概述
LSH(局部敏感哈希)是一种哈希算法,用于对高维数据进行快速最近邻查找。LSH把两个高相似度的数据以较高的概率映射成同一个哈希值,把两个相似度很低的数据以较低的概率映射成同一个哈希值。利用哈希过后的数据进行最近邻查找,能提高查找效率,减少耗时。
对于数据向量的相似度距离,LSH节点提供了两种距离度量:欧式距离和杰卡德距离。其中,欧式距离适用于绝大多数数据向量,而杰卡德距离适用于由0和1组成的向量(如,00101,10011等,非0的数值都会被视为1)。在文本分析问题中,可先使用词向量或TF-IDF把文本转换为数值型向量,再选用欧氏距离的LSH对向量进行哈希,哈希后的向量可用于相似度匹配。
输入/输出
输入 | 没有输入端口。 |
|---|---|
输出 | 一个输出端口,与抽取、变换节点组合使用。 |
参数设置
参数名称 | 说明 | 备注 |
|---|---|---|
相似度计算方法 | 相似度距离度量 | 欧式距离和杰卡德距离 |
哈希存储桶的长度 | 每个哈希表内的哈希桶的长度,长度更长能降低假阴率 | 只适用于欧氏距离 |
哈希表数量 | 哈希表的数量 | 哈希后向量的长度 |
示例
效果
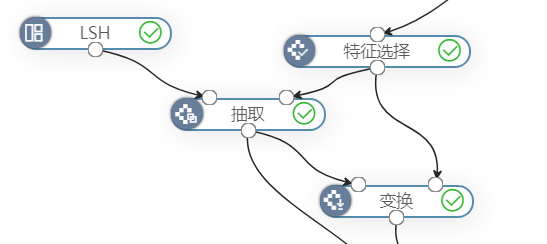
使用词向量算法把文本转换为向量后,选择该向量列。使用LSH算法,设置哈希表数量为4,输出结果如下图: