类似经营分析模型,一个模型接入100张表很正常,并且最终查数据库的SQL是根据用户查询意图动态构建,无法一开始知道最终查询SQL,此时用户查询数据时如出现以下疑问,该如何跟踪确认?
在说跟踪方法前,重温下模型的各种特性对数据结果带来的影响,下面以证券类企业可能常见的数据描述模型的基数关系、筛选方向、默认生效的参数、数据行权限、层次结构、数据类型等对数据结果的影响性。
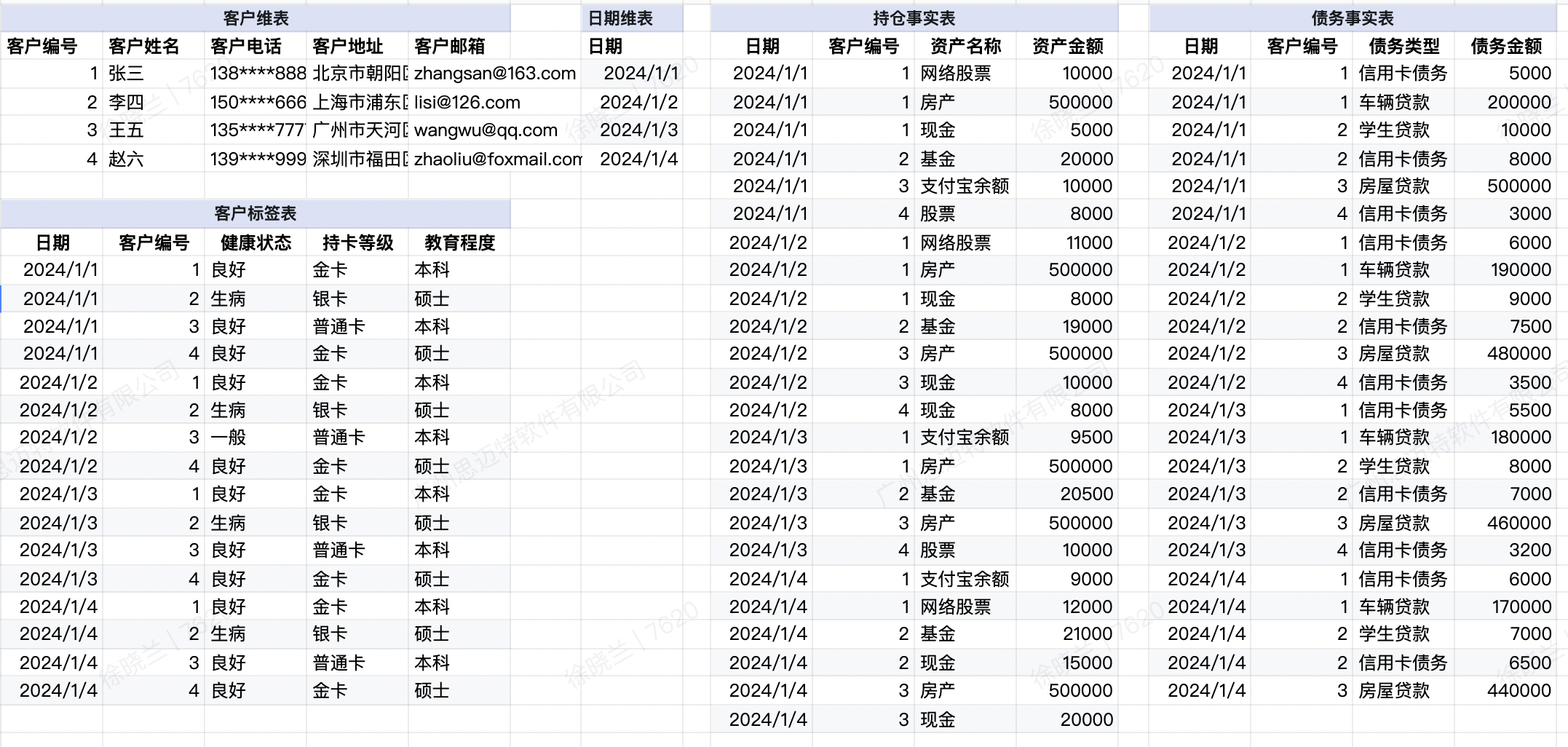
示例数据说明:
1、下图是每个表的示例数据:
2、下图是示例数据关系说明:
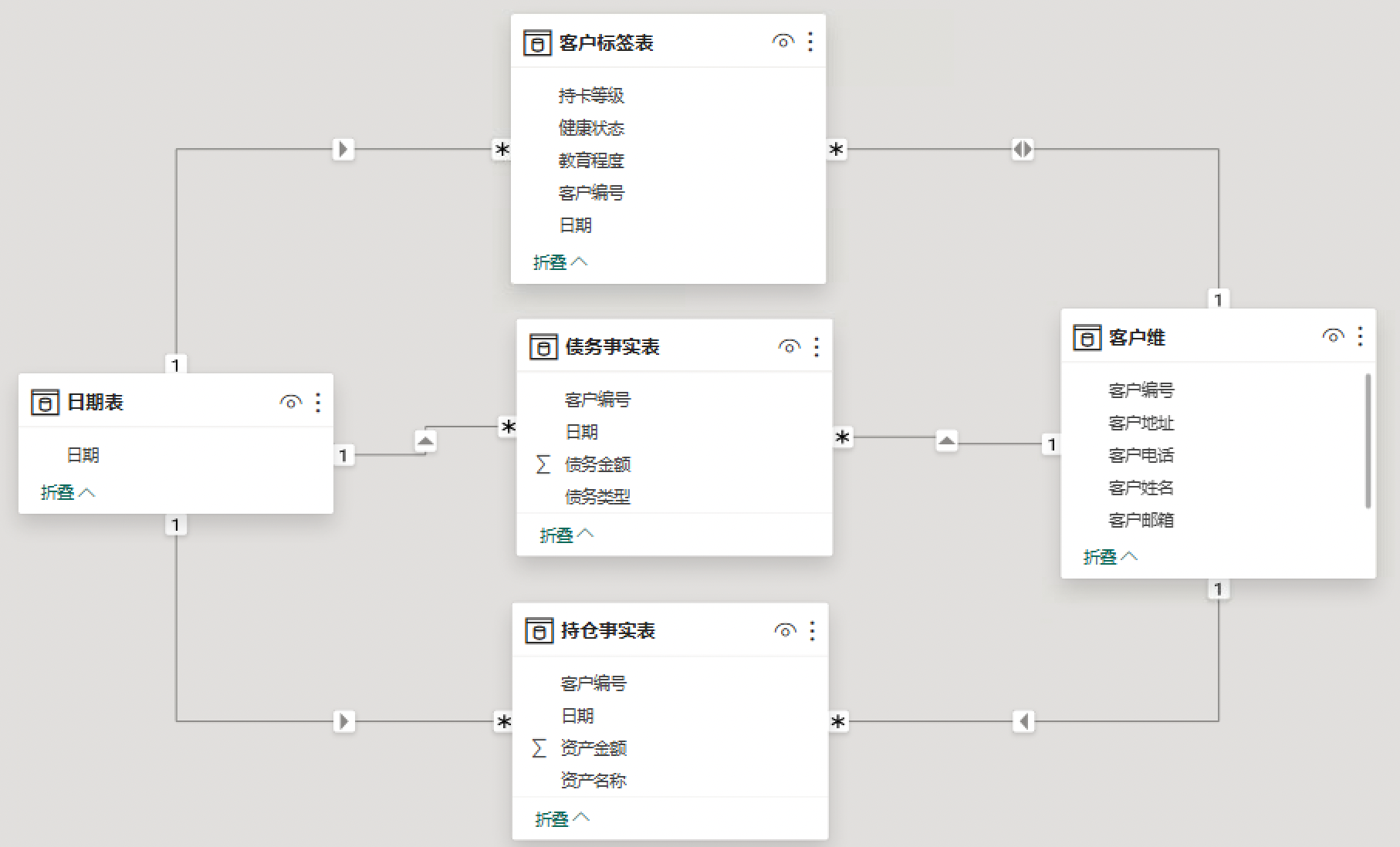
3、下图是基于产品构建的模型:
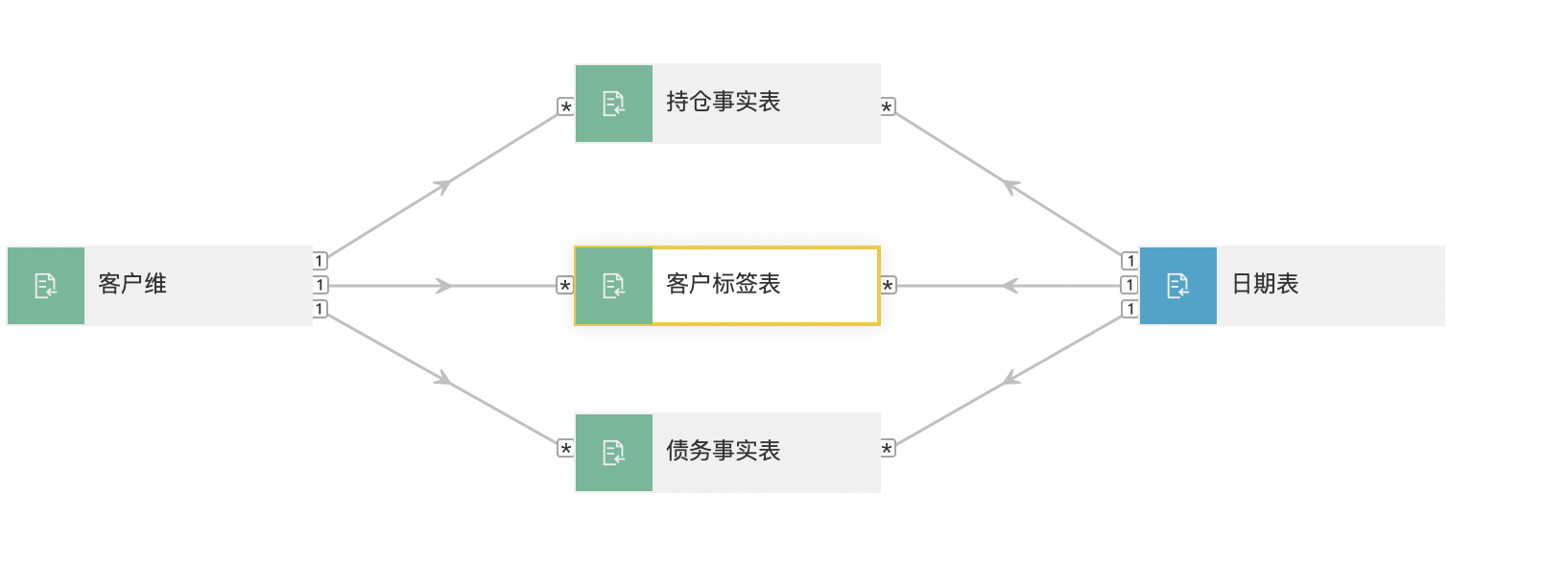
如明明是1对多关系的,设置成多对一,当同时查询两张表的维度,实际为“一”方的指标会被“多”方的放大,如下面客户维度中的客户数,被标签表放大。

下图描述客户标签表如没有设置可筛选客户维表,标签表中的金卡客户就是4,如设置了就是2,后者是符合预期的。

给A表的参数设置默认生效,查询A表或以A表为维表的事实表数据就会带上此参数。
