建在空间比较大的目录,如有多个磁盘,可创建多个目录
| 代码块 |
|---|
|
mkdir -p /opt/hdfs/data |
解压hadoop安装包到指定目录
文件末尾添(根据实际环境信息设置,如果已设置,则无需重复):
| 代码块 |
|---|
|
10.10.204.248 10-10-204-248
10.10.204.249 10-10-204-249
10.10.204.250 10-10-204-250 |
2.2 配置系统免密登录
| 注意 |
|---|
|
文档中Spark与Hadoop部署在相同环境,则无需重复设置系统免密登陆 |
登陆服务器,生成密钥
输入ssh-keygen后,连续按三次回车,不用输入其它信息。
复制公钥到文件中:
| 代码块 |
|---|
|
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys |
测试是否设置成功
示例:
| 代码块 |
|---|
|
ssh root@10-10-204-249 |
如果不用输入密码,表示配置成功
2.3 安装JAVA环境
| 注意 |
|---|
|
文档中Spark与Hadoop部署在相同环境,则无需重复设置JAVA环境 |
解压jdk到指定目录:
| 代码块 |
|---|
|
tar -zxvf jdk-8u181-linux-x64.tar.gz -C /optdata |
修改Hadoop配置文件
1.修改hadoop-env.sh
添加环境变量
| 代码块 |
|---|
| linenumberslanguage | truebash |
|---|
|
cdvi /opt/hadoop-2.7.3/etc/hadoop
vi hadoop-env.sh |
找到export JAVA_HOME= ,修改Java安装路径如下所示在文件末尾添加下面内容:
| 代码块 |
|---|
| linenumberslanguage | truebash |
|---|
|
export JAVA_HOME=/optdata/jdk8.0.202-linux_x64 |
找到export HADOOP_OPTS,在下面添加一行
| 代码块 |
|---|
|
export HADOOP_NAMENODE_OPTS="-XX:+UseParallelGC -Xmx4g" |
2、修改core-site.xml配置文件jdk1.8.0_181
export JAVA_BIN=$JAVA_HOME/bin
export CLASSPATH=:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_BIN |
让配置生效
验证安装
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /opt/hadoop-2.7.3/etc/hadoop
vi core-site.xml |
内容如下:2.4 安装Hadoop
2.4.1.准备hadoop数据目录
创建临时目录
1.设置免密登陆(集群服务器都执行)
生成密钥
输入ssh-keygen后,连续按三次回车,不用输入其它信息
复制公钥
| 代码块 |
|---|
|
ssh-copy-id -i ~/.ssh/id_rsa.pub root@smartbi-spark
ssh-copy-id -i ~/.ssh/id_rsa.pub root@smartbi-spark2
ssh-copy-id -i ~/.ssh/id_rsa.pub root@smartbi-spark3 |
测试是否设置成功,例如:
| 代码块 |
|---|
|
ssh root@smartbi-spark
ssh root@smartbi-spark2
ssh root@smartbi-spark3 |
如果不用输入密码,表示成功。
创建hadoop相关目录(集群服务器都执行)
创建临时目录
| 代码块 |
|---|
|
mkdir -p /opt/hdfs/tmp |
创建namenode数据目录
| 代码块 |
|---|
|
mkdir -p /opt/hdfs/name |
创建datanode目录
注意这个目录尽量创建在空间比较大的目录,如有多个磁盘,可创建多个目录
| 代码块 |
|---|
|
mkdir -p /opt/hdfs/data |
在管理节点安装配置Hadoop
例如在smartbi-spark节点执行
解压hadoop安装包到指定目录
| 代码块 |
|---|
|
tar -zxvf hadoop-2.7.3.tar.gz -C /opt |
②修改配置文件
1.修改hadoop-env.sh
| 代码块 |
|---|
|
cd /opt/hadoop-2.7.3/etc/hadoop
vi hadoop-env.sh |
找到export JAVA_HOME= ,修改Java安装路径如下所示
| 代码块 |
|---|
|
export JAVA_HOME=/opt/jdk8.0.202-linux_x64 |
找到export HADOOP_OPTS,在下面添加一行
| 代码块 |
|---|
|
export HADOOP_NAMENODE_OPTS="-XX:+UseParallelGC -Xmx4g" |
2、修改core-site.xml配置文件
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /opt/hadoop-2.7.3/etc/hadoop
vi core-site.xml |
内容如下:
| 代码块 |
|---|
| language | xml |
|---|
| linenumbers | true |
|---|
|
<configuration>
<property>
<name>fs.defaultFS</name>
<!--根据实际情况替换成本机的IP或主机名 -->
<value>hdfs://smartbi-spark:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 注意替换实际目录 -->
<value>file:/opt/hdfs/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>100800</value>
</property>
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
</configuration> |
3、修改hdfs-site.xml配置文件
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /opt/hadoop-2.7.3/etc/hadoop
vi hdfs-site.xml |
内容如下:
| 代码块 |
|---|
| language | xml |
|---|
| linenumbers | true |
|---|
|
<configuration>
<property>
<name>dfs.name.dir</name>
<!-- 注意替换实际目录 -->
<value>file:/opt/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<!-- 注意替换实际目录 -->
<value>file:/opt/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>16384</value>
</property>
</configuration> |
| 注意 |
|---|
注意:dfs.data.dir尽量配置在空间比较大的目录,可以配置多个目录,中间用逗号分隔 |
4、修改hadoop-policy.xml文件
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /opt/hadoop-2.7.3/etc/hadoop
vi hadoop-policy.xml |
内容如下:
| 代码块 |
|---|
| language | xml |
|---|
| linenumbers | true |
|---|
|
<configuration>
<property>
<name>security.client.protocol.acl</name>
<value>*</value>
<description>ACL for ClientProtocol, which is used by user code
via the DistributedFileSystem.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<!-- 这里把实验引擎ip, python执行节点ip,spark部署机器ip,hadoop部署机器ip都加上-->
<!-- 如果实验引擎,python执行节点,spark,hadoop这些组件是集群部署,那么所有的IP地址都需要添加进来 -->
<!-- 增加以下配置 -->
<property>
<name>security.client.protocol.hosts</name>
<value>192.168.137.139,192.168.137.140,192.168.137.141,192.168.137.142,192.168.137.143</value>
</property>
<!-- end -->
<property>
<name>security.client.datanode.protocol.acl</name>
<value>*</value>
<description>ACL for ClientDatanodeProtocol, the client-to-datanode protocol
for block recovery.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<!-- 这里把实验引擎ip,python执行节点ip,spark部署机器ip,hadoop部署机器ip都加上-->
<!-- 如果实验引擎,python执行节点,spark,hadoop这些组件是集群部署,那么所有的IP地址都需要添加进来 -->
<!-- 增加以下配置 -->
<property>
<name>security.client.datanode.protocol.hosts</name>
<value>192.168.137.139,192.168.137.140,192.168.137.141,192.168.137.142,192.168.137.143</value>
</property>
<!-- end -->
<property>
<name>security.datanode.protocol.acl</name>
<value>*</value>
<description>ACL for DatanodeProtocol, which is used by datanodes to
communicate with the namenode.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.inter.datanode.protocol.acl</name>
<value>*</value>
<description>ACL for InterDatanodeProtocol, the inter-datanode protocol
for updating generation timestamp.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.namenode.protocol.acl</name>
<value>*</value>
<description>ACL for NamenodeProtocol, the protocol used by the secondary
namenode to communicate with the namenode.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.admin.operations.protocol.acl</name>
<value>*</value>
<description>ACL for AdminOperationsProtocol. Used for admin commands.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.refresh.user.mappings.protocol.acl</name>
<value>*</value>
<description>ACL for RefreshUserMappingsProtocol. Used to refresh
users mappings. The ACL is a comma-separated list of user and
group names. The user and group list is separated by a blank. For
e.g. "alice,bob users,wheel". A special value of "*" means all
users are allowed.</description>
</property>
<property>
<name>security.refresh.policy.protocol.acl</name>
<value>*</value>
<description>ACL for RefreshAuthorizationPolicyProtocol, used by the
dfsadmin and mradmin commands to refresh the security policy in-effect.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.ha.service.protocol.acl</name>
<value>*</value>
<description>ACL for HAService protocol used by HAAdmin to manage the
active and stand-by states of namenode.</description>
</property>
<property>
<name>security.zkfc.protocol.acl</name>
<value>*</value>
<description>ACL for access to the ZK Failover Controller
</description>
</property>
<property>
<name>security.qjournal.service.protocol.acl</name>
<value>*</value>
<description>ACL for QJournalProtocol, used by the NN to communicate with
JNs when using the QuorumJournalManager for edit logs.</description>
</property>
<property>
<name>security.mrhs.client.protocol.acl</name>
<value>*</value>
<description>ACL for HSClientProtocol, used by job clients to
