+
背景介绍
功能简介
+【加载文件数据】支持导入文件到Sybase IQ数据库
背景介绍
众所周知,Sybase IQ 数据库在大数据量的管理上有较大的性能优势,在新版本的加载文件数据功能中,我们支持导入到Sybase IQ数据库,不仅给用户带来的更大的灵活性,也能帮助用户在分析本地大数据量文件的场景中提高分析效率。
功能简介
在【加载文件数据】中支持文件导入Sybase IQ数据库。


详情参考
详情参考:加载文件数据
+【加载文件数据】支持导入包含多个Sheet页的数据文件
功能概述
新版本,支持导入包含多个Sheet页的数据文件,简化用户操作方式,提高了工作效率。


^
背景介绍
功能简介
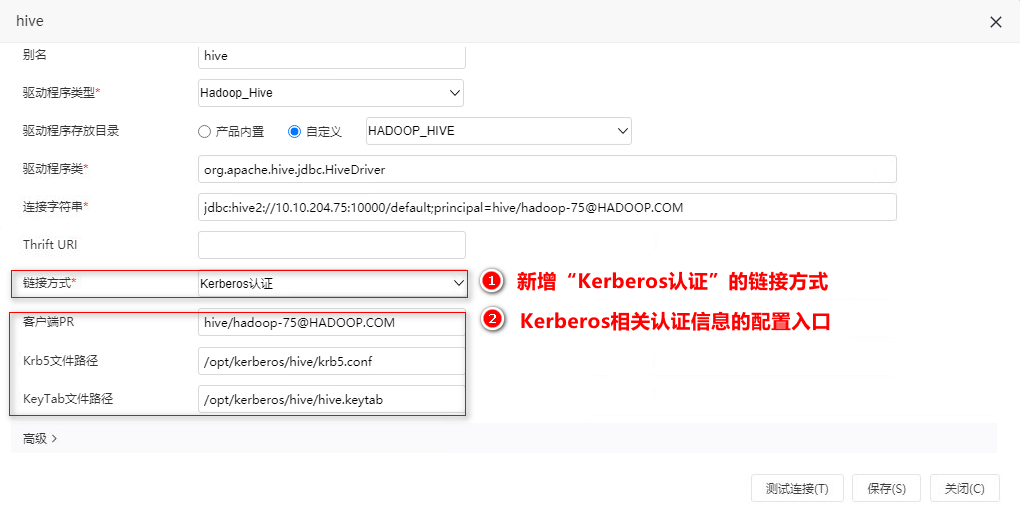
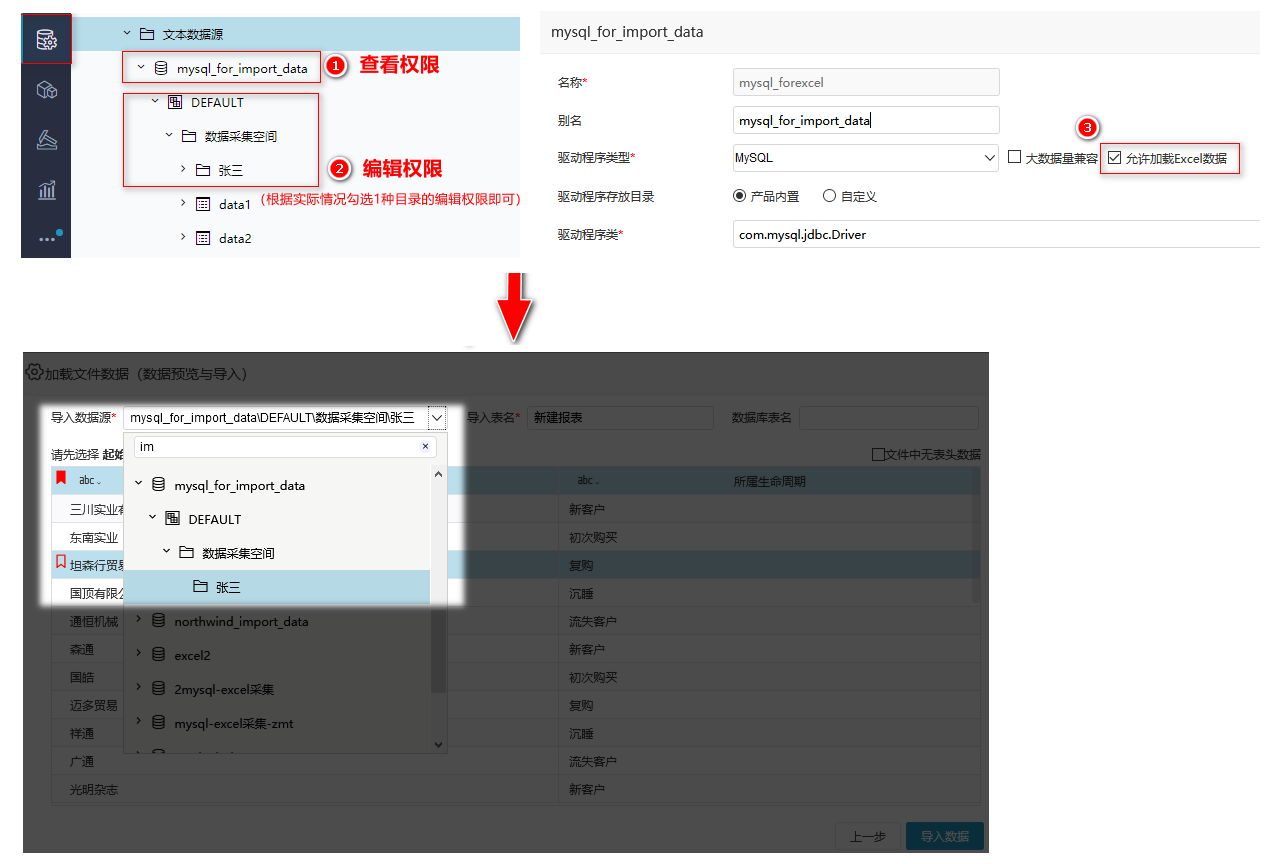
如需对数据源允许用户导入数据文件,除了需要我们在数据源设置方面勾选 '允许加载Excel数据'(高速缓存库无需勾选) ,新版本要求在权限方面只需满足两个条件:
一是
优化删除数据采集个人目录时的判断逻辑
^【加载文件数据】优化加载文件数据导入设置表头功能
背景介绍
在使用【加载文件数据】的设置表头功能时,产品默认以首行作为表头,在以前版本中鼠标移动到其他行便容易将其作为表头;但通常情况下表头是无需频繁修改,为了避免上述的误操作,新版本我们是通过点击表头图标方式来设置表头,以此提升用户体验。
功能简介
在加载文件数据中,取消单击选中行作为表头的功能,改为点击 设为表头 ![]() 按钮,设置任意行为表头。
按钮,设置任意行为表头。

<【数据源】优化数据源编辑和导入数据文件权限
背景介绍
旧版本中使用文本数据源,导入Excel数据到指定数据库时,需要授予用户数据源的编辑权限,而授权后,用户就能够对该数据源进行修改或删除,这样会导致用户误删除或修改数据源的灾难性操作;为了避免这种情况,新版本对数据源编辑和导入数据文件权限进行了优化处理。
功能简介
在操作权限上,数据源权限和导入数据文件权限进行了如下区分:
- 数据源:用于控制数据源连接的操作权限。
- 文本数据源:用于控制导入数据文件的操作权限。
在权限控制上进行了如下调整:
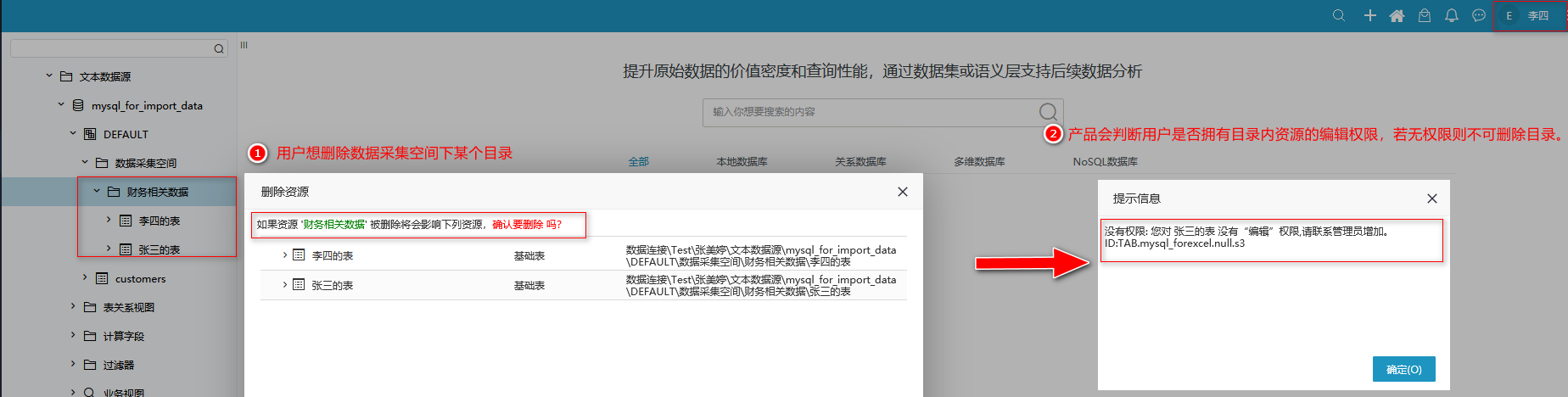
1、数据采集空间目录调整:
- 数据采集空的资源所有者为:系统服务;保持原有的资源授权设置(everyone 有编辑权限);
- 数据采集空间下创建的目录默认不继承父项权限;
- 用户对目录的子孙节点无删除权限,不允许用户删除该目录;
2、导入数据权限判断:用户同时拥有:数据源的查看权限、shema或目录的编辑权限,才允许在导入数据源的下拉框中才能显示该数据源。如下图所示:
参考文档
<【数据源】对数据源摆放顺序优化
背景介绍
为了方便用户迅速搜索、创建到相应的数据库连接,新版本中我们对各类数据库的显示顺序进行优化。
功能简介
1、【常用数据库】依据整个系统中创建数据库次数,给用户提供的热门数据库信息。
2、其他分组标签页的数据库(所有数据库、本地数据库、关系数据库、多维数据库、NoSQL数据库)则按字母顺序排序。

注意事项
Other数据源不按字母排序,位置在所有数据库或关系数据库最后。