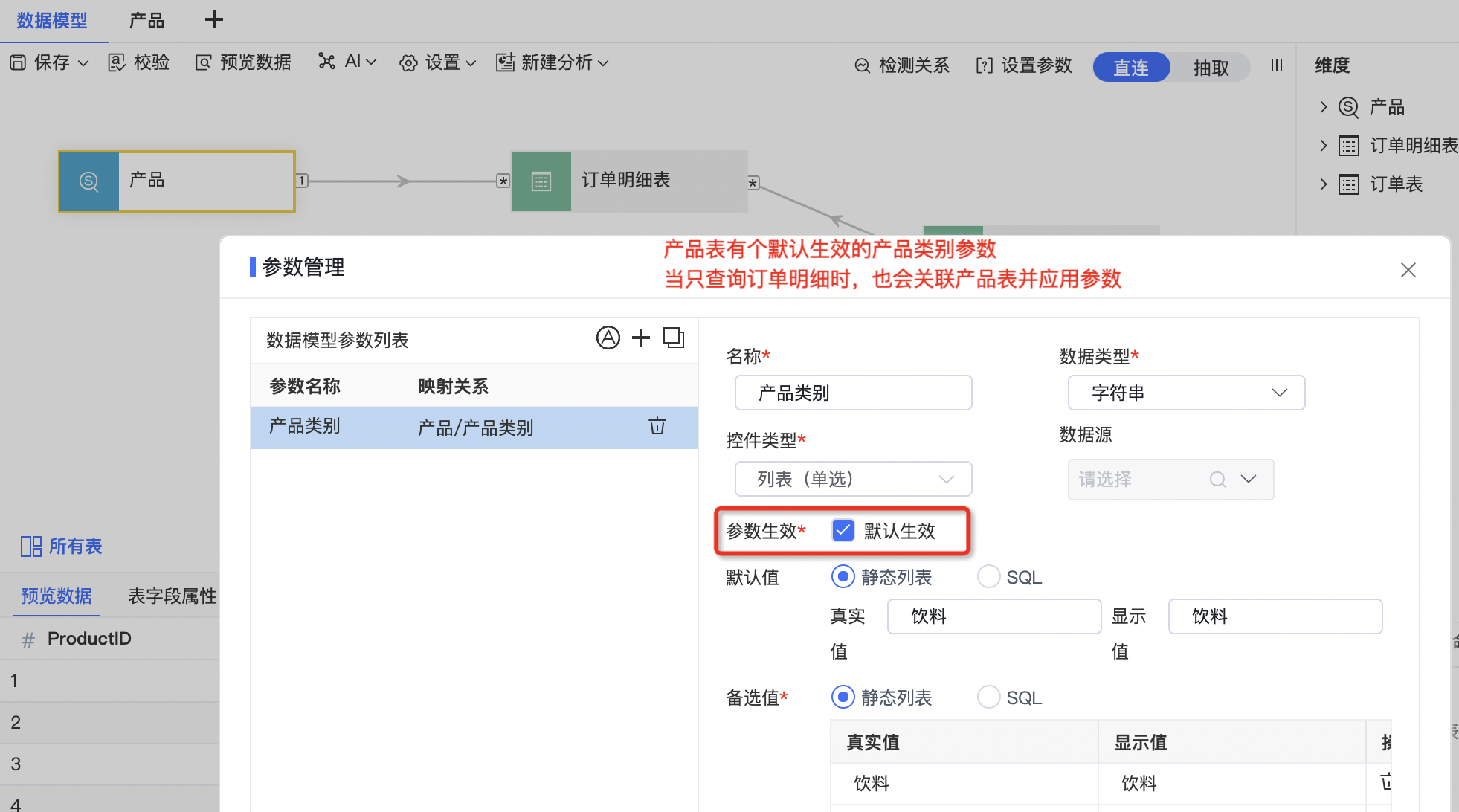
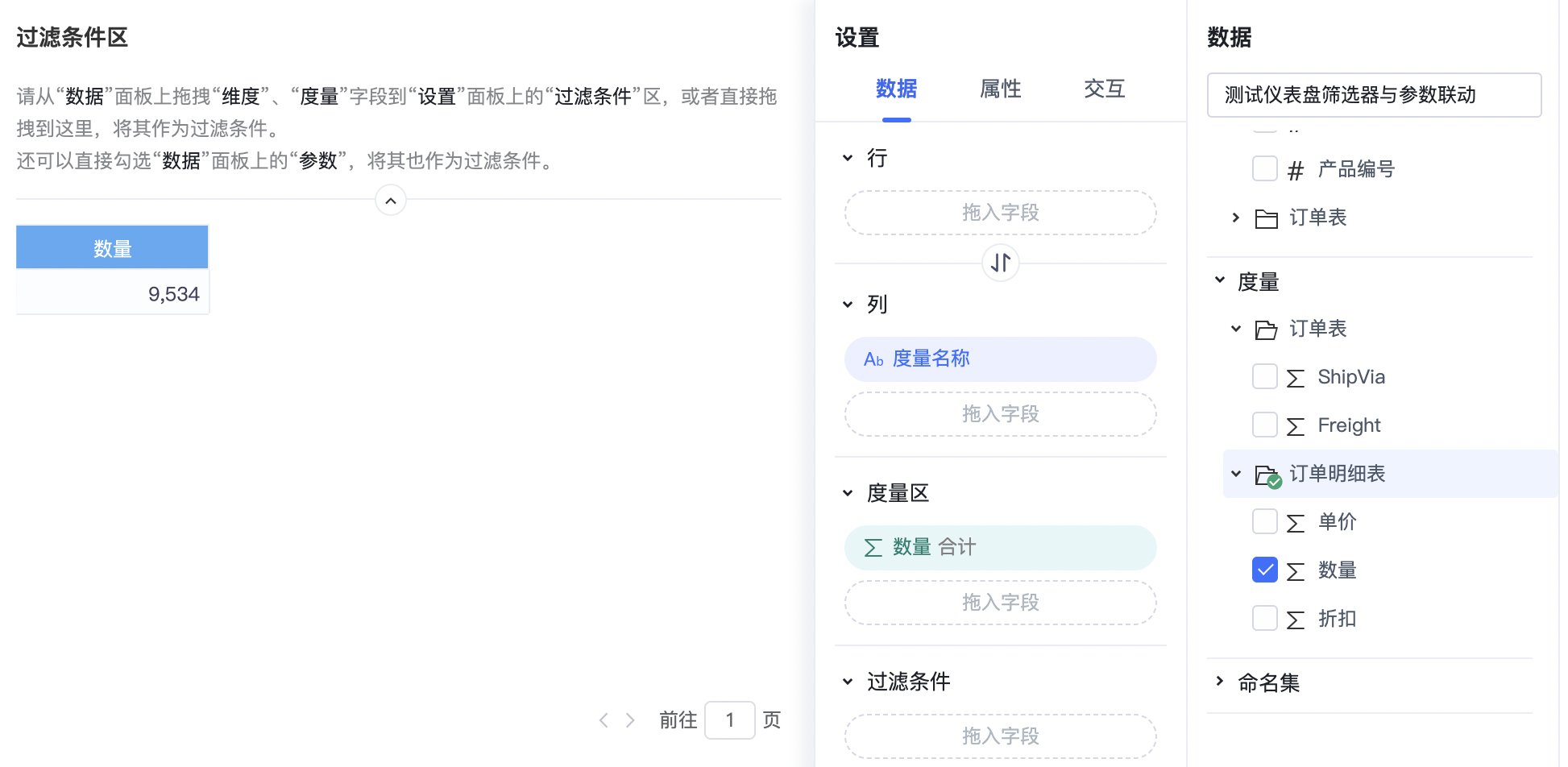
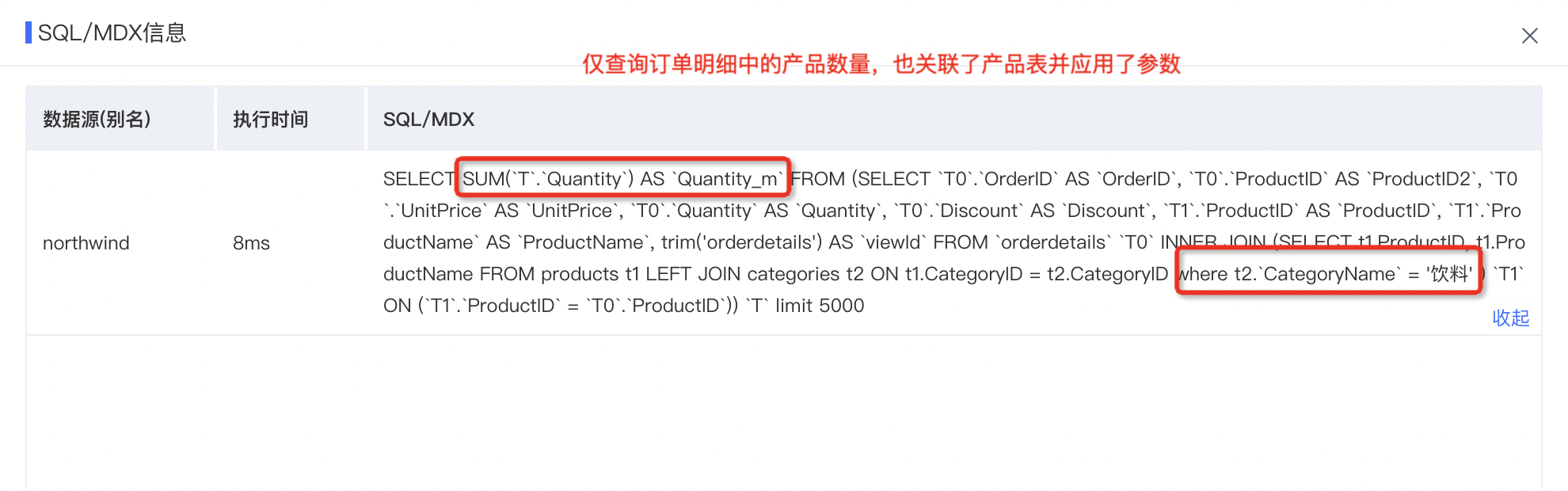
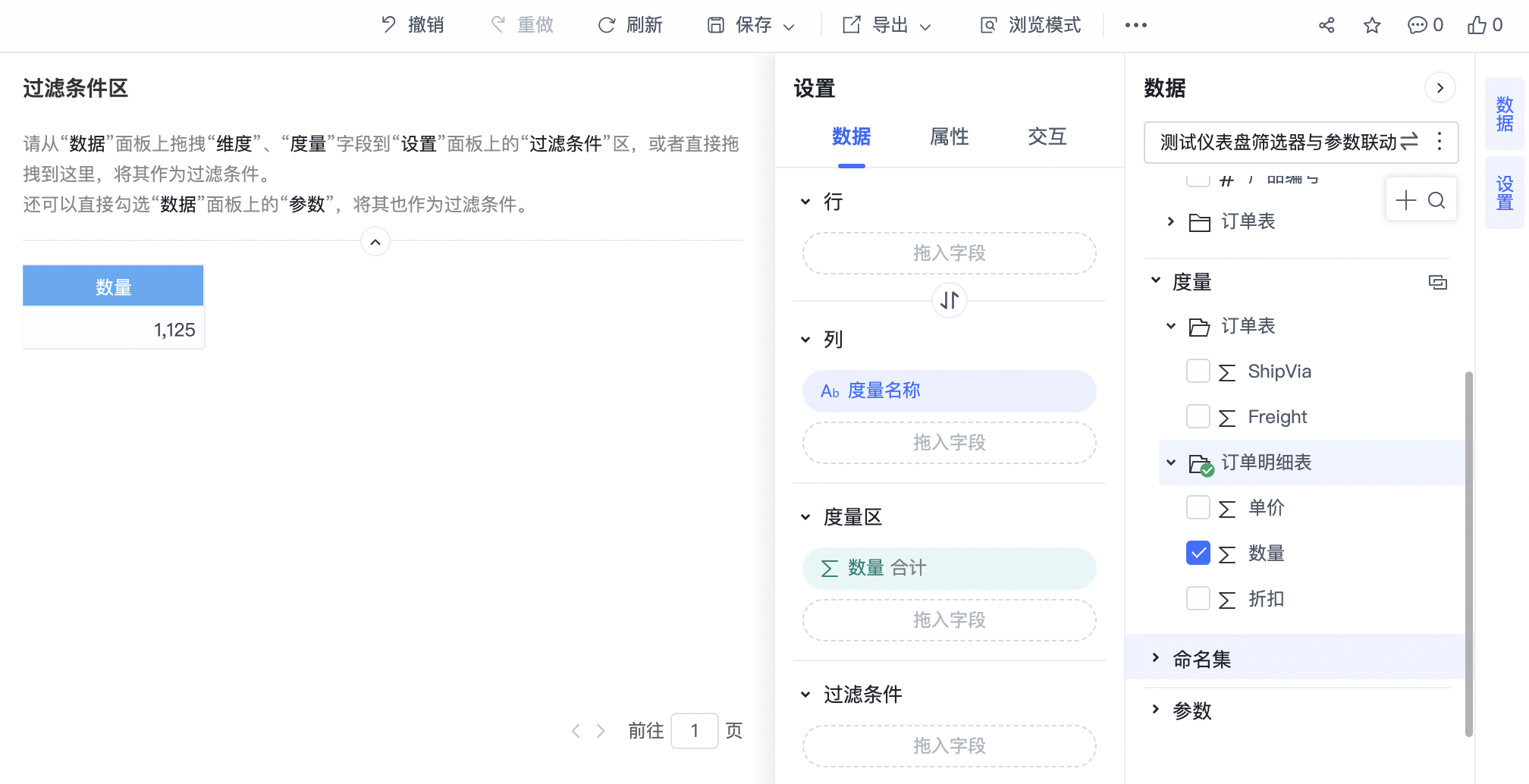
只查询了订单明细表的数量,也会关联产品表并应用参数,否则不会。
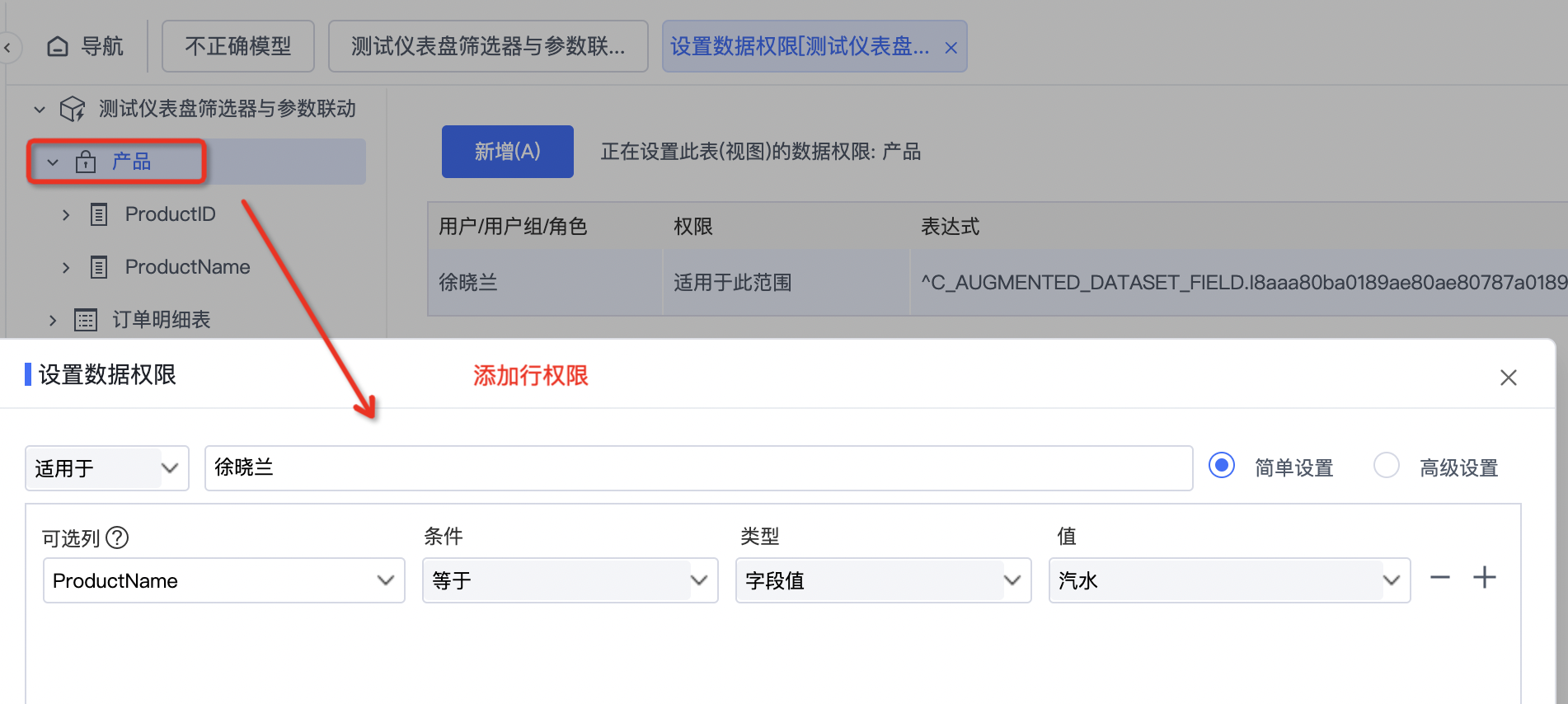
和上面默认生效的参数类似,如果是在数据模型中给A表设置了行权限,或者直连的时候在数据源连接中设置了A表的行权限,查询A表或以A表为维表的事实表时,就会带上行权限限制。
以公司、一级部门、二级部门为例,如果这三个字段在模型中构建了一个层次结构,那么字段的真实值,实际都是带有层次路径的,如下面示例的第一行开发部,实际是:[A].[研发中心].[开发部],所以如果查询一级部门、人数的结果就等同于查询公司、一级部门、人数的结果。

注:SQL引擎目前还不是这个语义,上面示例,如果是SQL引擎,会返回研发中心、132,后续SQL引擎语义会保持和多维一致。