communciate with the MR History Server job status etc.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<!-- YARN Protocols -->
<property>
<name>security.resourcetracker.protocol.acl</name>
<value>*</value>
<description>ACL for ResourceTrackerProtocol, used by the
ResourceManager and NodeManager to communicate with each other.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.resourcemanager-administration.protocol.acl</name>
<value>*</value>
<description>ACL for ResourceManagerAdministrationProtocol, for admin commands.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.applicationclient.protocol.acl</name>
<value>*</value>
<description>ACL for ApplicationClientProtocol, used by the ResourceManager
and applications submission clients to communicate with each other.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>| language | xml |
|---|
| linenumbers | true |
|---|
|
<configuration>
<property>
<name>fs.defaultFS</name>
<!--根据实际情况替换成本机的IP或主机名 -->
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 注意替换实际目录 -->
<value>file:/opt/hdfs/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>100800</value>
</property>
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
</configuration> |
3、修改hdfs-site.xml配置文件
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /opt/hadoop-2.7.3/etc/hadoop
vi hdfs-site.xml |
内容如下:
| 代码块 |
|---|
| language | xml |
|---|
| linenumbers | true |
|---|
|
<configuration>
<property>
<name>dfs.name.dir</name>
<!-- 注意替换实际目录 -->
<value>file:/opt/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<!-- 注意替换实际目录 -->
<value>file:/opt/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>16384</value>
</property>
</configuration> |
| 注意 |
|---|
|
注意:dfs.data.dir尽量配置在空间比较大的目录,可以配置多个目录,中间用逗号分隔 |
4、修改hadoop-policy.xml
| 代码块 |
|---|
|
cd /opt/hadoop-2.7.3/etc/hadoop
vi hadoop-policy.xml |
内容如下:
| 代码块 |
|---|
| language | xml |
|---|
| linenumbers | true |
|---|
|
<configuration>
<property>
<name>security.client.protocol.acl</name>
<value>*</value>
<description>ACL for ClientProtocol, which is used by user code
via the DistributedFileSystem.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<!-- 这里把实验引擎ip, python执行节点ip,spark部署机器ip,hadoop部署机器ip都加上-->
<!-- 如果实验引擎,python执行节点,spark,hadoop这些组件是集群部署,那么所有的IP地址都需要添加进来 -->
<!-- 增加以下配置 -->
<property>
<name>security.client.protocol.hosts</name>
<value>192.168.137.139,192.168.137.140,192.168.137.141</value>
</property>
<!-- end -->
<property>
<name>security.client.datanode.protocol.acl</name>
<value>*</value>
<description>ACL for ClientDatanodeProtocol, the client-to-datanode protocol
for block recovery.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<!-- 这里把实验引擎ip,python执行节点ip,spark部署机器ip,hadoop部署机器ip都加上-->
<!-- 如果实验引擎,python执行节点,spark,hadoop这些组件是集群部署,那么所有的IP地址都需要添加进来 -->
<!-- 增加以下配置 -->
<property>
<name>security.client.datanode.protocol.hosts</name>
<value>192.168.137.139,192.168.137.140,192.168.137.141</value>
</property>
<!-- end -->
<property>
<name>security.datanode.protocol.acl</name>
<value>*</value>
<description>ACL for DatanodeProtocol, which is used by datanodes to
communicate with the namenode.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.inter.datanode.protocol.acl</name>
<value>*</value>
<description>ACL for InterDatanodeProtocol, the inter-datanode protocol
for updating generation timestamp.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.namenode.protocol.acl</name>
<value>*</value>
<description>ACL for NamenodeProtocol, the protocol used by the secondary
namenode to communicate with the namenode.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.admin.operations.protocol.acl</name>
<value>*</value>
<description>ACL for AdminOperationsProtocol. Used for admin commands.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.refresh.user.mappings.protocol.acl</name>
<value>*</value>
<description>ACL for RefreshUserMappingsProtocol. Used to refresh
users mappings. The ACL is a comma-separated list of user and
group names. The user and group list is separated by a blank. For
e.g. "alice,bob users,wheel". A special value of "*" means all
users are allowed.</description>
</property>
<property>
<name>security.refresh.policy.protocol.acl</name>
<value>*</value>
<description>ACL for RefreshAuthorizationPolicyProtocol, used by the
dfsadmin and mradmin commands to refresh the security policy in-effect.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.ha.service.protocol.acl</name>
<value>*</value>
<description>ACL for HAService protocol used by HAAdmin to manage the
active and stand-by states of namenode.</description>
</property>
<property>
<name>security.zkfc.protocol.acl</name>
<value>*</value>
<description>ACL for access to the ZK Failover Controller
</description>
</property>
<property>
<name>security.qjournal.service.protocol.acl</name>
<value>*</value>
<description>ACL for QJournalProtocol, used by the NN to communicate with
JNs when using the QuorumJournalManager for edit logs.</description>
</property>
<property>
<name>security.mrhs.client.protocol.acl</name>
<value>*</value>
<description>ACL for HSClientProtocol, used by job clients to
communciate with the MR History Server job status etc.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<!-- YARN Protocols -->
<property>
<name>security.resourcetracker.protocol.acl</name>
<value>*</value>
<description>ACL for ResourceTrackerProtocol, used by the
ResourceManager and NodeManager to communicate with each other.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.resourcemanager-administration.protocol.acl</name>
<value>*</value>
<description>ACL for ResourceManagerAdministrationProtocol, for admin commands.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.applicationclient.protocol.acl</name>
<value>*</value>
<description>ACL for ApplicationClientProtocol, used by the ResourceManager
and applications submission clients to communicate with each other.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.applicationmaster.protocol.acl</name>
<value>*</value>
<description>ACL for ApplicationMasterProtocol, used by the ResourceManager
and ApplicationMasters to communicate with each other.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.containermanagement.protocol.acl</name>
<value>*</value>
<description>ACL for ContainerManagementProtocol protocol, used by the NodeManager
and ApplicationMasters to communicate with each other.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.resourcelocalizer.protocol.acl</name>
<value>*</value>
<description>ACL for ResourceLocalizer protocol, used by the NodeManager
and ResourceLocalizer to communicate with each other.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.job.task.protocol.acl</name>
<value>*</value>
<description>ACL for TaskUmbilicalProtocol, used by the map and reduce
tasks to communicate with the parent tasktracker.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.job.client.protocol.acl</name>
<value>*</value>
<description>ACL for MRClientProtocol, used by job clients to
communciate with the MR ApplicationMaster to query job status etc.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<property>
<name>security.applicationhistory.protocol.acl</name>
<value>*</value>
<description>ACL for ApplicationHistoryProtocol, used by the timeline
server and the generic history service client to communicate with each other.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
</configuration> |
| 注意 |
|---|
|
hadoop-policy.xml配置文件中,security.client.protocol.hosts,security.client.datanode.protocol.hosts 这两个配置项的值,要改成实际部署环境的IP地址 |
配置Hadoop环境变量
添加环境变量。
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
vi ~/.bash_profile |
在最底下添加下面内容:
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
export HADOOP_HOME=/opt/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin |
让配置生效
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
source ~/.bash_profile |
3.启动Hadoop
①格式化hadoop
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /opt/hadoop-2.7.3/
./bin/hdfs namenode -format |
| 注意 |
|---|
|
仅第一次启动时需要执行格式化Hadoop操作,后续启动无需进行此操作 |
②启动hadoop
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /opt/hadoop-2.7.3/
./sbin/start-dfs.sh |
③创建中间数据存储目录(数据挖掘实验引擎集群需要使用)
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
hdfs dfs -mkdir /mining
hdfs dfs -chown mining:mining /mining |
4.验证Hadoop
①在浏览器输入: http://本机ip:50070/dfshealth.html#tab-overview, 检查集群状态
 Image Removed
Image Removed
②检查mining目录是否创建成功
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
hdfs dfs -ls / #显示创建的/mining即表示创建成功 |
如上显示,表示Hadoop安装成功。
5.运维操作
停止hadoop
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /opt/hadoop-2.7.3/
./sbin/stop-dfs.sh |
启动hadoop
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /opt/hadoop-2.7.3/
./sbin/start-dfs.sh |
Hadoop集群安装
如已部署Hadoop单机,则跳过Hadoop集群部署章节,
例如集群服务器:
机器 | 主机名 | 组件实例 |
|---|
192.168.137.141 | smartbi-spark | spark master,spark worker,hadoop namenode,hadoop datanode |
192.168.137.142 | smartbi-spark2 | spark worker,hadoop datanode |
192.168.137.143 | smartbi-spark3 | spark worker,hadoop datanode |
创建namenode数据目录
| 代码块 |
|---|
|
mkdir -p /data/hdfs/name |
创建datanode 数据目录
注意:这个目录尽量创建在空间比较大的目录,如果有多个磁盘,可以创建多个目录
| 代码块 |
|---|
|
mkdir -p /data/hdfs/data |
2.4.2.解压Hadoop到安装目录
| 代码块 |
|---|
|
tar -zxvf hadoop-3.2.2.tar.gz -C /data |
2.4.3.修改hadoop配置
①修改hadoop-env.sh
| 代码块 |
|---|
|
cd /data/hadoop-3.2.2/etc/hadoop
vi hadoop-env.sh |
找到"export JAVA_HOME",修改为如下所示(替换成实际环境的路径):
| 代码块 |
|---|
|
export JAVA_HOME=/data/jdk1.8.0_181 |
 Image Added
Image Added
找到"export HDFS_NAMENODE_OPTS", 在下面添加一行
| 代码块 |
|---|
|
export HDFS_NAMENODE_OPTS="-XX:+UseParallelGC -Xmx4g" |
 Image Added
Image Added
添加启动用户, 在文件最后添加以下内容
| 代码块 |
|---|
|
export HDFS_DATANODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root |
 Image Added
Image Added
②修改core-site.xml
| 代码块 |
|---|
|
cd /data/hadoop-3.2.2/etc/hadoop
vi core-site.xml |
内容如下:
| 代码块 |
|---|
|
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- 注意替换成实际的主机名 -->
<value>hdfs://10-10-204-249:9000</value>
</property>
<property>
<name>security.applicationmaster.protocol.acl</name> <value>*</value><name>hadoop.tmp.dir</name>
<description>ACL for ApplicationMasterProtocol, used by the ResourceManager <!-- 注意替换成实际的路径 -->
and ApplicationMasters to communicate with each other.
<value>file:/data/hdfs/tmp</value>
</property>
The ACL<property>
is a comma-separated list of user and group names. The user and<name>fs.trash.interval</name>
group list<value>100800</value>
is separated by a blank. For e.g. "alice,bob users,wheel". </property>
A<property>
special value of "*" means all users are allowed<name>hadoop.security.</description>authorization</name>
<<value>true</property>value>
<property> </property>
</configuration> |
④修改hdfs-site.xml
| 代码块 |
|---|
cd /data/hadoop-3.2.2/etc/hadoop
vi <name>security.containermanagement.protocol.acl</name>hdfs-site.xml |
内容如下:
| 代码块 |
|---|
|
<configuration>
<value>*</value><property>
<description>ACL for ContainerManagementProtocol protocol, used by the NodeManager <name>dfs.name.dir</name>
and ApplicationMasters to communicate with each other.<!-- 注意替换成实际的路径 -->
The ACL is a comma-separated list of user and group names. The user and<value>file:/data/hdfs/name</value>
</property>
<property>
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description> <name>dfs.data.dir</name>
<!-- 注意替换成实际的路径 -->
<value>file:/data/hdfs/data</value>
</property>
<property>
<name>security.resourcelocalizer.protocol.acl<<name>dfs.replication</name>
<value>*</value> <value>1</value>
<description>ACL for ResourceLocalizer protocol, used by the NodeManager</property>
<property>
and ResourceLocalizer to communicate with each other.<name>dfs.webhdfs.enabled</name>
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel". <value>false</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
A special value of "*" means all users are allowed.</description> <value>16384</value>
</property>
</configuration> |
| 注意 |
|---|
|
dfs.data.dir尽量配置在空间比较大的目录,可以配置多个目录,中间用逗号分隔 |
⑤修改hadoop-policy.xml
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /data/hadoop-3.2.2/etc/hadoop
vi hadoop-policy.xml |
内容如下:
| 代码块 |
|---|
| language | xml |
|---|
| linenumbers | true |
|---|
|
<configuration>
<property>
<name>security.jobclient.task.protocol.acl</name>
<value>*</value>
<description>ACL for TaskUmbilicalProtocol, used by the map and reduce
tasks to communicate with the parent tasktracker ClientProtocol, which is used by user code
via the DistributedFileSystem.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
.
A special value of "*" means all users are allowed.</description>
</property>
<!-- 这里把实验引擎ip, python执行节点ip,spark部署机器ip,hadoop部署机器ip都加上-->
<!-- 增加以下配置 -->
<property>
A special value of "*" means all users are allowed.</description> <name>security.client.protocol.hosts</name>
<value>10.10.204.248,10.10.204.249,10.10.204.250</value>
</property>
<!-- end -->
<property>
<name>security.jobclient.clientdatanode.protocol.acl</name>
<value>*</value>
<description>ACL for MRClientProtocolClientDatanodeProtocol, used by job clients to
communciate with the MR ApplicationMaster to query job status etcthe client-to-datanode protocol
for block recovery.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description> users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
<!-- 这里把实验引擎ip,python执行节点ip,spark部署机器ip,hadoop部署机器ip都加上-->
<!-- 增加以下配置 -->
<property>
<name>security.client.datanode.protocol.hosts</name>
<value>10.10.204.248,10.10.204.249,10.10.204.250</value>
</property>
<!-- end -->
<property>
<name>security.applicationhistorydatanode.protocol.acl</name>
<value>*</value>
<description>ACL for ApplicationHistoryProtocol, used by the timeline
server and the generic history service client to <description>ACL for DatanodeProtocol, which is used by datanodes to
communicate with eachthe othernamenode.
The ACL is a comma-separated list of user and group names. The user and
group list is separated by a blank. For e.g. "alice,bob users,wheel".
A special value of "*" means all users are allowed.</description>
</property>
</configuration> |
| 注意 |
|---|
|
hadoop-policy.xml配置文件中,security.client.protocol.hosts,security.client.datanode.protocol.hosts 这两个配置项的值,要改成实际部署环境的IP地址 |
5、修改slaves配置文件
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /opt/hadoop-2.7.3/etc/hadoop
vi slaves |
把所有的datanode的主机名添加到文件中,例如:
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
smartbi-spark
smartbi-spark2
smartbi-spark3 |
分发Hadoop安装包(管理节点执行)
将hadoop管理节点上的hadoop安装包分发到其他节点:
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
scp -r /opt/hadoop-2.7.3 root@hadoop2:/opt
scp -r /opt/hadoop-2.7.3 root@hadoop3:/opt |
配置Hadoop环境变量(每个节点执行)
添加环境变量。 value of "*" means all users are allowed.</description>
</property>
<!-- hadoop-policy.xml配置文件以上部分需要修改 -->
<!-- hadoop-policy.xml后续配置无需修改和添加,此处省略,避免文档篇幅过长 -->
<!-- ... -->
</configuration> |
| 注意 |
|---|
|
hadoop-policy.xml配置文件仅添加两处配置项; 新增的security.client.protocol.hosts,security.client.datanode.protocol.hosts两个配置项中的值,要替换成实际环境的IP地址; 此配置文件是限制可以访问hadoop节点的服务器ip,提高hadoop应用的安全性。 |
2.4.4.配置hadoop环境变量
| 代码块 |
|---|
| language | bash | linenumbers | true |
|---|
|
vi ~/etc/.bash_profile |
在最底下添加下面内容:在文件末尾添加下面内容:
| 代码块 |
|---|
| language | bash | linenumbers | true |
|---|
|
export HADOOP_HOME=/optdata/hadoop-3.2.7.32
export PATH=$PATH:$HADOOP_HOME/bin |
让配置生效
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
source ~/etc/.bash_profile |
启动Hadoop集群
①格式化hadoop(管理节点执行)2.4.5.启动Hadoop
①格式化hadoop
| 代码块 |
|---|
| language | bash | linenumbers | true |
|---|
|
cd /optdata/hadoop-3.2.7.32/
./bin/hdfs namenode -format |
| 注意 |
|---|
|
仅第一次启动时需要执行格式化Hadoop操作,后续启动无需进行此操作 |
②启动hadoop
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /optdata/hadoop-3.2.7.32/
./sbin/start-dfs.sh |
③创建中间数据存储目录(数据挖掘实验引擎集群需要使用)
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
sh |
③创建中间数据存储目录
| 代码块 |
|---|
hdfs dfs -mkdir /mining
hdfs dfs -chown mining:mining /mining |
验证Hadoop集群2.4.6.验证安装
①在浏览器输入: http http://本机ip本机IP:500709870/dfshealth.html#tab-overview , 检查集群状态Image Removed 检查集群状态
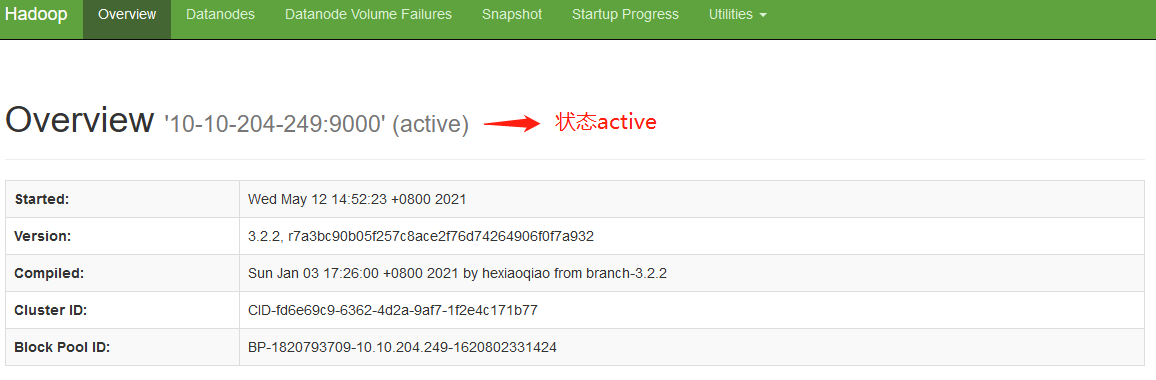 Image Added
Image Added
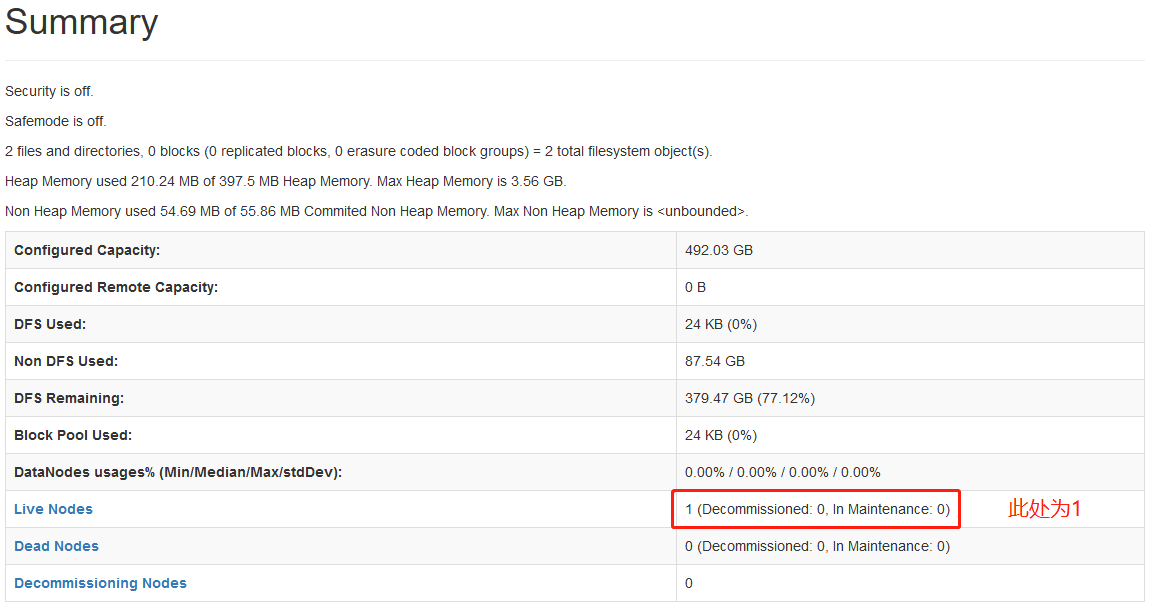 Image Added
Image Added
②检查mining目录是否创建成功
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
hdfs dfs -ls / #显示创建的/mining即表示创建成功 |
如上显示,表示Hadoop安装成功。
2.5 运维操作
停止hadoop
(管理节点执行)| 代码块 |
|---|
| language | bash | linenumbers | true |
|---|
|
cd /optdata/hadoop-3.2.7.32/
./sbin/stop-dfs.sh |
启动hadoop
(管理节点执行)| 代码块 |
|---|
| language | bash | linenumbers | true |
|---|
|
cd /optdata/hadoop-3.2.7.32/
./sbin/start-dfs.sh |
查看日志
hadoop的日志路径:/data/hadoop-2.7.3/logs
安装部署或者使用中有问题,可能需要根据日志来分析解决。
设置实验引擎练级中间数据存储URL
管理员登陆Smartbi
系统运维--系统选项--执行引擎–引擎配置

| 注意 |
|---|
|
如果是Hadoop集群,上图中节点数据hdfs存储目录需要填写Hadoop管理节点的IP |
Python执行节点更新
停止Python服务
进入安装Python计算节点的服务器,进入目录,停止python服务
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /opt/smartbi-mining-engine-bin/engine/sbin
./python-daemon.sh stop |
| 注意 |
|---|
|
注意,如果出现无法停止情况,可以通过jps查看python服务进程id,然后 kill -9 进程id |
更新引擎包
更新方式,参考实验引擎、服务引擎的更新方式,如果python执行节点跟实验引擎在同台机器,这步骤可以省略
创建执行代理程序启动用户
创建mining用户组组
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
groupadd mining |
创建启动用户(mining-ag)并指定用户组为mining
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
useradd -g mining mining-ag |
设置用户密码
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
passwd mining-ag |
给引擎安装目录附权限(为了使用mining-ag用户启动执行代理程序时候,有权限创建agent-data跟agent-logs目录)
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
chgrp mining /opt/smartbi-mining-engine-bin
chmod 775 /opt/smartbi-mining-engine-bin |
启动Python执行代理
管理员登陆Smartbi
系统运维--引擎设置

登陆到部署Python节点服务器,并切换到mining-ag用户
| 注意 |
|---|
|
为了避免出现安全问题,一定要切换到mining-ag用户去启动执行代理服务,不要使用安装用户或带有sudu权限的用户来启动执行代理服务 |
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
su - mining-ag |
切换到引擎启动目录
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
cd /opt/smartbi-mining-engine-bin/engine/sbin |
把拷贝命令粘贴,并执行,例如:
| 代码块 |
|---|
| language | bash |
|---|
| linenumbers | true |
|---|
|
./agent-daemon.sh start --master http://smartbi-engine:8899 --env python |
等待启动成功即可。


