示例
使用“银行信用贷款预测”案例数据,共12个特征和1个二类的目标标签,需要预测是否贷款。通过数据预处理及模型训练,如下图:
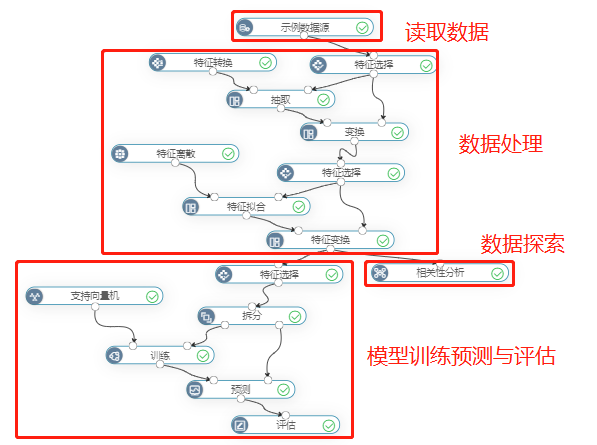
其中,数据探索是为了解各变量之间的相关关系,方便之后数据分析中参数特征的设定;特征转换是为了将各变量中的类别型变量变换成数值型变量,类别型无法进入模型,转换后方便算法模型学习;特征离散是把连续特征分段,每一段内的原始连续特征无差别的看成同一个新特征,是为了提高模型的准确度,提高运行速度。
模型构建中,支持向量机的各个参数:
参数名称 | 值 | 说明 |
|---|---|---|
归一化 | 正则化 | 详情请参考 归一化 介绍说明。 |
标准化 | ||
最小最大值归一化 | ||
最大绝对值归一化 | ||
最大迭代数 | 参数范围为:>=1的整数,默认值为10 | 算法的最大迭代次数,达到最大迭代次数即退出。 最大迭代次数的值越大,模型训练更充分,但会耗费更多时间。 |
正则参数 | 参数范围为:>=0的数,默认值为 :0。 | 正则项系数,损失函数中的 。 正则化可以解决模型训练中的过拟合现象; 正则项系数越大,模型越不会过拟合。 |
收敛阈值 | 参数范围为:>=0的数,默认值为 :0.000001。 | 收敛误差值。 收敛误差值,当损失函数取值优化到小于收敛阈值时停止迭代。 |
分类阈值 | 参数范围为:0~1。默认值为:0.5。 | 在二进制分类中设置阈值thresholds。 如果模型预测结果为分类标签1的估计概率>thresholds,则预测为1,否则为0。高阈值是鼓励模型更频繁地预测0,反之则预测为1。 |
自动调参设置 | 系统默认的各项参数值范围。 | 必须结合“启用自动调参”功能使用。系统将对这些范围内的参数值循环调参,匹配出最优的组合。若运行速度比较慢,可将参数范围调小点。 启用自动调参: 勾选该项,则系统自动调参数,不需要用户手工设置参数。 |
右键单击评估节点,选择查看分析结果,如下图:


F1分数决定模型效果的程度,F1值越大,说明模型预测的效果最佳。这里f1值为0.82。说明该模型效果还是不错的。效果不理想的化还可以继续调优模型。
梯度提升决策树
概述
梯度提升决策树原理是训练多棵CART分类树,每棵树建立是基于前一课树的残差,不断的迭代拟合前一课树的残差,通过损失函数的负梯度来拟合,直到残差达到最小。
示例
使用“银行零售客户流失”案例数据,包含17个特征列和1个二类的目标标签。需要对银行客户预测是否流失。通过数据预处理及模型训练,如下图:
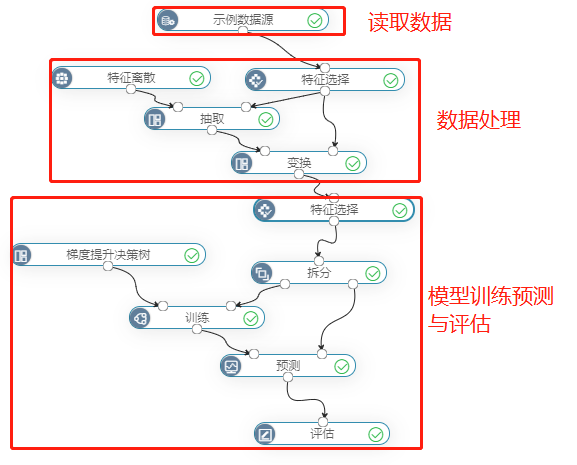
其中,特征离散是将年龄、卡龄等数据离散化,是为了提高模型的准确度,提高运行速度。
模型构建中,梯度提升决策树的各个参数:
参数名称 | 值 | 说明 |
|---|---|---|
归一化 | 正则化 | 详情请参考 归一化 介绍说明。 |
标准化 | ||
最小最大值归一化 | ||
最大绝对值归一化 | ||
最大迭代数 | 取值范围:>=0的整数,默认值为30 | 算法的最大迭代次数,达到最大迭代次数即退出。 最大迭代次数的值越大,模型训练更充分,但会耗费更多时间。 |
分裂特征的数量 | 取值范围:>=2的整数; 默认值:32。 | 对连续类型特征进行离散时的分箱数; 该值越大,模型会计算更多连续型特征分裂点且会找到更好的分裂点,但同时也会增加模型的计算量; |
树的深度 | 取值范围:[1,30]的整数;默认值为4。 | 当模型达到该深度时停止分裂; 树的深度越大,模型训练的准确度更高,但同时也会增加模型的计算量且会导致过拟合; |
学习率 | 取值范围:(0,1]的数;默认为空。 | 收敛步长,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。较小的步长意味需要更多的迭代次数。 学习率决定了参数移动到最优值的速度快慢。如果学习率过大,很可能会越过最优值;反而如果学习率过小,优化的效率可能过低,长时间算法无法收敛。 |
子采样比例 | 取值范围:(0,1]的数;默认为空。 | 对样本进行不放回的采样比例,取值为(0,1],取值小于1,则不使用全部样本去构建GBDT的决策树,小于1的比例,可减少方差,防止模型过拟合,默认是1,即不使用子采样。 |
最小分裂信息增益 | 取值范围:>=0的整数,默认值为空 | 这个值用来限制决策树的增长,如果某节点的信息增益小于这个阈值,则该节点不再生成子节点。 |
子节点最少样本数 | 取值范围:>=1的整数,默认值为空 | 这个值用来限制叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 |
自动调参设置 | 系统默认的各项参数值范围。 | 必须结合“启用自动调参”功能使用。系统将对这些范围内的参数值循环调参,匹配出最优的组合。若运行速度比较慢,可将参数范围调小点。 启用自动调参: 勾选该项,则系统自动调参数,不需要用户手工设置参数。 |


