还记得你第一次构建数据模型时的雄心壮志吗?想象着自己化身数据界的"神笔马良",挥一挥鼠标,就能让杂乱无章的数据乖乖听话,变成一幅清晰明了的商业洞察图。
然而现实总是骨感的,当你兴致勃勃地开始搭建,却发现:维度表主键重复?事实表数据缺失?关联关系一团乱麻?…… 恭喜你,成功解锁了数据模型构建的"隐藏关卡"——踩坑之旅!
别担心,你不是一个人在战斗!这次,我们一起回顾那些年我们踩过的坑,一起笑看数据模型界的"乌龙事件", 并从中吸取经验教训,让我们的下一次模型构建之旅更加顺畅!
踩坑一:事实表不使用共享日期维表
当处理包含多个日期列的事实表时,选择使用哪个日期列进行筛选变得尤为重要。若选择不当,可能导致日期序列的不连续性,进而造成查询结果中缺失某些天数。
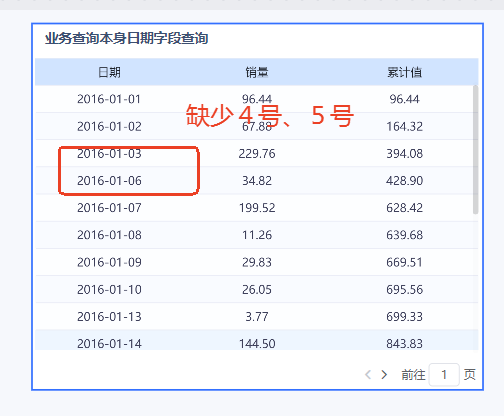
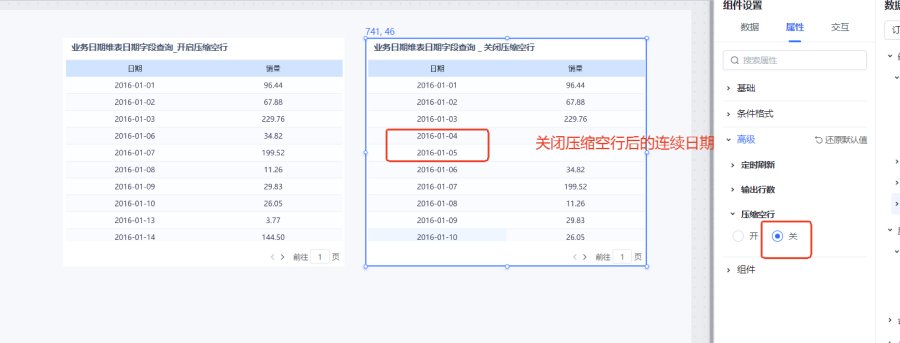
如下,我们直接使用销售表(sales)中本身的业务日期作为时间维度查询时,可以发现表中的日期是不连续的,缺少了6号、8号的日期数据。
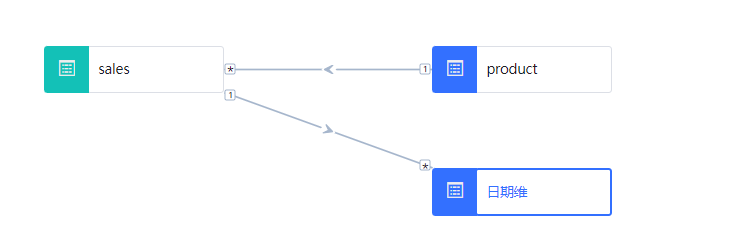
为了确保查询结果中日期序列的连续性,并且简化与日期相关的筛选逻辑,推荐的做法是创建一张共享的日期维度表。这张日期维度表不仅能够为报表提供所需的全部日期列,还可以包含额外的日期属性(如年、季度、月等),从而增强数据分析的能力并改善查询性能。
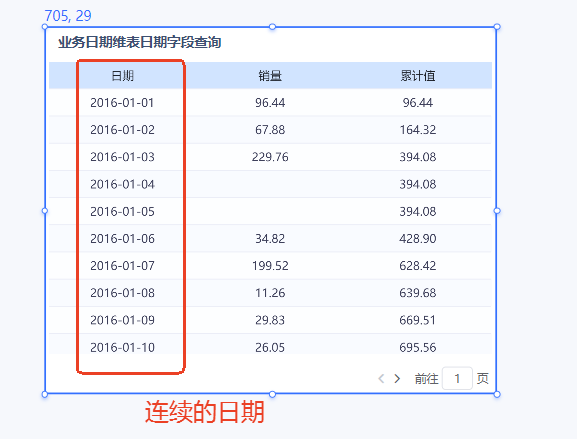
当然有些细心的朋友在实践过程中,会发现为什么明明已经勾选了日期维表的日期字段了,可是还是出来的是不连续日期结果呢?这个时候,我们不要忘了还有个"压缩空行"的设置呢!
