示例
使用“垃圾短信识别”案例数据,预测是否为垃圾短信。
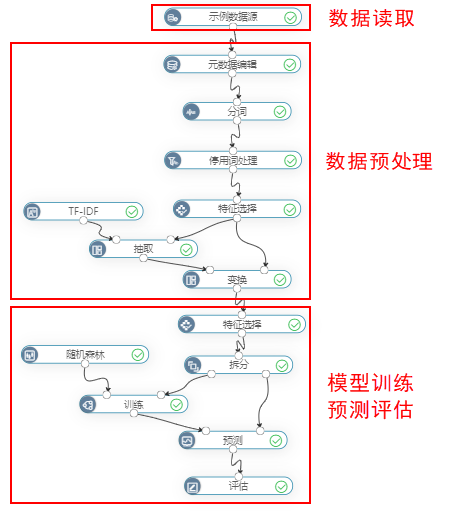
其中,分词是为了将短信文本进行分成词语方便分析;停用词处理是为了去除不必要的词语、标点符号、语气词等;TF-IDF是为了计算文本数据的idf值,方便进入模型训练。
参数设置
随机森林的参数如下:
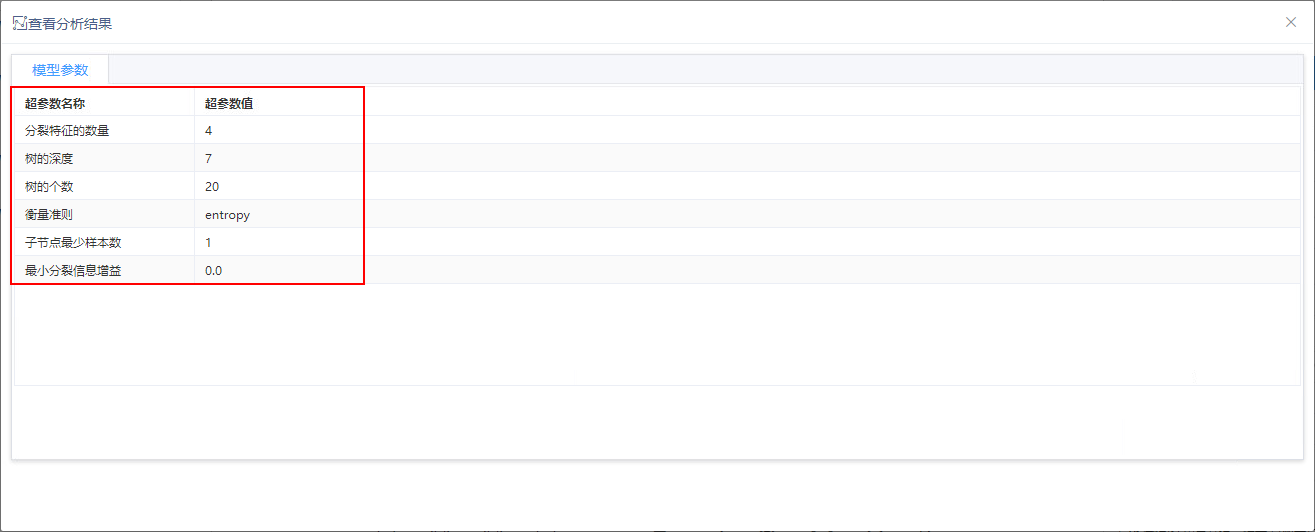
参数名称 | 值 | 说明 |
|---|---|---|
自动调参设置 | 系统默认的各项参数值范围。 | 必须结合“启用自动调参”功能使用。系统将对设置指定或范围内的参数值循环调参,匹配出最优的组合。详情请参考 自动调参设置 。 |
启用自动调参 | 勾选该项,则系统自动调参数,不需要用户手工设置参数。 | |
分裂特征的数量 | 取值范围:>=2的整数; 默认值:32。 | 对连续类型特征进行离散时的分箱数; 该值越大,模型会计算更多连续型特征分裂点且会找到更好的分裂点,但同时也会增加模型的计算量; |
树的深度 | 取值范围:[1,30]的整数;默认值为4。 | 当模型达到该深度时停止分裂; 树的深度越大,模型训练的准确度更高,但同时也会增加模型的计算量且会导致过拟合; |
树的个数 | 取值范围:大于等于1且小于等于500的整数,默认值为20。 | 随机森林中决策树的棵数。 |
衡量准则 | gini | 裂分标准,Entropy表示熵值,Gini表示基尼指数; |
entropy | ||
子节点最少样本数 | 取值范围:大于0且小于等于1000的整数 | 每次分裂后每个子节点必须拥有的样本数; 该值越大,决策树允许分裂的次数就越少。可以防止模型过拟合; |
最小分裂信息增益 | 取值范围:[0, 10000] | 每次分裂必须达到的信息增益; 该值越大,决策树允许分裂的次数就越少。可以防止模型过拟合; |
分类阈值 | 参数范围为:[0,1]。默认值为:0.5 | 在分类中设置分类阈值thresholds。 如果模型预测结果为分类标签1的估计概率>thresholds,则预测为1,否则为0。高阈值是鼓励模型更频繁地预测0,反之则预测为1。 多分类请用英文逗号隔开,且数量与分类数相同,例如:分三类,示例:8,9,10 |
自动调参设置
系统将对设置指定或范围内的参数值循环调参,匹配出最优的组合。
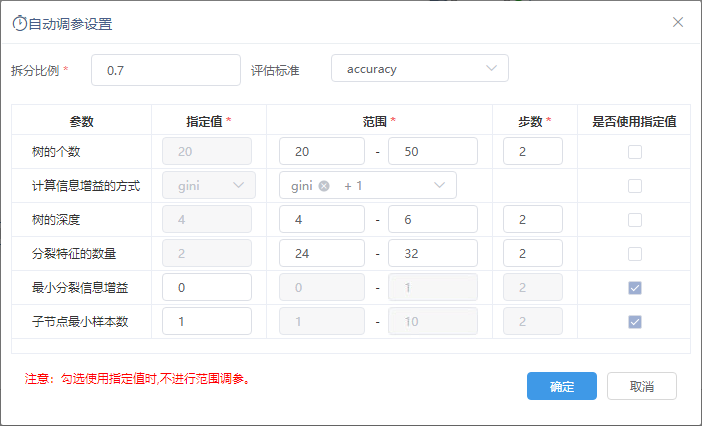
自动调参的方式分为两种:
- 指定值调参:指定一个固定的值进行自动调参。
- 范围调参:在指定的范围内进行自动调参。
设置项说明如下:
设置项 | 说明 | |
|---|---|---|
拆分比例 | 将选择的数据拆分为两部分,一部分部分用于模型的评估,另一部分数据用于训练模型。 | |
评估标准 | 用于选择数据的评估指标,包括:f1、precision、recall、accuracy、AUC(二分类)。 其中,评估标准“AUC(二分类)”仅对二分类问题生效。 | |
参数 | 自动调参的参数项。
注意:
| |
指定值调参 | 指定值 | 指定一个固定的值进行自动调参。需要先勾选“是否使用指定值”才能配置。 |
是否使用指定值 | 控制是否使用使用指定值进行调参。 | |
范围调参 | 范围 | 设置自动调参参数的范围。 若运行速度比较慢,可将参数范围调小一点。 |
步数 | 进行范围调参时,在设置的范围内生成多少个参数值。 示例: 1)范围为[3,5],步数为3时,生成的参数值:3, 4, 5 2)范围为[40,100],步数为4时,生成的参数值:40, 60, 80, 100 | |
示例
设置自动调参设置如图:

在训练节点查看分析结果如图: