业务库迁移之后ID替换操作只适用于5.13号之后的包。
1 背景
业务库在迁移,数据连接修改为其他类型的数据库,或者本身数据库的catalog、schema发生了改变,已有的报表取数会找不到表,导致查询报错。
smartbi 为了解决这类问题,业务库迁移之后,可以替换ID。 其核心原理:Smartbi 通过记录数据源、catalog、schema 的对应关系,生成唯一 ID 标识表和字段。迁移后需在知识库中建立 “旧 ID 规则” 与 “新 ID 规则” 的映射,确保报表能正确匹配新数据库中的表结构。
1.1 适用场景
当业务库发生以下变更时,需通过 ID 替换保证报表正常取数:
1.2 关键概念说明
| 概念 | 说明 |
|---|---|
| catalog | 数据库的逻辑分组(类似 “数据库集群中的子库”),大部分数据库(如 PostgreSQL)支持,默认与配置的数据库名称相同,部分数据库不支持如Oracle无 |
| schema | 数据库中的模式(类似 “表的分组容器”,如 “public”“admin”),部分数据库不支持,如MySQL无 |
| ID 规则 | 控制字段 ID 的生成逻辑,分 “带 catalog” 和 “不带 catalog” 两类,支持原值、大写、小写三种格式。不支持catalog或schema,用null参与ID构成 |
2 操作步骤
目前schema节点、表字段的ID会记录添加表时数据库对应的catalog、schema;目前产品有2种规则,一种是新规则实现了多catalog的资源,另外一种是之前没有实现多catalog的资源;如果修改数据连接(如换库)后导致catalog与schema实际发生改变,需要重新添加表,这种场景下为了保证之前的报表正常使用,重新添加表之前需要针对已有资源设置ID替换规则,保证重新添加的表字段的ID与之前保持一致,才能正常查数。
以:源库为mysql,目标业务库为postgresql 为迁移示例进行说明。
1、需要先在数据连接把连接信息改成目标库postgresql的:

2、改完之后需要更改去知识库中手工插入源库、目标库的schema、catalog、规则。
使用第三方工具连接知识库,对规则表t_schema_idrule插入规则,
资源树数据连接下,一个schema节点对应只能插入一条,有多个schema需要插入多次:

示例SQL:
INSERT INTO .t_schema_idrule(c_id,c_schemaid,c_dataSourcename,c_origcatalog,c_origschema,c_catalog,c_schema,c_rule)
VALUES ('I8a8a9f5a0192bf79bf7978dc0192c19e76550121','SCHEMA.northwind.null','northwind',NULL,NULL,'northwind_for_compatibility','public','ORIGINAL_NO_CATALOG'),
t_schema_idrule,具体表结构如下:
字段名 | 说明 | |||||||||||||||||||||
c_id | uuid 随机生成,保证是表主键唯一即可,如:I8a8a9f5a0192bf79bf7978dc0000000000000001 | |||||||||||||||||||||
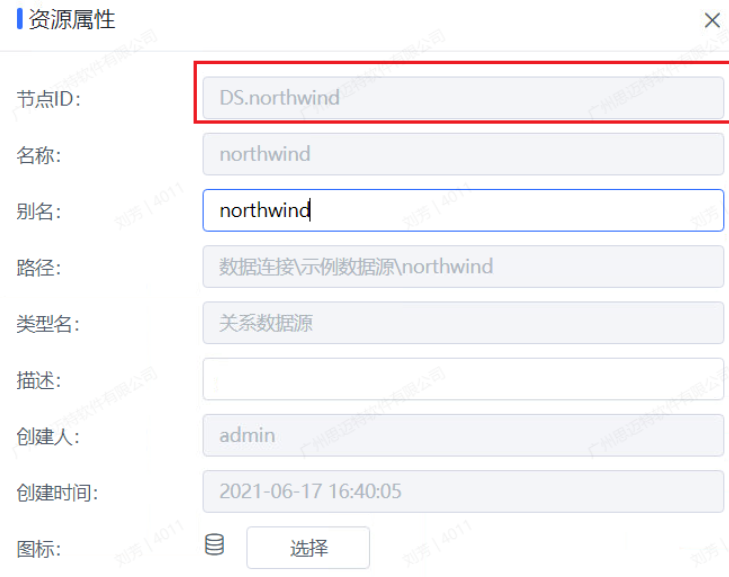
c_schemaid | 对应数据连接下面schema的资源树节点ID,可右键查看节点id属性获取
| |||||||||||||||||||||
c_dataSourcename | 数据源name,可右键数据连接资源查看节点名称属性获取
| |||||||||||||||||||||
c_origcatalog | 原库的catalog、schema。 右键数据连接下面schema的资源树节点,可右键查看节点id属性判断,ID组成有2种情况:
说明 上述null是指真实的NULL值,不是空字符串或字符串“null“ | |||||||||||||||||||||
c_origschema | ||||||||||||||||||||||
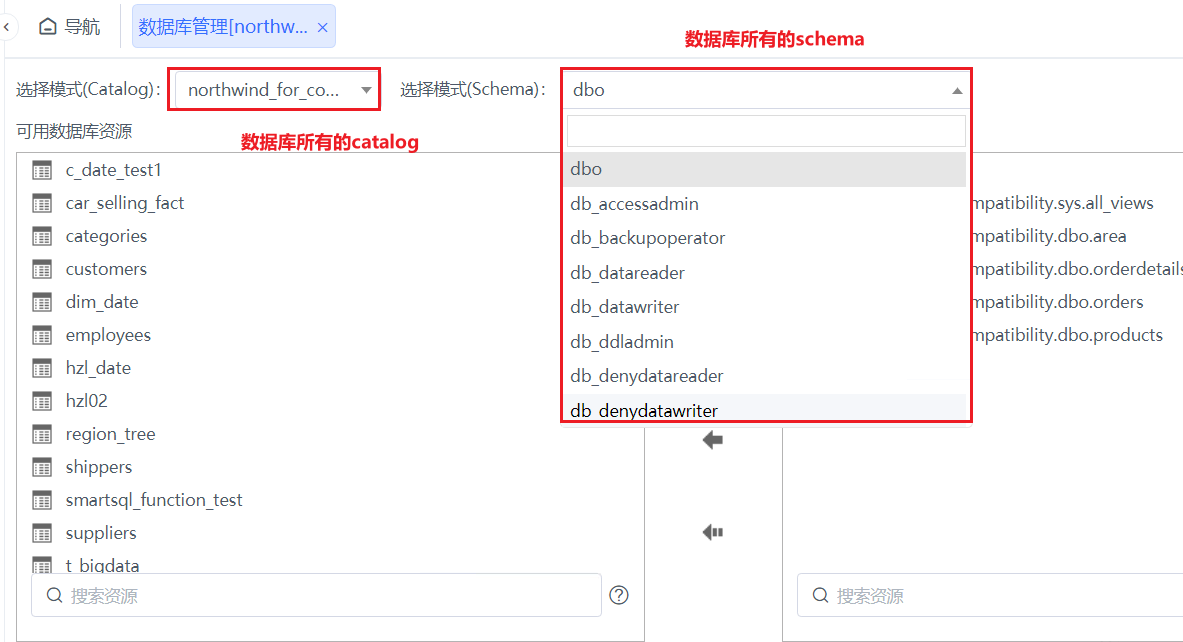
c_catalog | 当前数据源的catalog、schema 可以打开数据库管理界面,可以查看当前数据库的catalog、schema对象,根据数据库切换前后的实际数据库结构选择catalog、schema设置 通常数据库管理界面后默认选中的catalog、schema就是默认值
部分数据库不支持schema和catalog,需要设置为:null 如果数据库不支持catalog,无法获取到catalog列表,界面会自动隐藏选择catalog的下拉控件; 如果数据库不支持schema,会默认 | |||||||||||||||||||||
c_schema | ||||||||||||||||||||||
c_rule | 产品内置6种ID规则。规则说明:
| |||||||||||||||||||||

3、把所有的schema节点,插入了知识库之后,可以检查一下表预览数据、数据集、数据模型等是否正常查询数据。
3 不支持的情况及注意事项说明
1、旧资源(没有支持catalog即V11之前创建的资源,)同一schema下存在多个不同的catalog值,只能选中一个进行替换处理,无法同时支持多个
历史旧ID资源所有的catalog为null,产品支持catalog后,有部分表数据库管理新添加或移除保存后又重新加入,catalog会更新为实际值,这样就会出现旧资源多个catalog的情况
检查方式:可以通过下面sql语句在知识库中查看:
select distinct c_catalog from t_basictable where c_datasrcid = 'DS.northwind' and c_schema = "schema名称"

2、数据模型、自助数据集移除表(表是切换数据库后重新添加的),重新添加表后会丢失原ID
数据模型、自助数据集移除表,重新添加表操作,因为表是切换数据库后重新添加的,会使用实际catalog、schema参与资源字段ID,会发生变化,导致关联的报表报找不对象的问题

3、数据集同步表影响
数据模型只是进行同步表操作,不影响正常使用
自助数据集同步表,操作等同于重新添加表,如果同步的表是切换数据库后重新添加的,会引起找不到对象的问题
4、缓存可能会影响使用,切换数据库和id后建议系统清除缓存
可视化等数据集,默认是自动缓存的,修改了数据库类型,需要清除缓存(清除时需确保数据集不是打开状态),数据集设置了禁用缓存不受影响
5、其他不支持
- SQL查询、sql数据集、参数等用户使用手写SQL部分无法支持。
- 只支持名称统一转为大小写,同时包含大小写的情况,目前暂不支持。



添加评论