什么是压缩空行?就是我们表中所有指标度量都为空的行会被压缩不显示。我们上面演示的连续日期示例中,4号、5号销量虽然为空,但是我们计算了累计值,所以即使没有关闭压缩空行,也可以显示连续的日期。如果我们表中有某些行指标数据都为空,又想显示连续日期,不要忘了关闭压缩空行的嗷。
踩坑二:关联了错误的字段
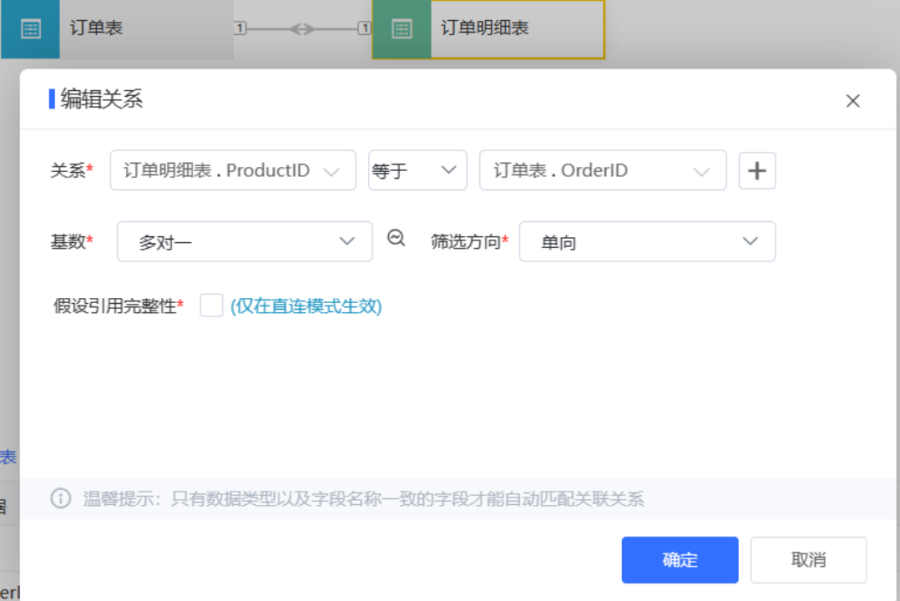
在数据库设计或查询编写过程中,如果主外键字段别名不一致,很容易选错关联字段。订单明细表与订单表本应通过orderID进行关联,但一不小心却用了productID。这种情况不会直接报错,但它带来的后果是查询结果与实际情况完全不符,甚至一般情况下都无法查询出来数据。那么,如何避免这种关联字段设置错误的情况呢?
这里有几个小技巧,可以帮助你确保关联字段的准确性:
1. 深入理解数据:首先,深入了解每个表的数据结构和业务含义。明确每个字段的作用及其所代表的业务实体关系。知道每个字段标识的是什么,以及它们应该如何相互关联。
2. 明确业务规则:接下来,清楚地定义不同表之间的业务关联规则。这包括识别哪些字段体现了一对一、一对多或多对多的关系,并确定对应的主键和外键是什么。
3. 审查数据字典:利用数据字典或元数据文档作为你的工具书,比如利用Excel工具,创建好数据字典,查阅每个字段的具体信息,包括数据类型、来源、含义以及与其他字段的关联方式。
4. 数据探索与预览:在建立关联之前,预览一下数据。检查字段的值是否符合预期,通过查看样本数据来验证关联字段是否能正确配对。
5. 规范命名:最后,采用一致且具有描述性的字段命名规则。例如,如果主键和外键通常有相同的前缀或后缀,那么在关联时就能更轻松地找到正确的对应字段。
踩坑三:数据本身有问题,维度数据不完整
在进行数据分析时,可能会遇到这样一种情况:事实表中有对应的销售数据,但在维度表中却找不到相关的产品信息。例如,产品维度表中的产品编号仅有16、32、42、47和56,而事实表中却包含了额外的产品编号4。当根据产品名称查询销量时,我们会发现部分产品名称显示为空白,但数量字段却有实际的数据。这种情况在SmartbiBI工具中是正常的,因为它准确反映了数据的现状——即某些销售记录缺乏有效的维度信息。


这种空白并不是系统异常,而是数据本身的一种体现。当然,为了提高数据分析的质量和用户体验,我们可以采取一些措施来解决这个问题:
1、识别并修正缺失的数据
源头排查:首先,检查源头系统,找出为何某些产品编号没有进入维度表的原因。这可能涉及到业务流程中的某个环节出现了偏差。
基于业务规则决策:一旦找到原因,根据业务规则判断这些缺失的数据是否应当被删除或替换为有效的数据。比如,如果产品编号4实际上是一个已停产的产品,考虑将其标记为"停售"状态而不是直接删除,以便保留历史销售数据的完整性。
2、 利用ETL进行数据清洗
数据处理:通过ETL对数据进行清洗。在数据加载到分析环境之前,先对其进行一系列的转换操作,如填充缺失值、标准化数据格式等。
提升数据质量:ETL工具可以帮助我们自动检测并处理那些不完整或不一致的数据,确保最终展示给用户的是一份高质量的数据集。
踩坑四:关系有多义性
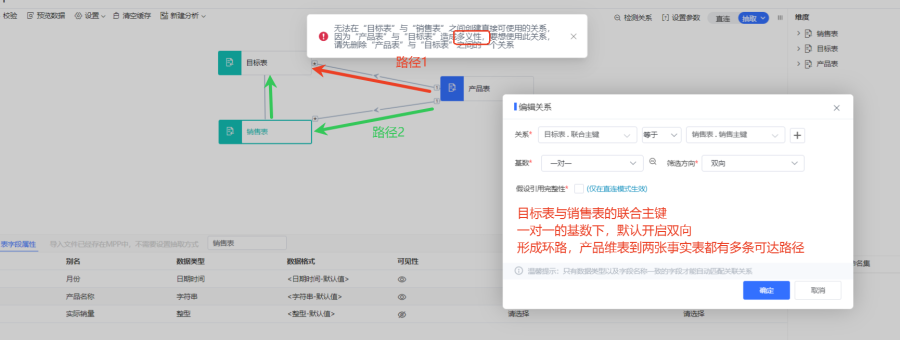
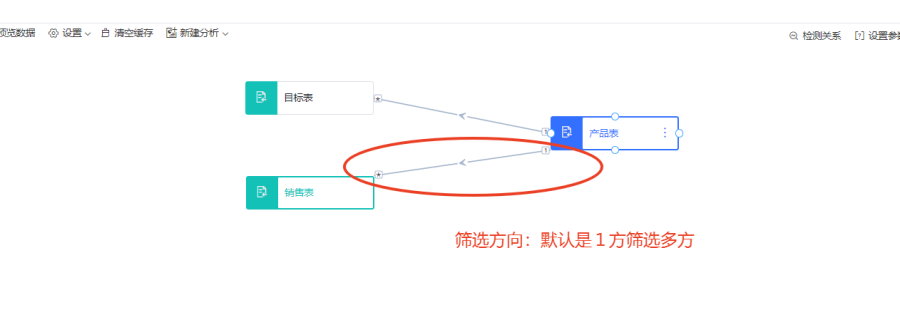
关系的多义性,是指当一张表触达另外一张表有多个路径。在多个事实表同时共享两个不同维度时,开启了双向筛选,会形成环路,也就是多个路径可选择,系统无法自动选择查询路径。
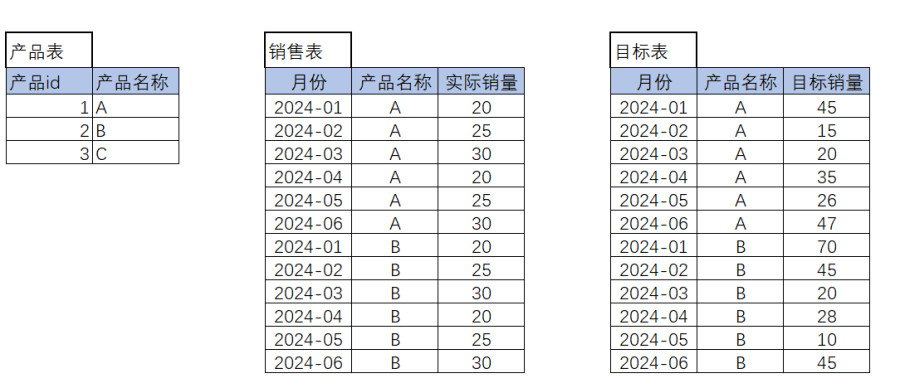
如下:当下有销售表和目标表,期望可以实现如下两种查询场景:
(1)可以选择产品表中的产品名称,查询目标销量、实际销量情况
(2)年月日查询各个产品下的实际销量、目标销量以及目标销量的前期值
通过日期与产品的构建计算列为主键关联查询时,提示关系路径"多义性"。如图中箭头指示,红色箭头表示"产品表"通过路径1直接可达"目标表";绿色剪头则表示"产品表"可通过路径2,即从"产品表"可通过"销售表"再到"目标表"。这样生成了两条筛选路径,造成多义性。我们需要保持"一个原则":1节点只能有一条路径到达相同的另外1个节点。
当遇到这种情况如何解决?
1、按需使用双向筛选:评估是否真的需要开启双向筛选功能。在数据模型中,一对一的筛选方向是默认开启双向的;而一对多/多对一关系的两个表,默认是一方的维度可以筛选多方的维度或数据,在一对多或多对一的关系中,如果期望多方的维度能直接过滤一方的维度或数据,就需要启用双向筛选。基数与筛选方向的更多说明,我们也可在《99% 的人都忽略了!强大模型的崛起秘密在于设置正确关系(上)》一文中再做了解。
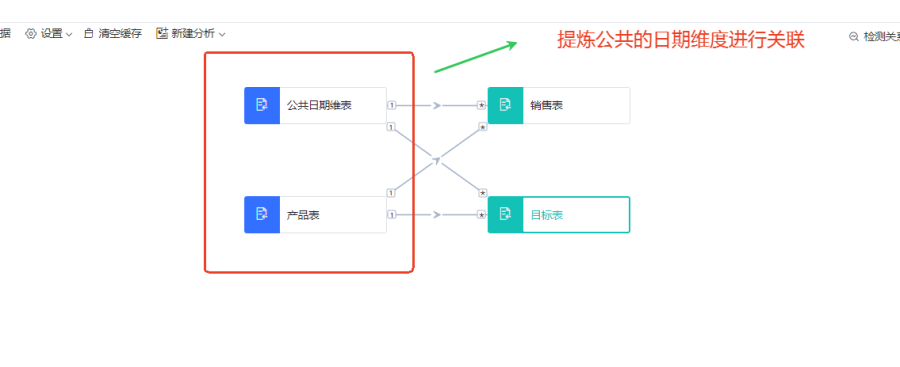
2. 抽取共享维表:考虑为共享维度创建一个独立的维表,如下,抽取公共的日期维度,通过公共的日期维表进行关联。
踩坑五:错误的基数关系
一个订单系统,每个订单理论上应该能关联多个订单明细记录。
原本关系是一对多,然后手工调整成了多对一:这不仅会导致数据结构混乱,并且订单明细表则失去了独立筛选的能力。结果就是,数据模型就无法真实反映业务的实际复杂性,导致信息丢失。
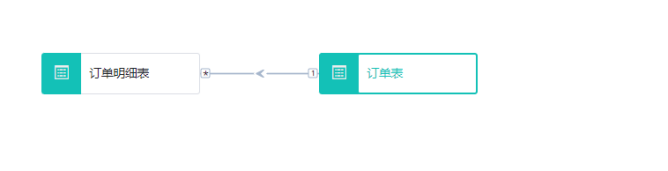

基数设错了,通常情况下不会报明显的异常错误。
那如何判断基数是否设置正确?
- 理解业务规则:首先,深入了解各个表之间的业务逻辑。明确哪些实体之间是一对一、一对多或多对多的关系。例如,一个订单可以包含多个订单项,这意味着订单表与订单明细表间存在一对多的关系。
- 检查字段特征:确定哪个字段作为主键,哪个字段作为外键。外键所在的表应当参照主键表的基数进行设置。
- 检查数据分布:实际验证一下我们的假设是否站得住脚。执行一些SQL查询来检查外键列的实际基数。如果我们认为[订单表]和[订单明细表]是一对多的关系,可以通过简单的SQL语句来确认这一点。例如:
订单表 与订单明细表,关联字段是OrderID,当订单表的count(*)与count(distinct (OrderID)),是一致的,则认为是“一”的一方;当订单明细表的count(*)与count(distinct (OrderID))不是一致时,则认为是“多”的一方。
同时,该sql也是系统提供自动检测关系功能的原理,也可通过点击检测来确认基数关系是否准确。
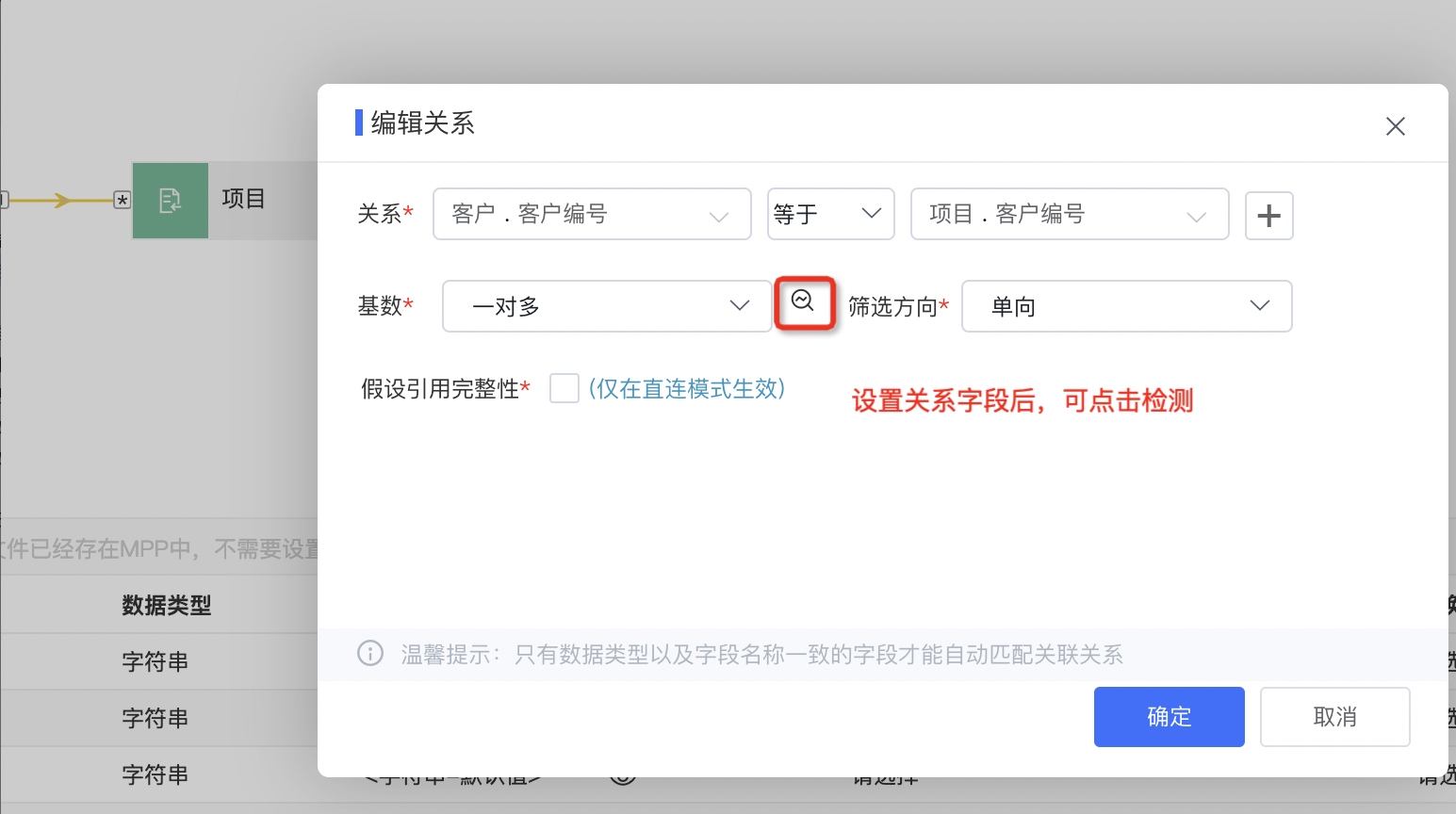
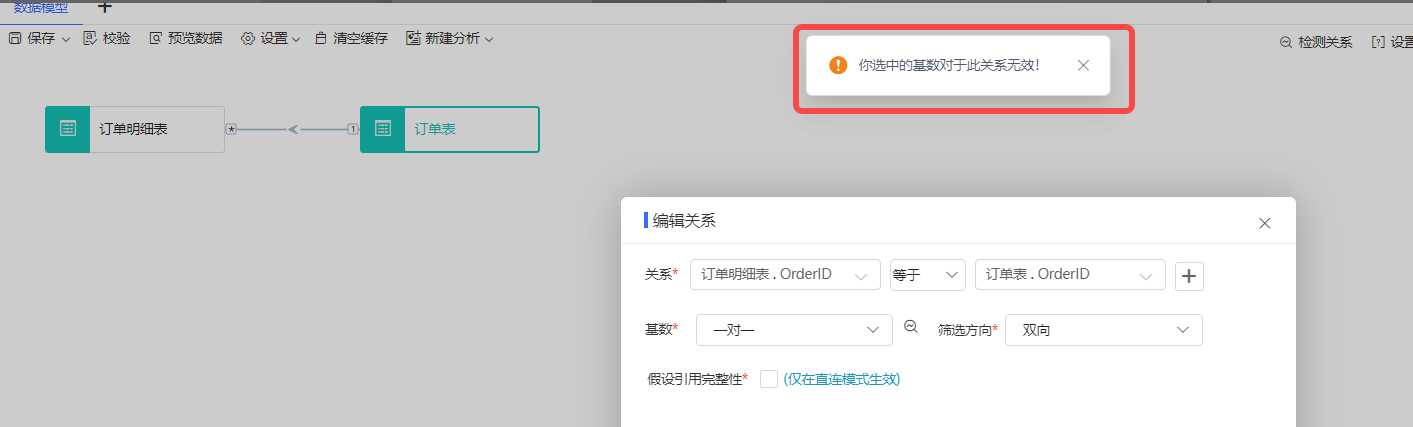
目前我们设置关联关系后,系统也会对错误的关联关系进行提示,如将订单明细表与订单表设置为“一对一”后,将会提示:“你选中的基数关系对于此关系无效!”
踩坑六:报表与数据模型一一对应
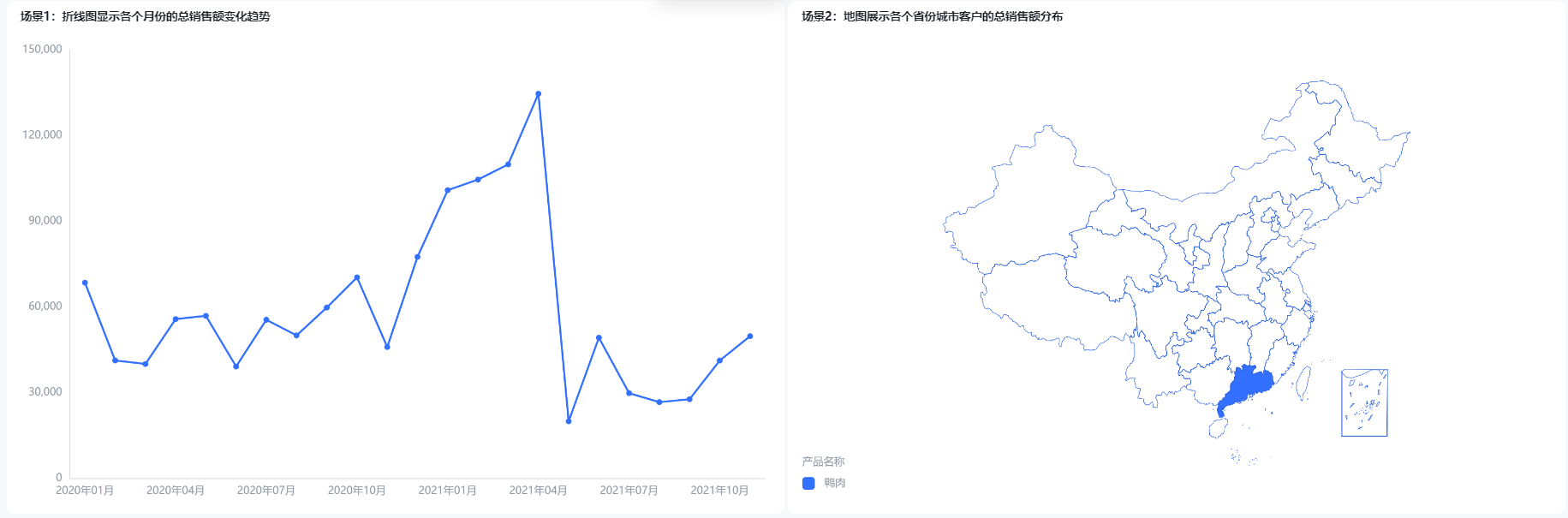
假设我们正在为一家零售公司构建一个销售分析主题的大屏,需要做以下场景分析:
(1)折线图显示各个月份的总销售额变化趋势。
(2)地图展示各个省份城市客户的总销售额分布。
(3)透视分析展示按产品类别和产品名称分组的销售额明细。
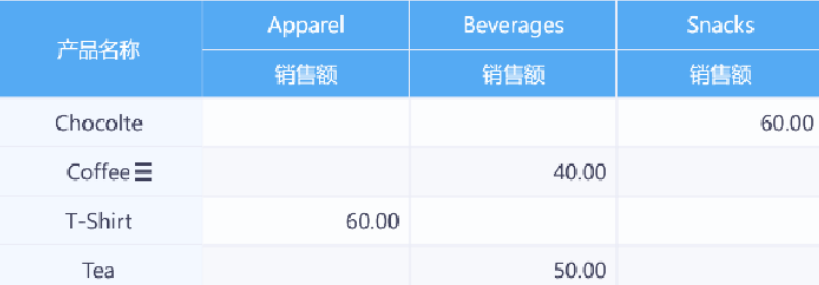
1、踩坑做法
在一个不太理想的方案中,我们可能会看到这样的设计:每一张报表背后直接对应着一个特定的SQL查询,甚至在极端情况下,每一个可视化组件都依赖于其独立的数据模型。这种做法虽然在短期内看似简化了开发流程,但实际上却埋下这些隐患:
(1)扩展性差:当业务需求发生变化或数据源更新时,这种紧耦合的设计使得系统难以进行有效的调整和扩展。任何对现有报表结构或是底层数据库模式的小改动,都可能需要重新编写大量的SQL脚本和数据处理逻辑,增加了维护成本。
(2)无法满足用户自助查询:BI工具强调的是让用户能够自由探索数据,提出自己的问题并获得即时的答案。然而,在上述架构下,由于每个报表或组件都是基于预定义的查询构建的,极大地限制了用户的灵活性和自主性。用户不得不依赖IT部门来创建新的查询或是修改现有的查询,导致响应时间延长,降低了决策效率。

2、正确做法
在理想的设计中,我们推荐采用一种更为灵活和高效的方法:开发一个或少数几个能够支持一类或多类需求场景的数据模型。如下图,我们从需求场景出发,构建一个通用的数据模型即可满足我们看板的查询需求。
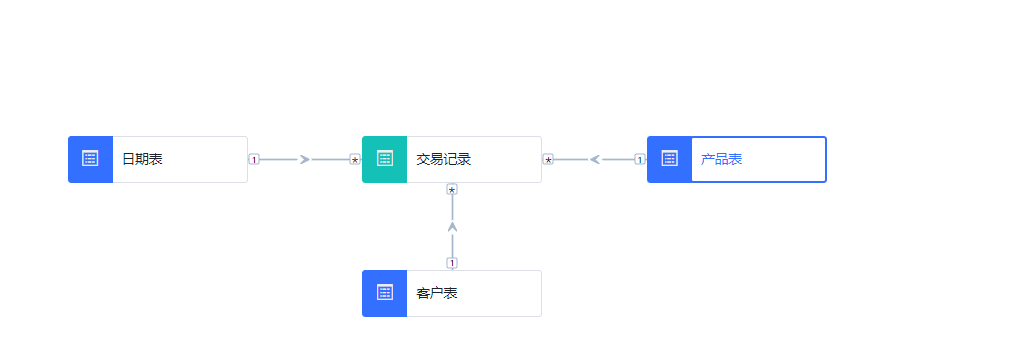
强调从整体上梳理各种报表需求的共性,并将这些需求整合到一个综合性的数据模型中。
通过构建通用的数据模型,无论是新增报表、修改现有报表还是调整业务逻辑,只需对核心数据模型进行相应的更新即可。这种设计减少了重复代码的数量,降低了因多处改动而引发错误的风险,同时也使得系统更容易适应未来的变化。它允许用户根据自己的需要自由地探索数据,无需受限于预定义的查询条件,用户可以轻松创建自定义视图和报告,快速获得所需的信息。
踩坑七:数据模型是join关系
初入模型界,我们可能会拿来与旧自助数据集中的join关系对比,常有疑问,数据模型的关系是一方left join 多方为什么有时候它出来的结果不是left join的结果,有时出现非常规逻辑。
这实际上涉及到数据建模的核心理念及其与传统SQL JOIN操作的区别。如下图的业务场景中,我们有如下2个查询需要,传统sql join和数据模型可以如何实现呢:
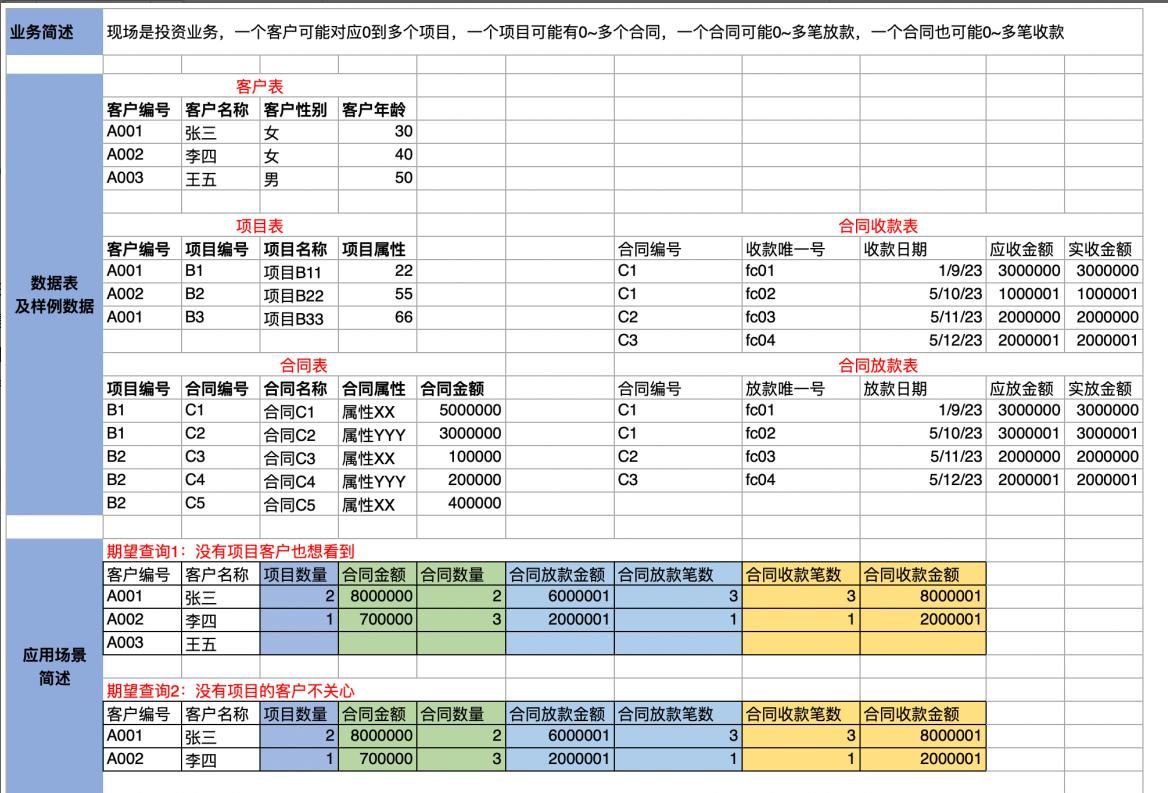
传统的join:
(1)查询场景1(没有项目的客户也需要查询出来):用客户表left join其他事实表分别做统计。

(2)查询场景2(没有项目的客户不需要查询出来):用事实表 left join 客户表分别做统计。

数据模型:
用数据模型可以表达为下图,设置正确基数关系和筛选方向后即可实现上面的查询场景。而在报表层面我们可以通过开启或关闭压缩空行来显示有无项目的客户。

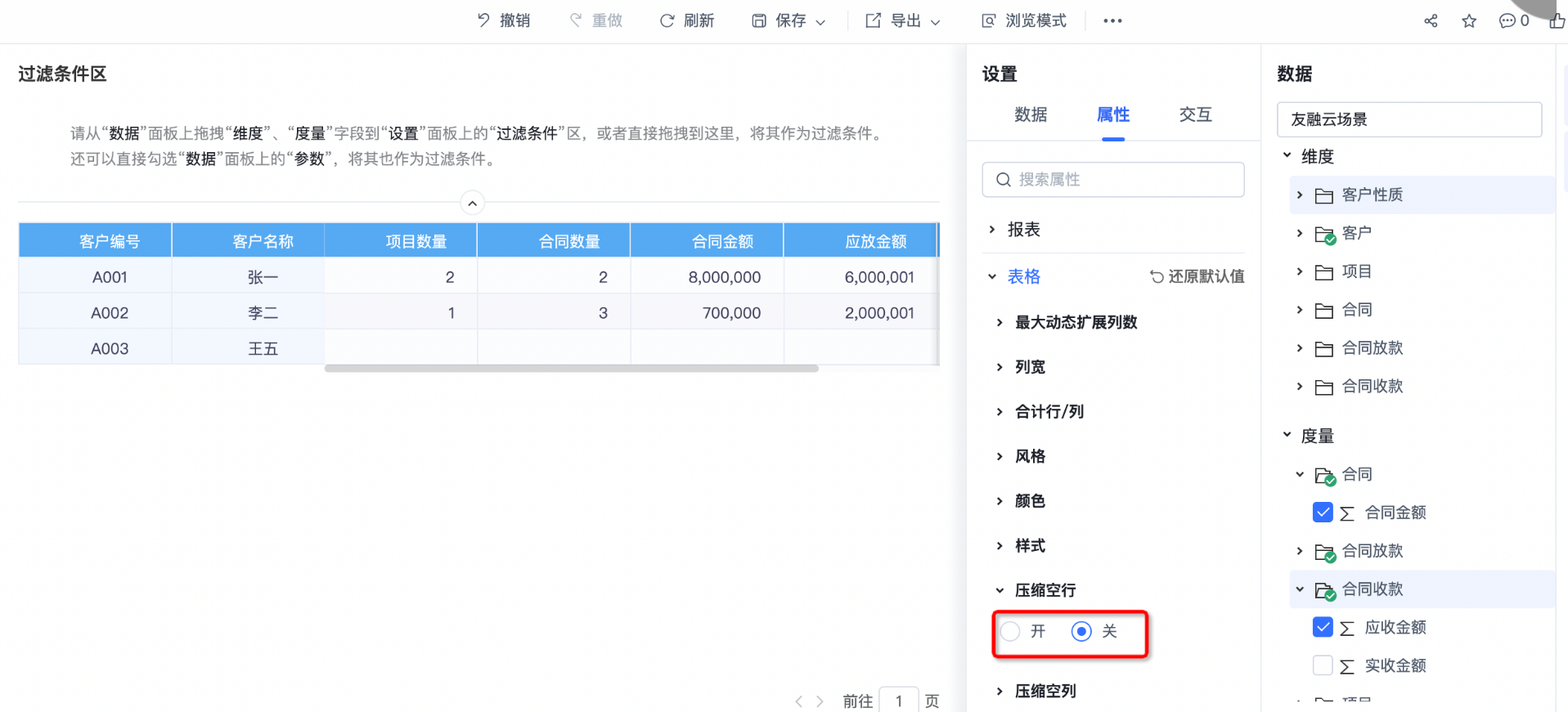
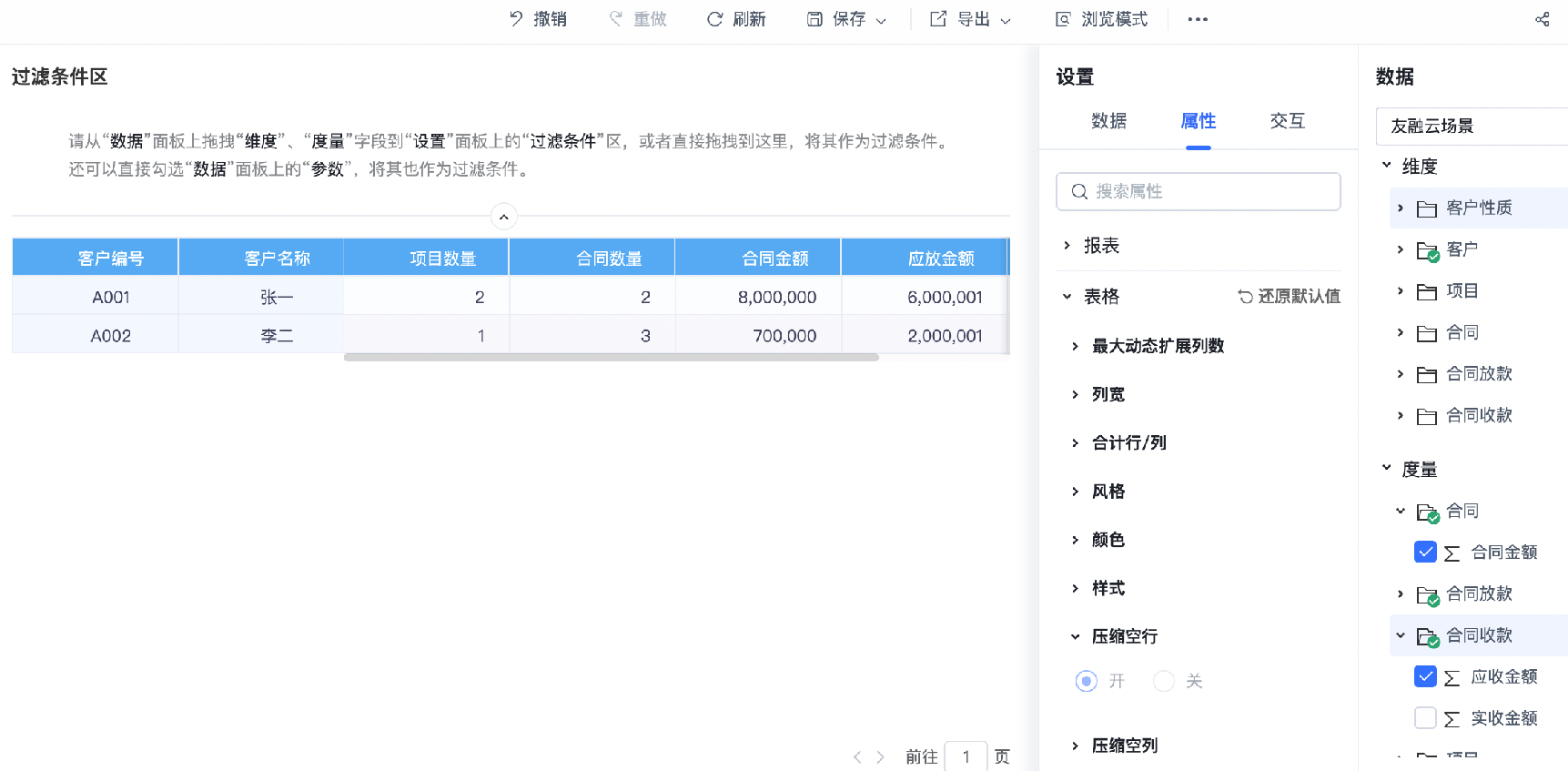
从上面的例子上面我们可以初步了解,数据模型作为指标体系的内核,期望的是构建一套模型,满足各种用户自助查数的场景,而join满足的都是特定场景的查数意图。传统的JOIN(如LEFT JOIN, RIGHT JOIN等)主要用于满足特定场景下的查询意图,而数据模型则更注重通过定义实体间的基数关系(一对多、多对一、一对一)来灵活响应用户的查询需求。
规则:基于基数的关系设置
非传统JOIN:数据模型中的关系设置并不是简单的LEFT JOIN或RIGHT JOIN,而是基于数据建模理论中的一对多、多对一和一对一关系。
动态构建:当用户选择表字段后,模型的OLAP引擎会根据所选的数据表字段动态构建JOIN关系及相应的SQL语句。这意味着,查询逻辑更加灵活,可以根据用户的具体需求进行调整。
对于数据模型来说,只要基数关系是正确的,就可根据查询意图去动态构建查询,并且保障数据不被放大,因为正确的基数关系,可以让系统统计指标时构建以下规则:以指标所在表为中心,将一方的维度表纳入构成一个扩展表(也可称查询子图,子图概念可在此文中进一步了解:《99% 的人都忽略了!强大模型的崛起秘密在于设置正确关系(上)》),基于这个扩展表的任意查询都可保障结果正确,因为只会纳入一方的维表,所以扩展表指标数据不会被放大或缩小,多方的表只有在启用了双向筛选才会被纳入作为筛选条件,这是基于join关系无法构建的一个规则。
通过本文,我们一同审视了数据建模过程中的种种“乌龙”,包括基数关系的误判到以及传统连接方法的局限。面对这些问题,虽然每一步都充满了挑战,但借助对业务需求的深刻洞察和科学的数据建模策略,我们发现了前行的道路。希望这些经历不仅能帮助你绕过类似的障碍,也能增强你在未来项目中的信心与能力。数据建模的世界总是充满未知,但也正是这些探索使我们的技能日益精湛。