这个通常是原始数据库的字段类型和在模型中设置不一致,如原始库是字符串,在模型中设置为日期,当不满足日期字符串格式查询就会报错,又如原始库是double,在数据模型设置为int就可能让数据精度丢失等等。
这个是系统的后置处理做的,如出现问题可检查相应查询字段的设置,或者元数据的血统分析查看相应的设置。
数据不对,主要可能有以下可能性:
使用问题,数据模型和预期的不符,比如不知道有数据行权限、默认生效的参数、层次结构的概念,或者报表本身复杂不知道他应用了某个筛选器;
数据模型建模存在问题,如上面说的基数关系、筛选方向、数据类型;
系统本身BUG;
原始业务数据存在异常;
不管哪种情况,系统都提供相应的跟踪确认方法,一般建议:
当然如果对系统特性较熟悉,结合前面讲到影响数据的特性,根据问题现象可能可以跳过上面步骤直接确认模型对应的设置是否正确。
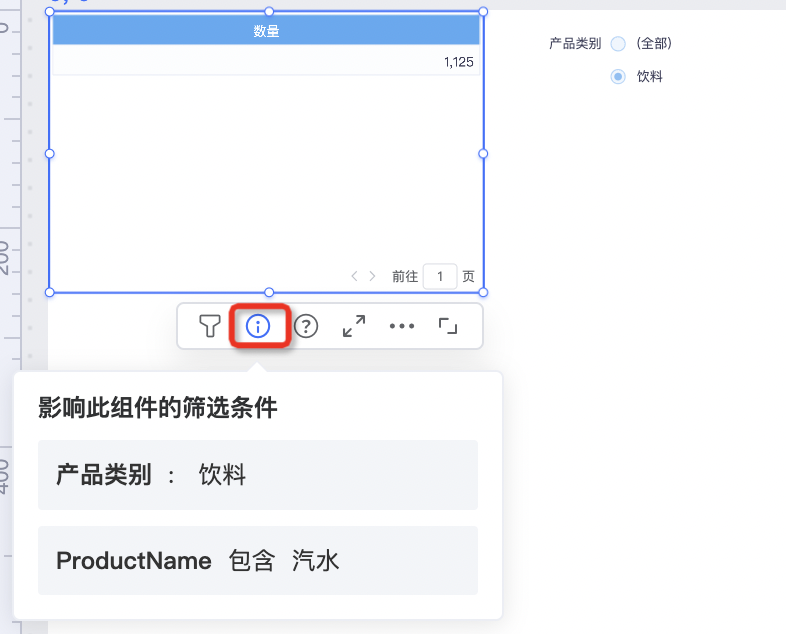
组件工具栏有个查看筛选条件,当一个复杂仪表盘数据不对时可优先查看筛选条件是否正确。
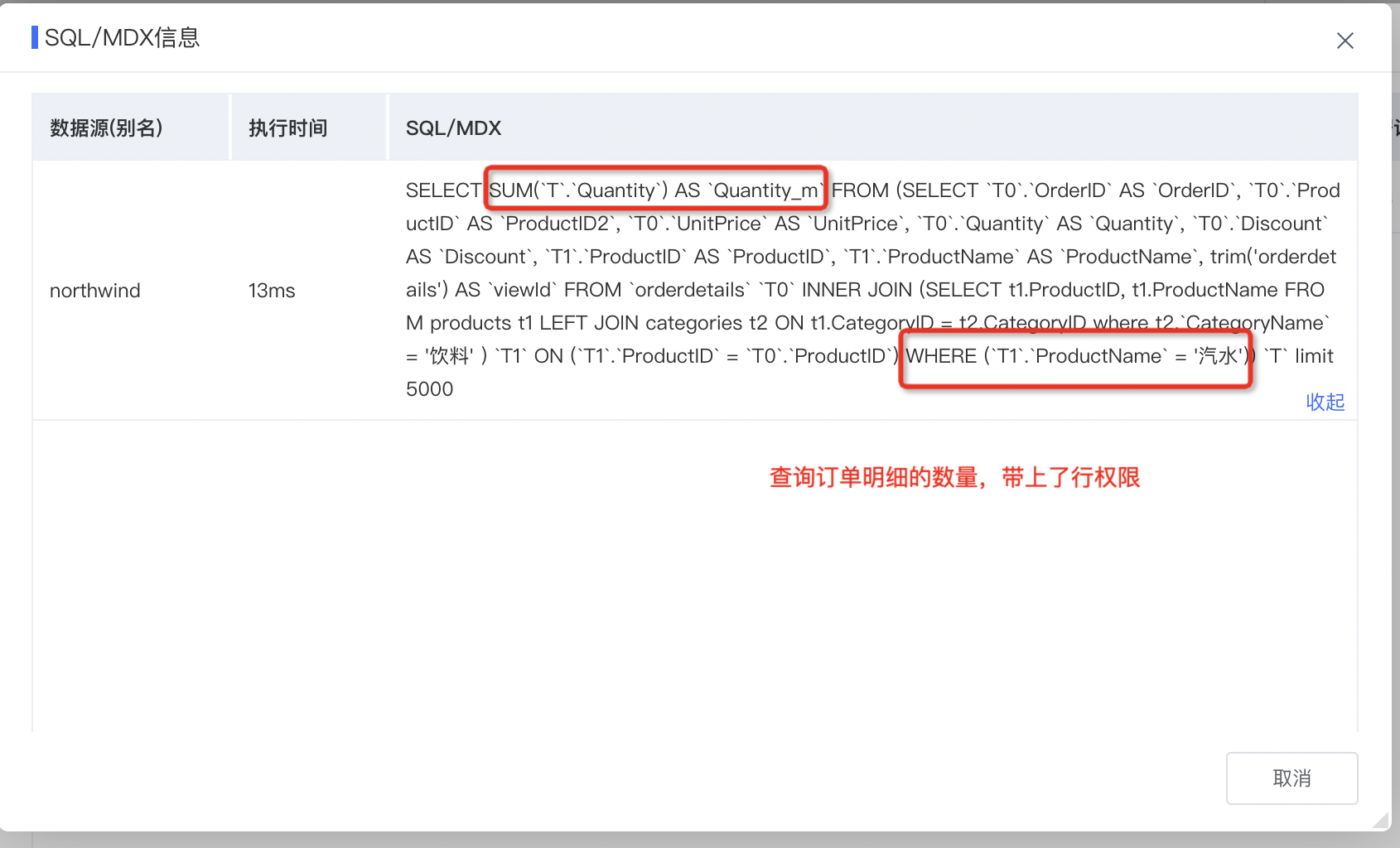
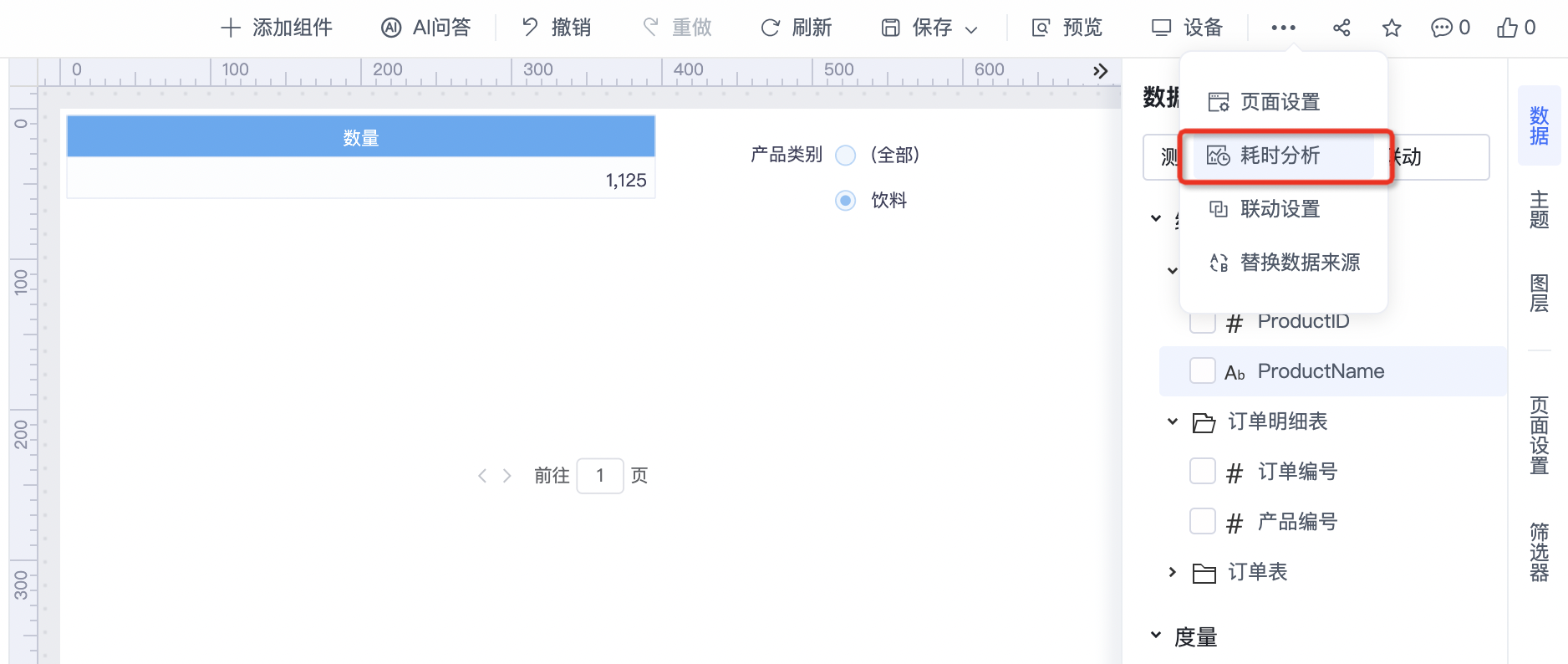
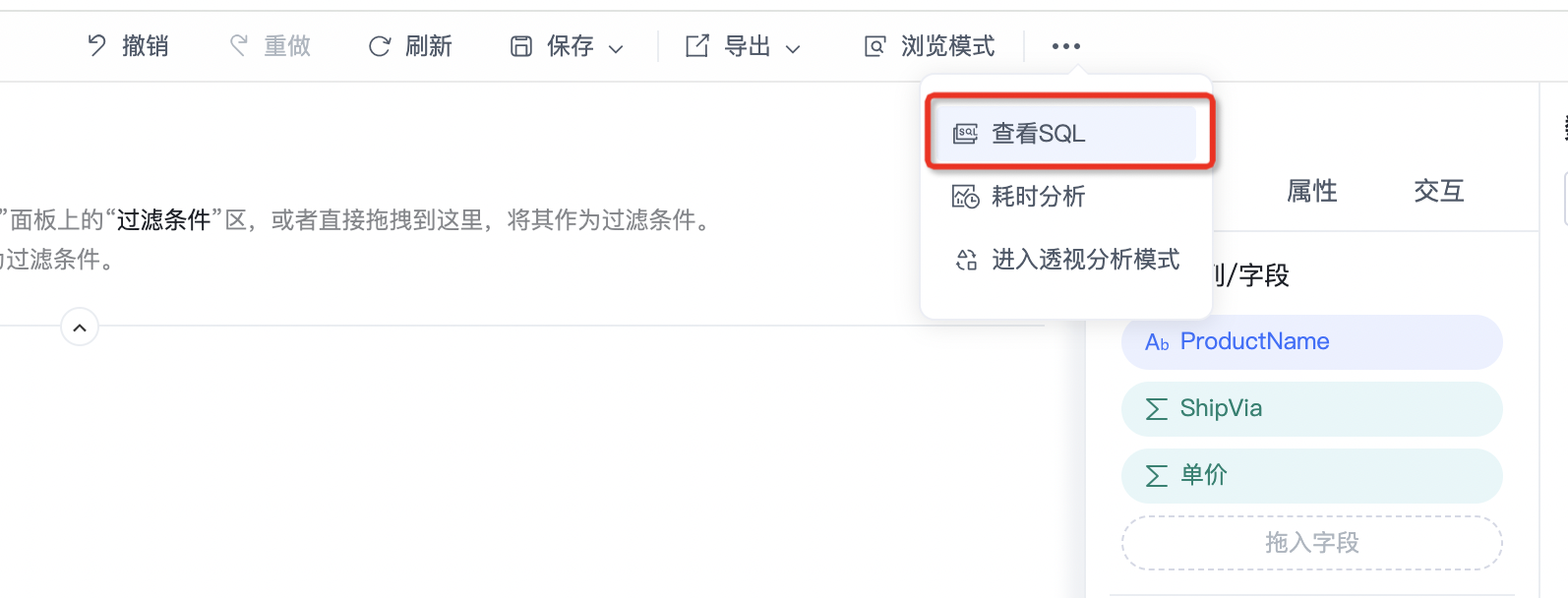
无论是仪表盘、透视分析还是即席查询,工具栏都有个耗时分析,可以直接查询执行的SQL或MDX,如上面仪表盘查看筛选条件未看出问题就可通过耗时分析查看执行SQL反向推测问题可能性。
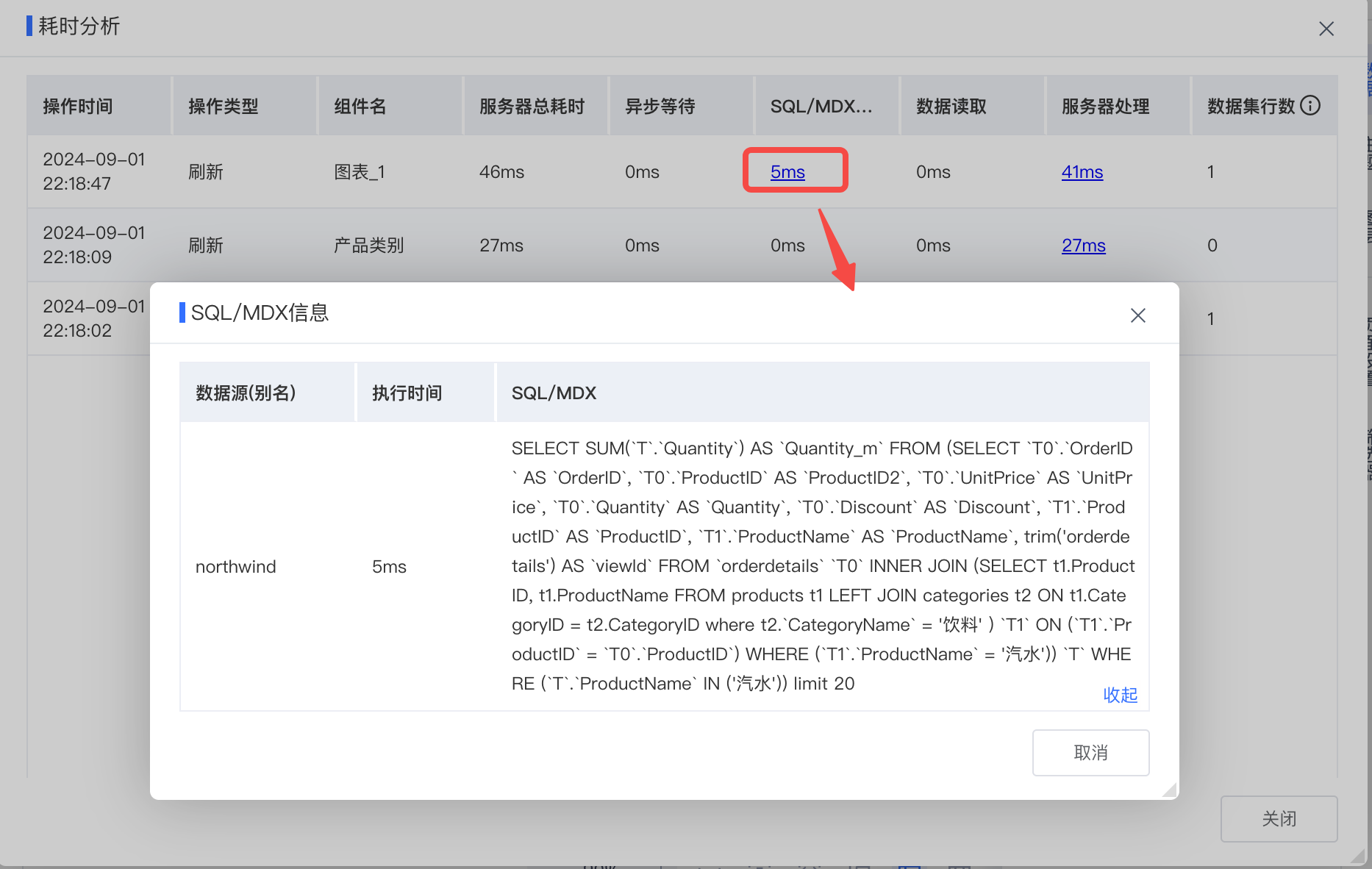
配套小技巧:
1,如果报表工具栏没有耗时分析,需要管理员在系统选项>公共设置开启报表耗时分析;
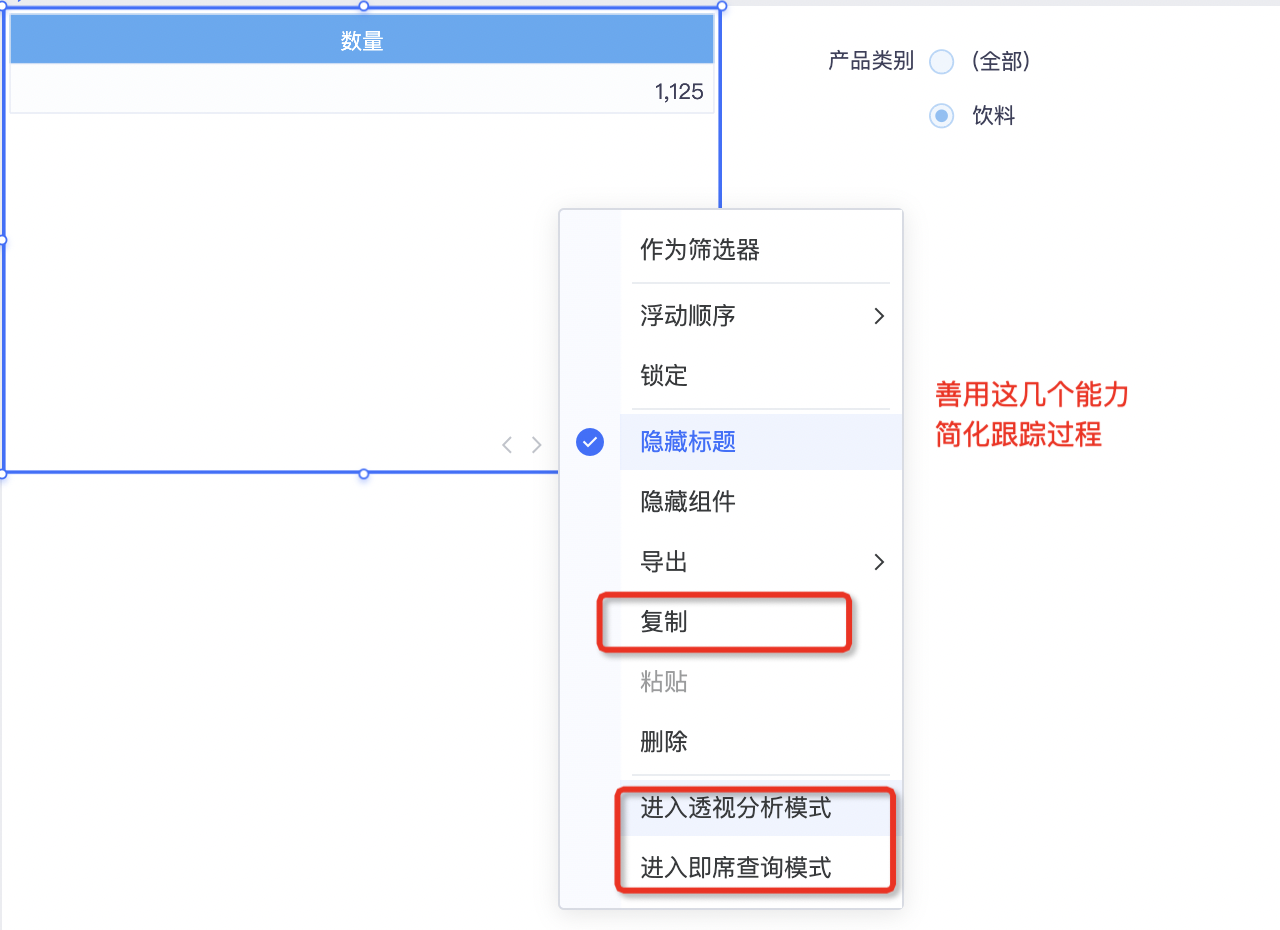
2,如果是复杂仪表盘出现某个组件数据不对,可通过以下途径简化跟踪:右键选中问题组件复制,然后新建一个仪表盘粘贴继续跟踪,或者直接右键进入透视分析模式/即席查询模式进一步跟踪,具体见下图
3,如果是计算度量、命名集等数据不对,能转为检查原子指标/维度的优先转为原子指标/维度,如发现销售额同期值不对,就可先检查对应时间的销售额指标,因为这样可以在耗时分析直接看到执行SQL,否则还需借助MDX查询监控
4,可基于数据模型中“SQL查询”格式化耗时分析中看到的SQL并查询验证数据,当然前提得有SQL查询操作权限
即席查询是查原始数据,如果即席查询生成SQL没错,但查询结果不对,大概率都是原始业务数据不对,当然如果是抽取模式,至少抽取后数据是不对的,又得进一步确认原始业务库数据。
配套小技巧:
1、如果是抽取模型查询不对,还可借助数据模型中的可视化SQL查询能力进一步确认原始业务库数据;
2、即席查询是确认模型原始数据是否正确的小助手,当建完模,不确认数据是否正确,就可借助即席查询或透视分析

如果开启了可视化的耗时监控,实际用不着此能力。
系统监控>MPP表管理。
只有当怀疑MPP表数据不对时有用,通常不用此能力。
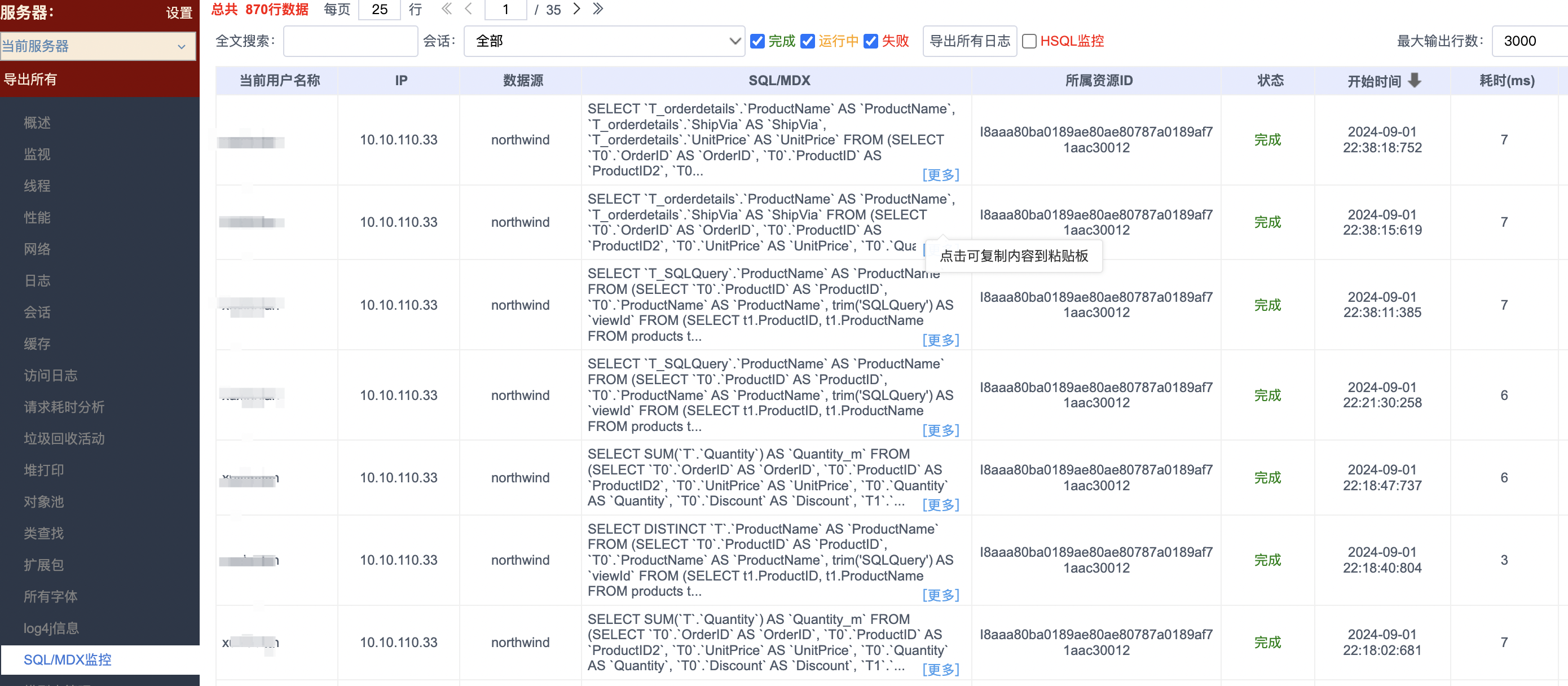
当报表查询时,如果含有计算度量、命名集、计算成员或快速计算等能力时,就会走多维查询,此时可借助多维查询引擎系统监控能力跟踪确认执行MDX和执行SQL,操作方法:系统监控-》服务器切换为olap服务器-》MDX查询监控。
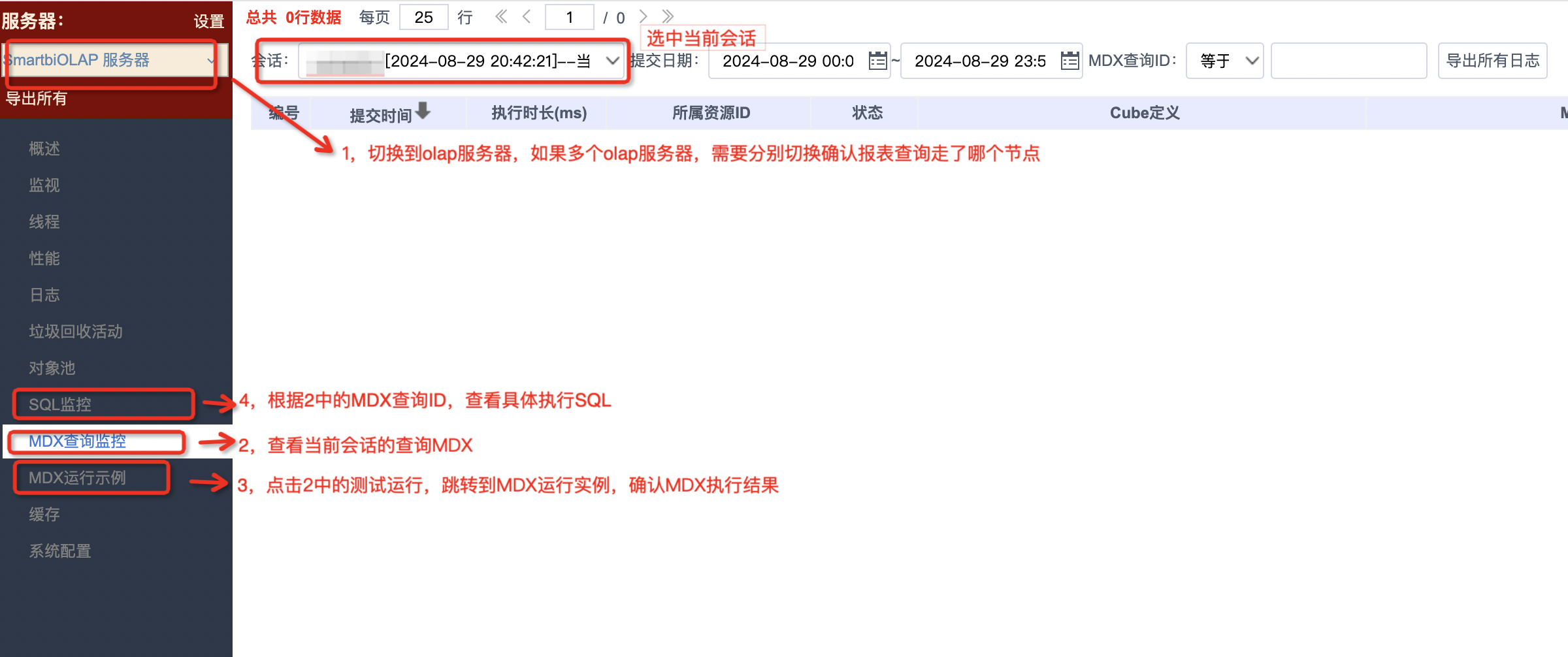
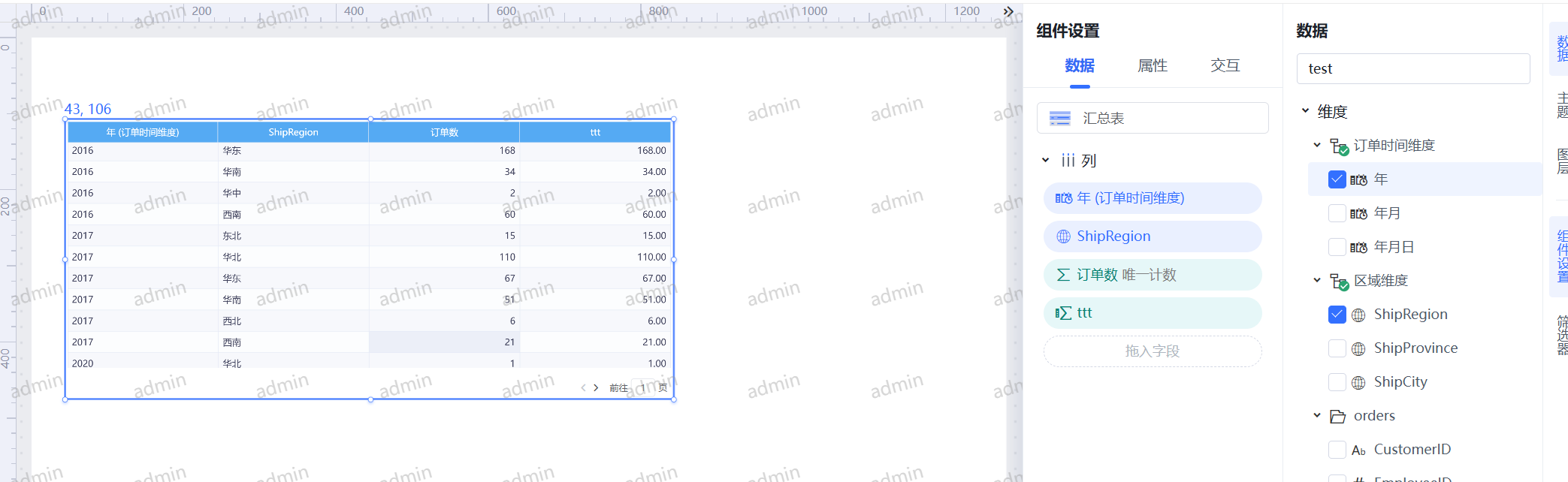
例如:前端执行一个组件查询,勾选了年和区域维度,以及订单数度量(ttt是个计算度量,勾选它的作用是避免走SQL引擎);
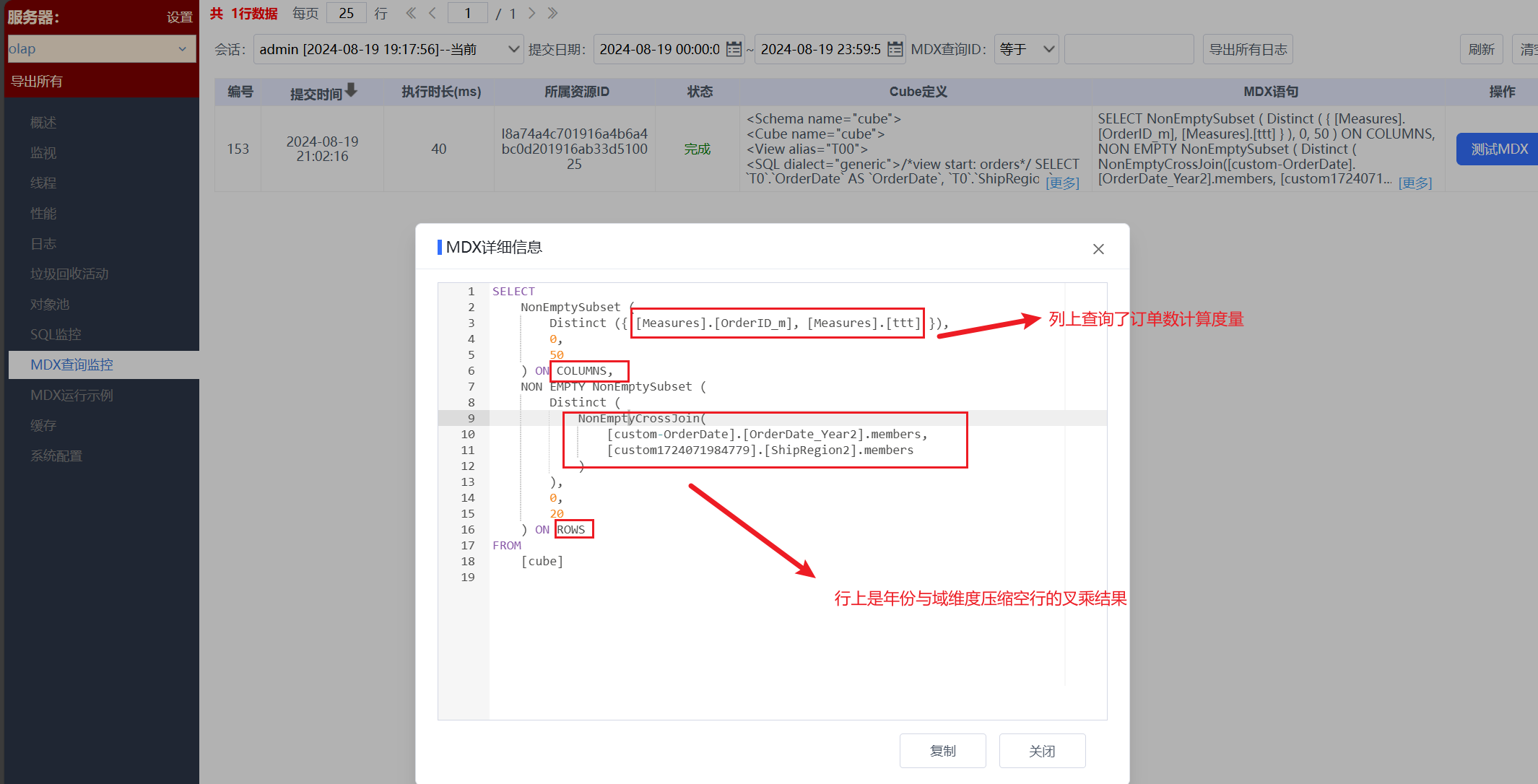
从【OLAP系统监控】-【MDX查询监控】中看到执行一条MDX查询;
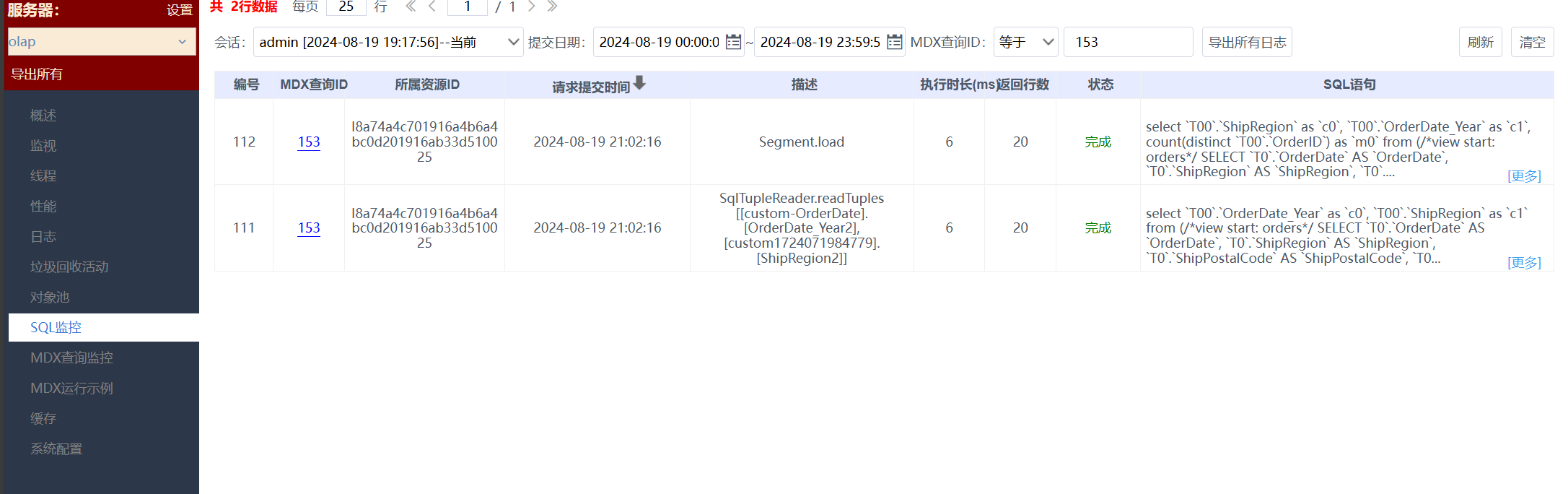
再通过上面的MDX编号,从【OLAP系统监控】-【SQL监控】看到了MDX对应的SQL语句;
介绍SQL之前,简单介绍下OLAP多维引擎的取数逻辑:多维引擎建模取数是为了将数据组装成一个立方体的形式,它首先获取所有维度的组合,用于构建一个不含数据立方体;立方体构建出来后,OLAP引擎会一个格子一个格子地填充数据。
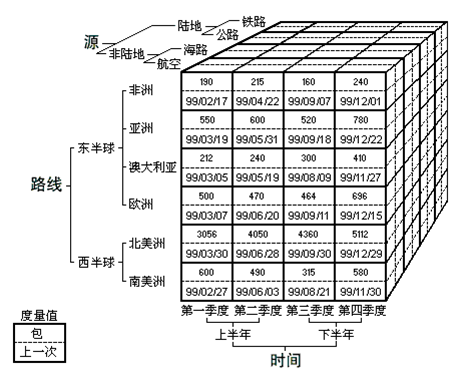
回到SQL,第一条是SqlTupleReader.readTuples语句,按照我们勾选的年份和区域维度进行聚合,获取的是年份和区域两个维度的组合,这样多维引擎就构造了一个包含年份和区域两个维度的立方体。
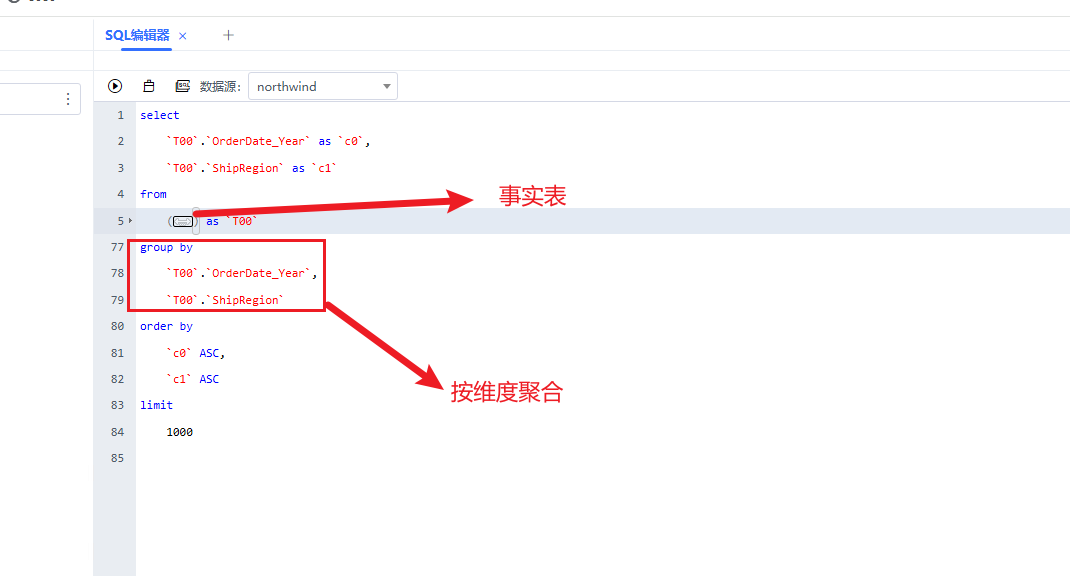
接下来我们看第二条Segment.load SQL语句,该语句的作用是为立方体填充单元格的值,以年份和区域为聚合字段,订单数为度量,通过Segment.load,多维引擎可以完成取数,往对应单元格填数,比如单元格坐标(2016,华南),单元格有个订单数的度量,值为34。
问题现象:
客户有一段SQL,在工具上查询的结果,与在数据集查询的结果不一致
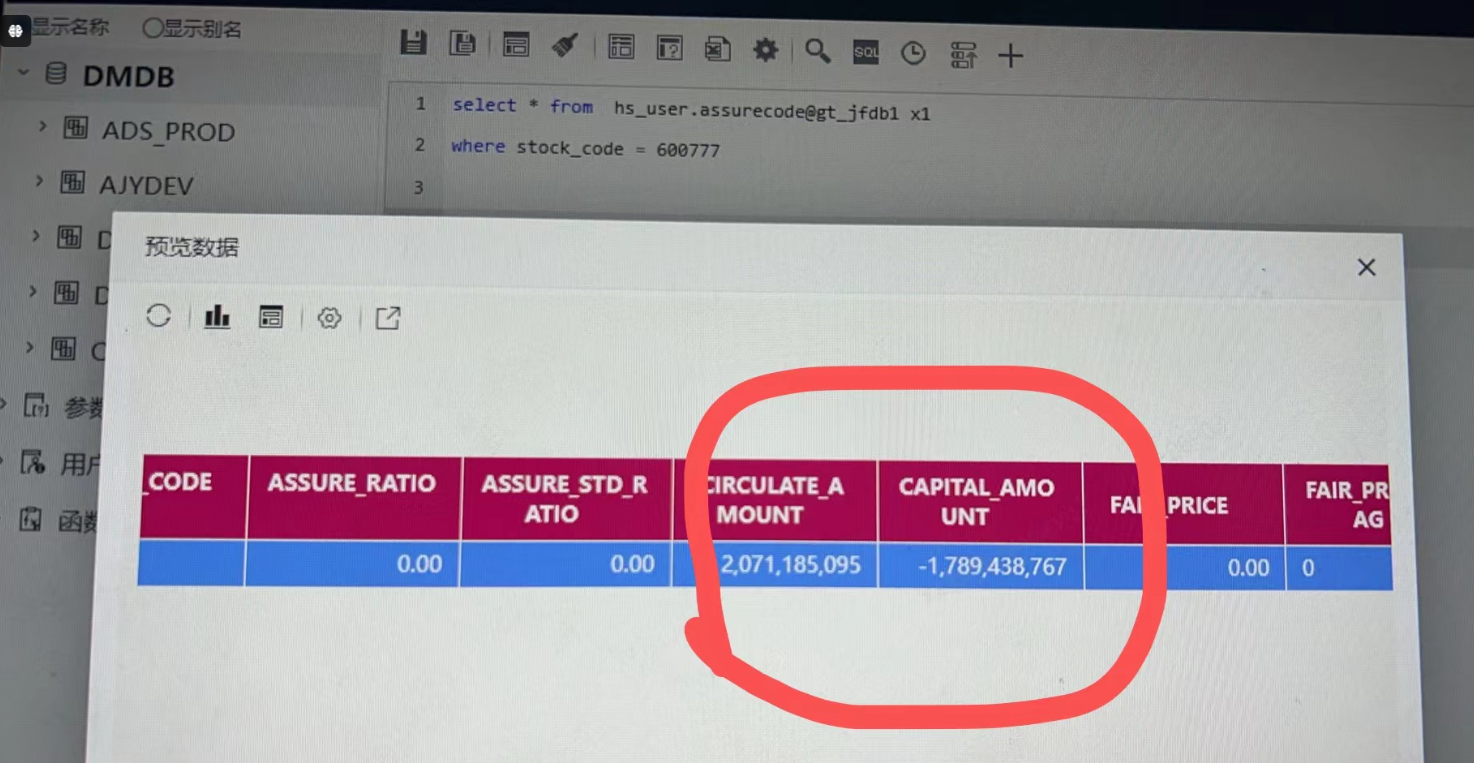
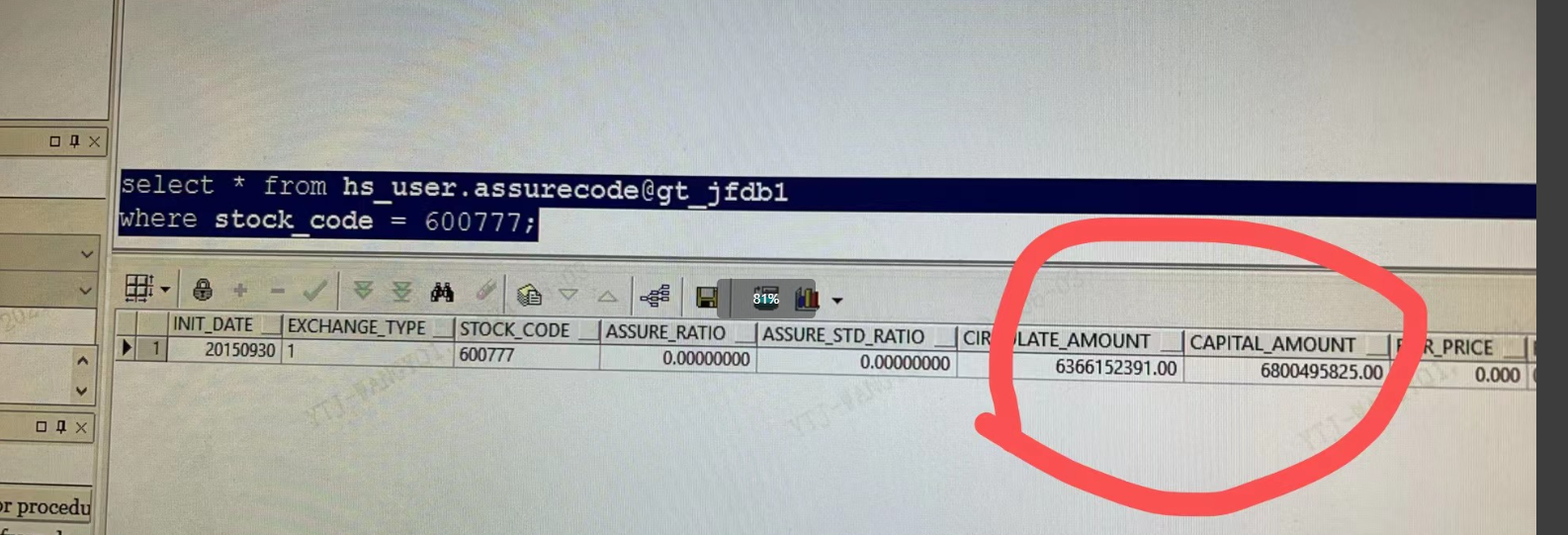
问题原因:
数据库表字段类型为Double,BI上为了取整,在数据集输出字段上改为了整型。为什么有些数值正常,有些数据就不对呢?因为Int的数值范围小于Double的数值范围,当Double类型数值大于Int的最大值或小于Int的最小值,就会发生精度溢出,导致结果不正确。
分析思路:
这种类型问题看SQL是没有用的,因为SQL执行都是一样。可以考虑拿相同SQL,新建一个数据集验证看看(或数据模型中的SQL查询)。
问题现象:
模型SQL查询能查询出数据,拖到报表时显示无数据。
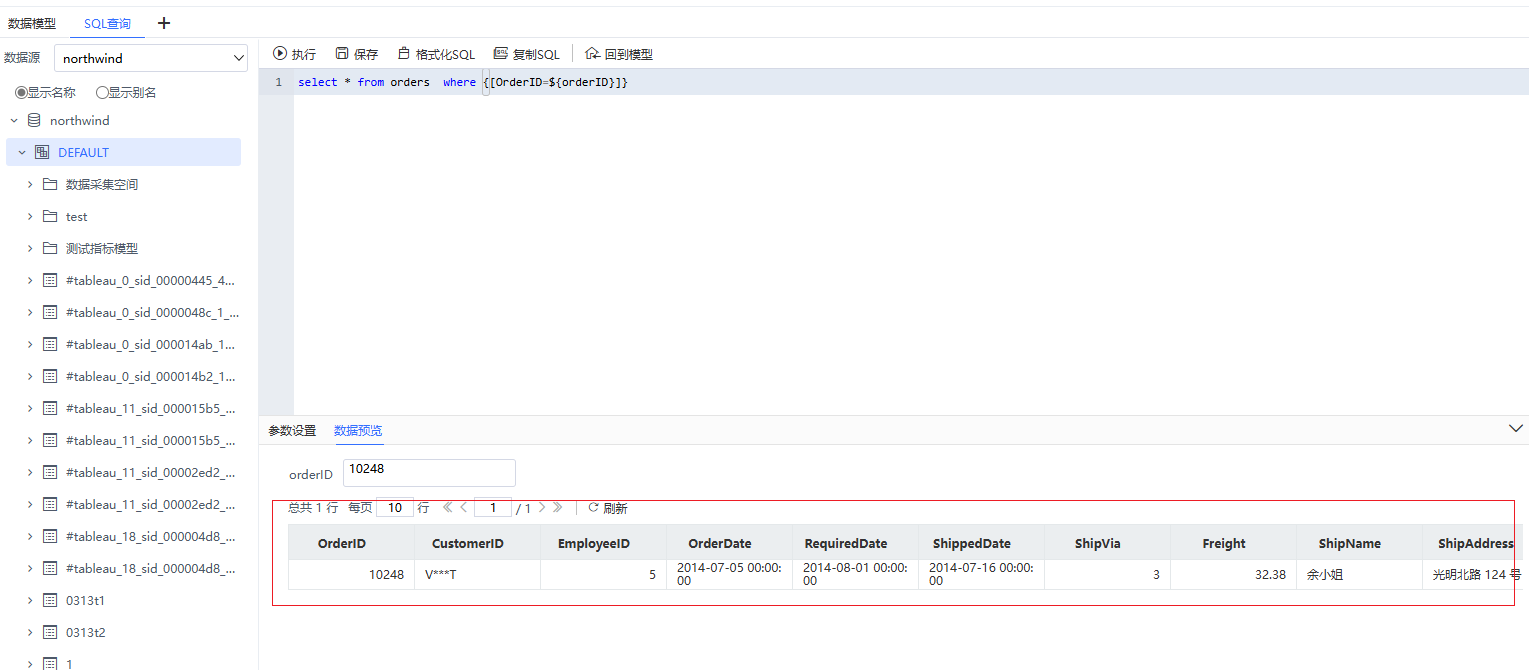
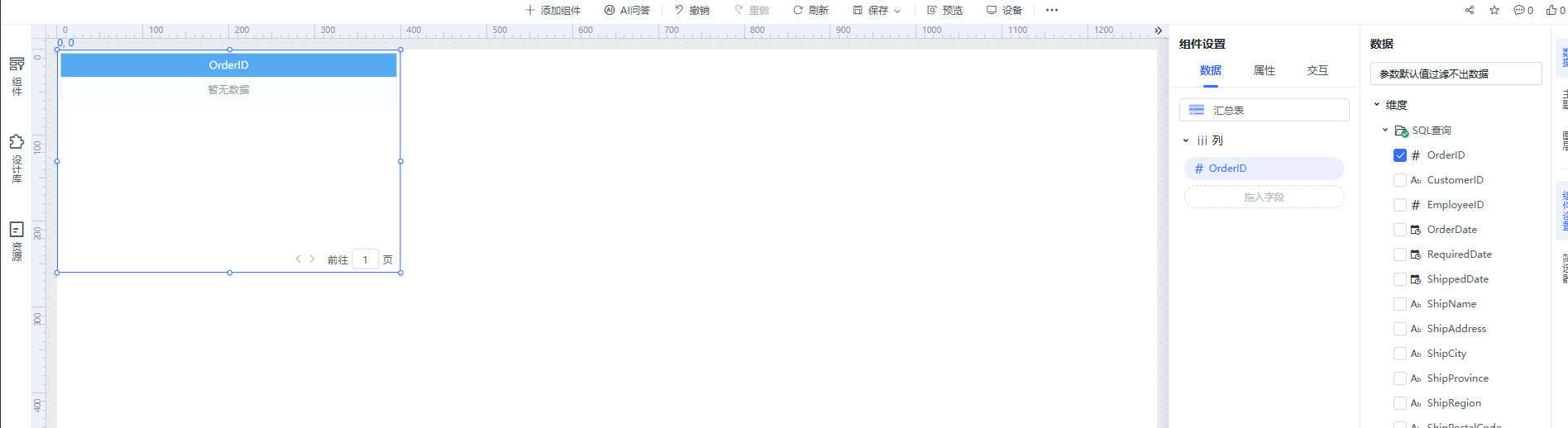
分析思路:
可视化的耗时分析或SQL监控看实际执行的SQL,对比生成的SQL与预想的SQL查询汇总的SQL有什么差异,一般考虑默认生效的参数、数据权限。
问题现象:
如下图,左边汇总表和右边明细表都是来源于一个数据模型,num是个数值型维度,原始数据是有数据的,汇总表没有数据,其中汇总表有个计算度量所以整个路径走的是多维的查询路径。
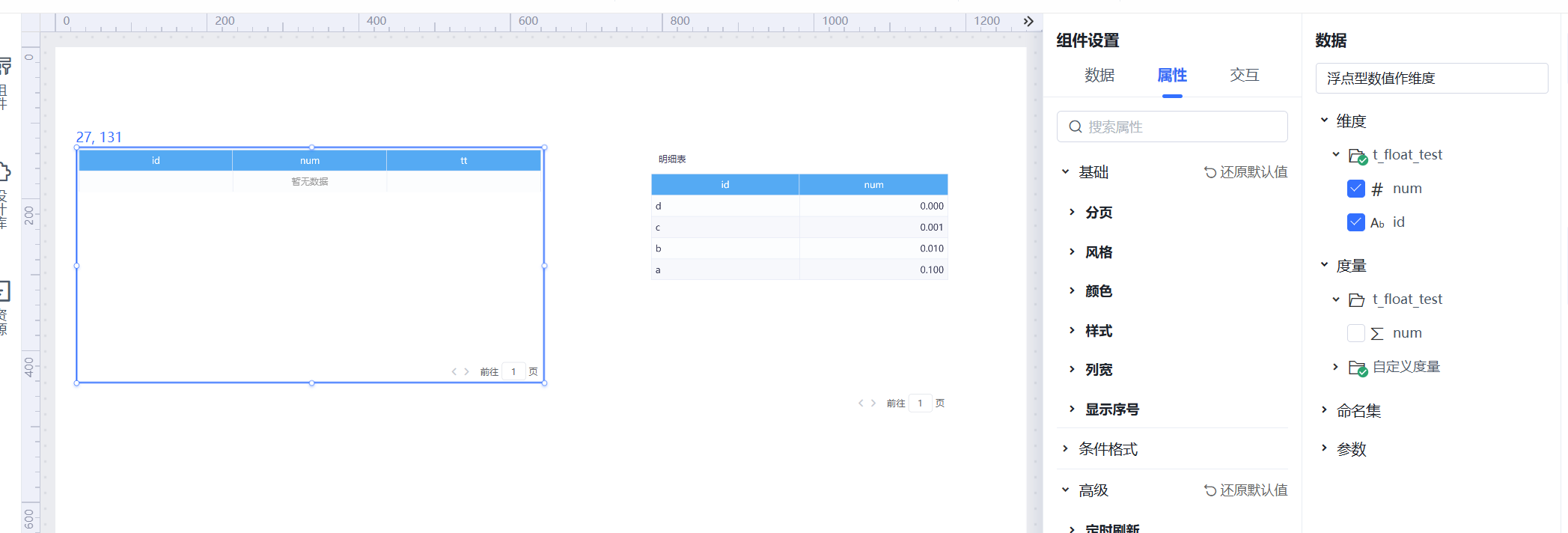
分析思路:
OLAP监控中看MDX的结果,发现MDX的执行结果也是空的
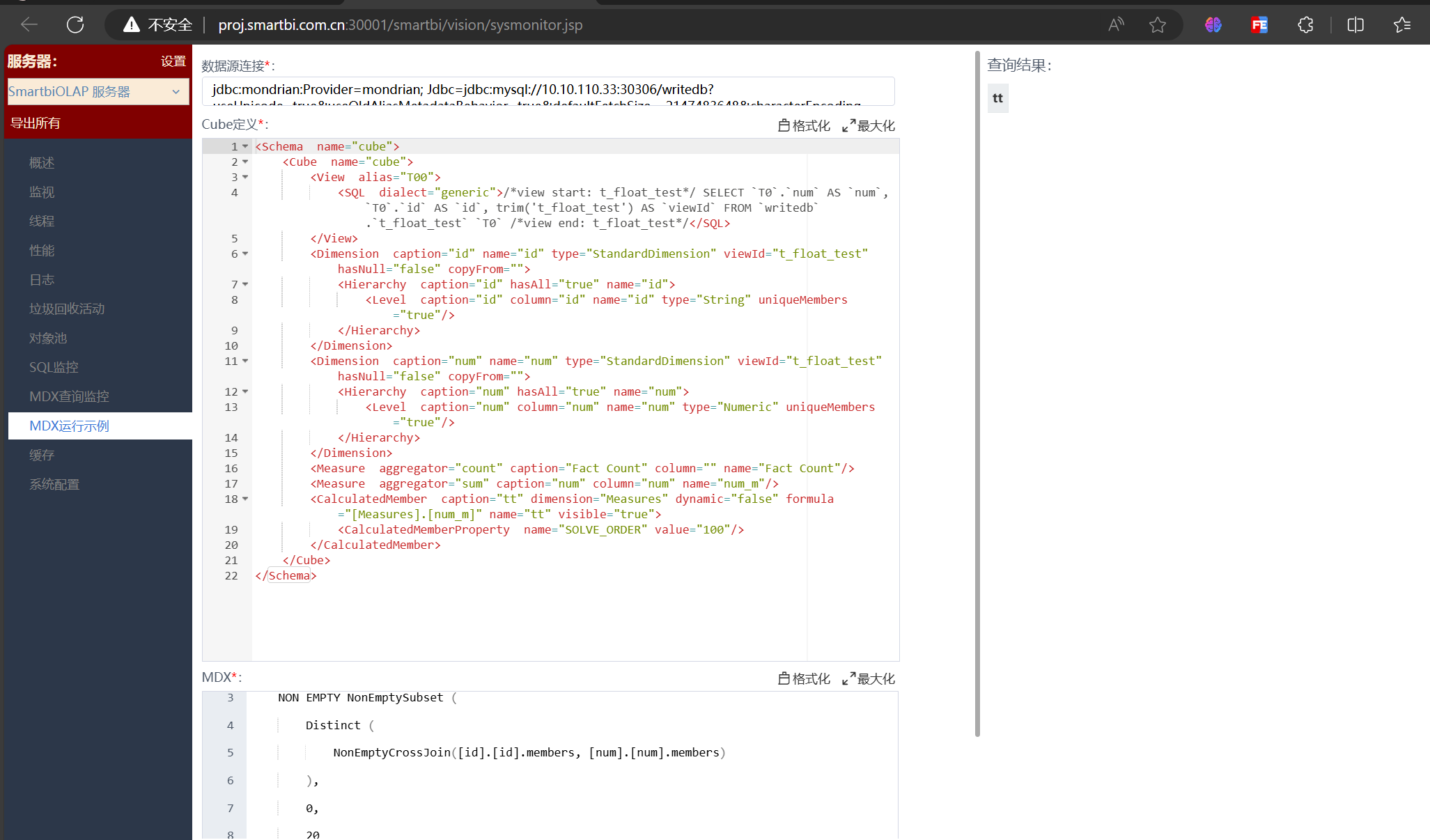
再看MDX ID对应的SQL,发现readTuples读取维度组合能正常查出4条数据,但是Segment.load读取维度组合的指标值时,读的0条数据,问题出现在Segment.load上
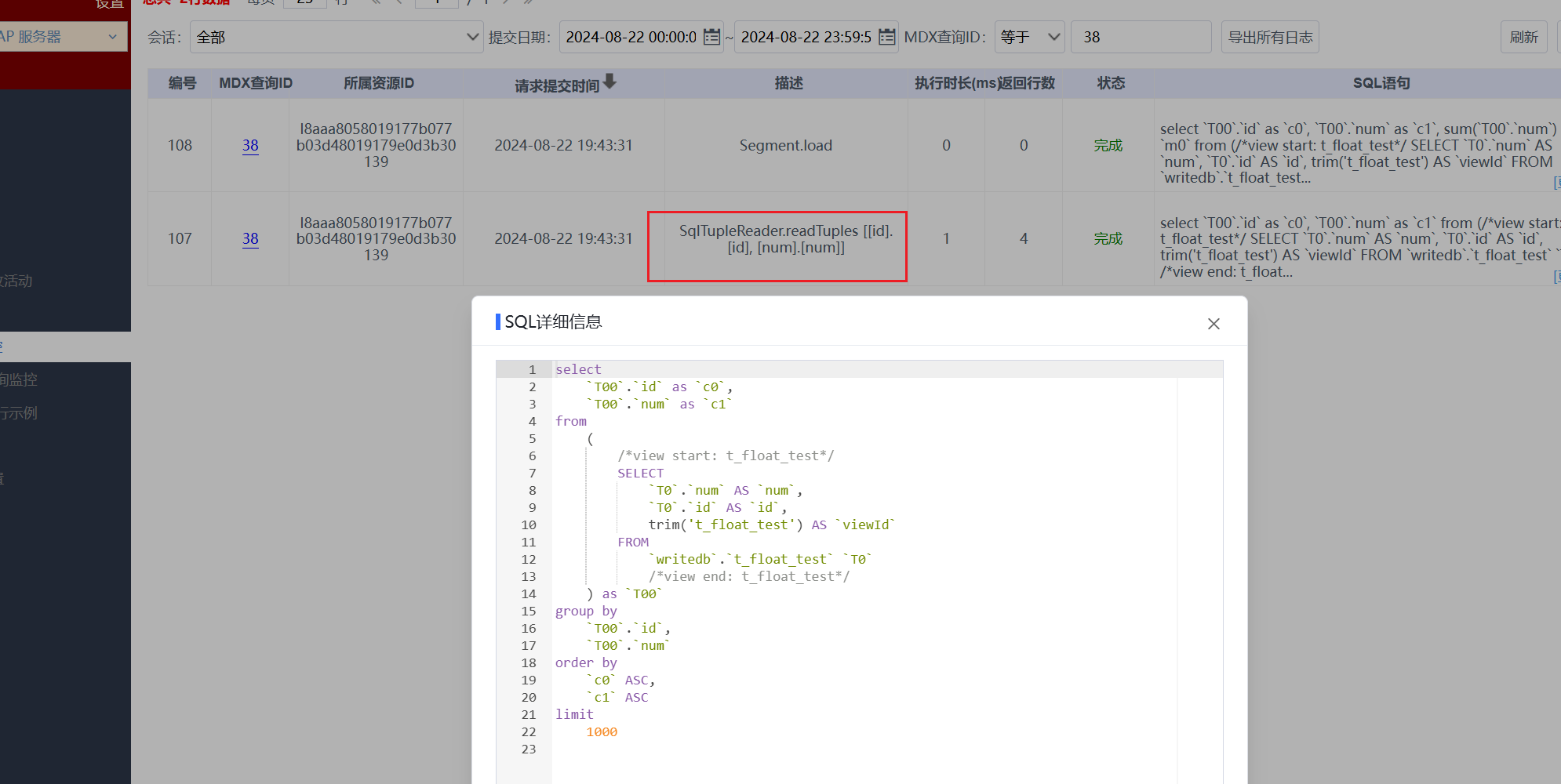
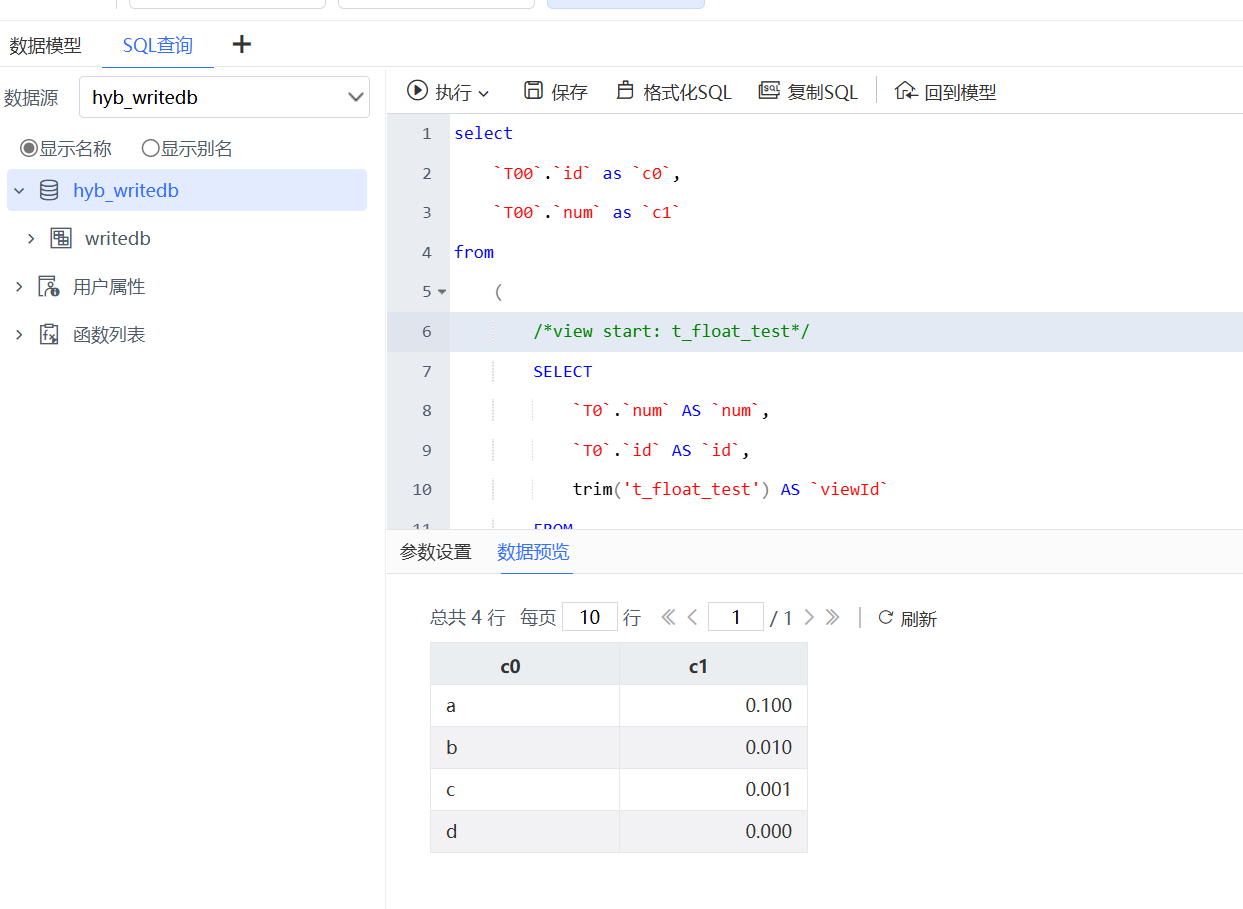
我们观察Segment.load的SQL语句,语句看起来没有问题,我们拿相同SQL去SQL查询中查询,确实查不出数据
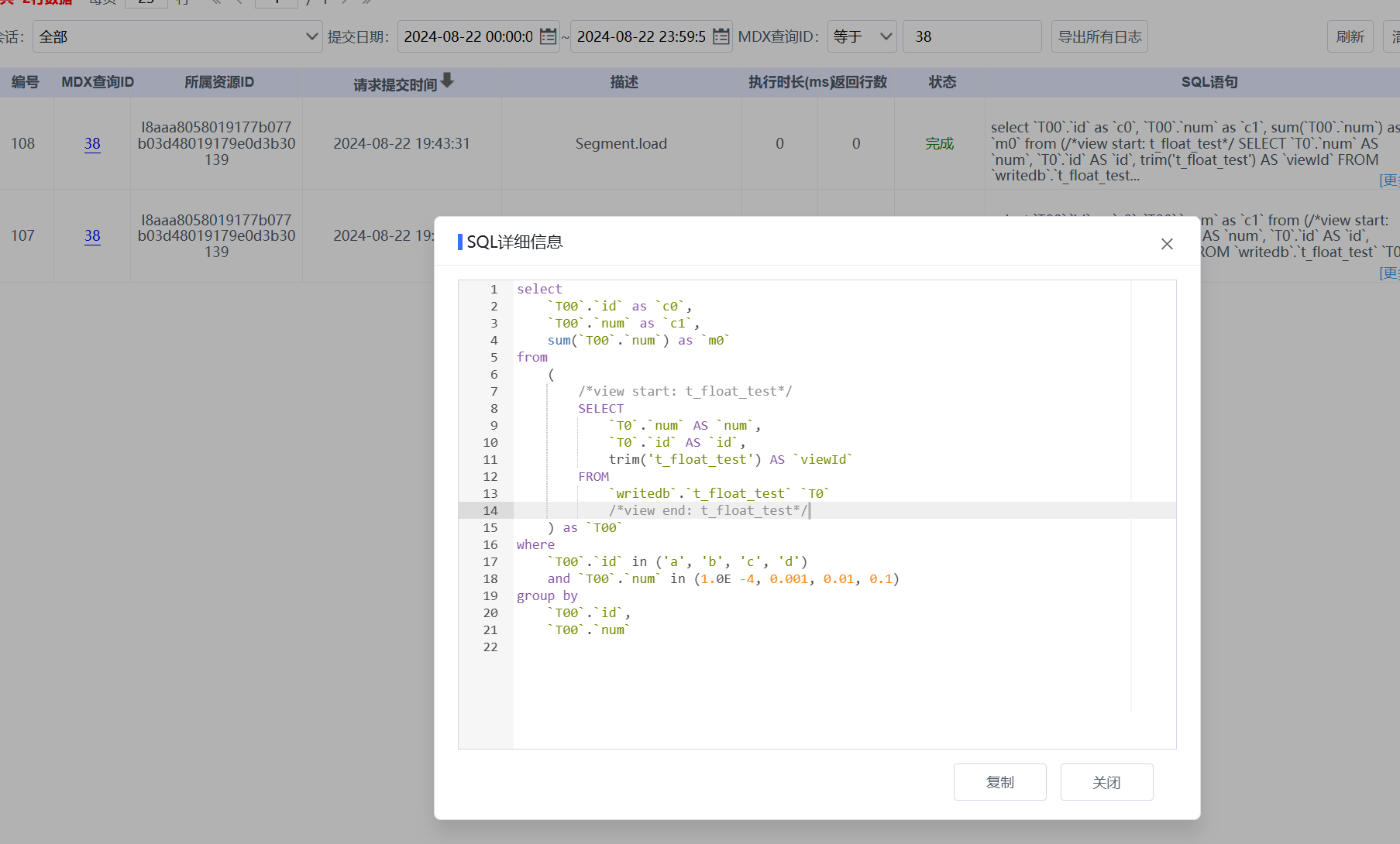
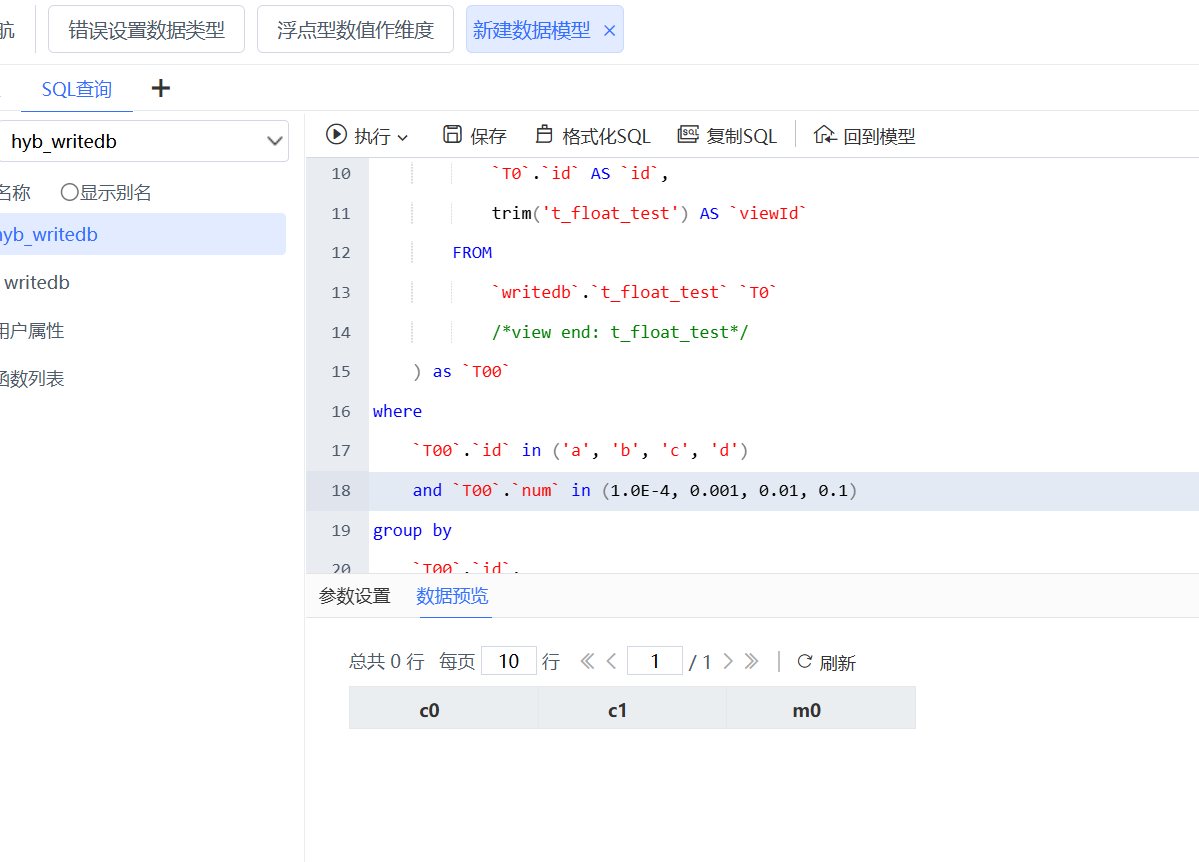
发现SQL去掉where中的in (1.0E-4,0.001,0.01,0.1)语句,可以获得查询结果,也就是浮点数据过滤有问题。
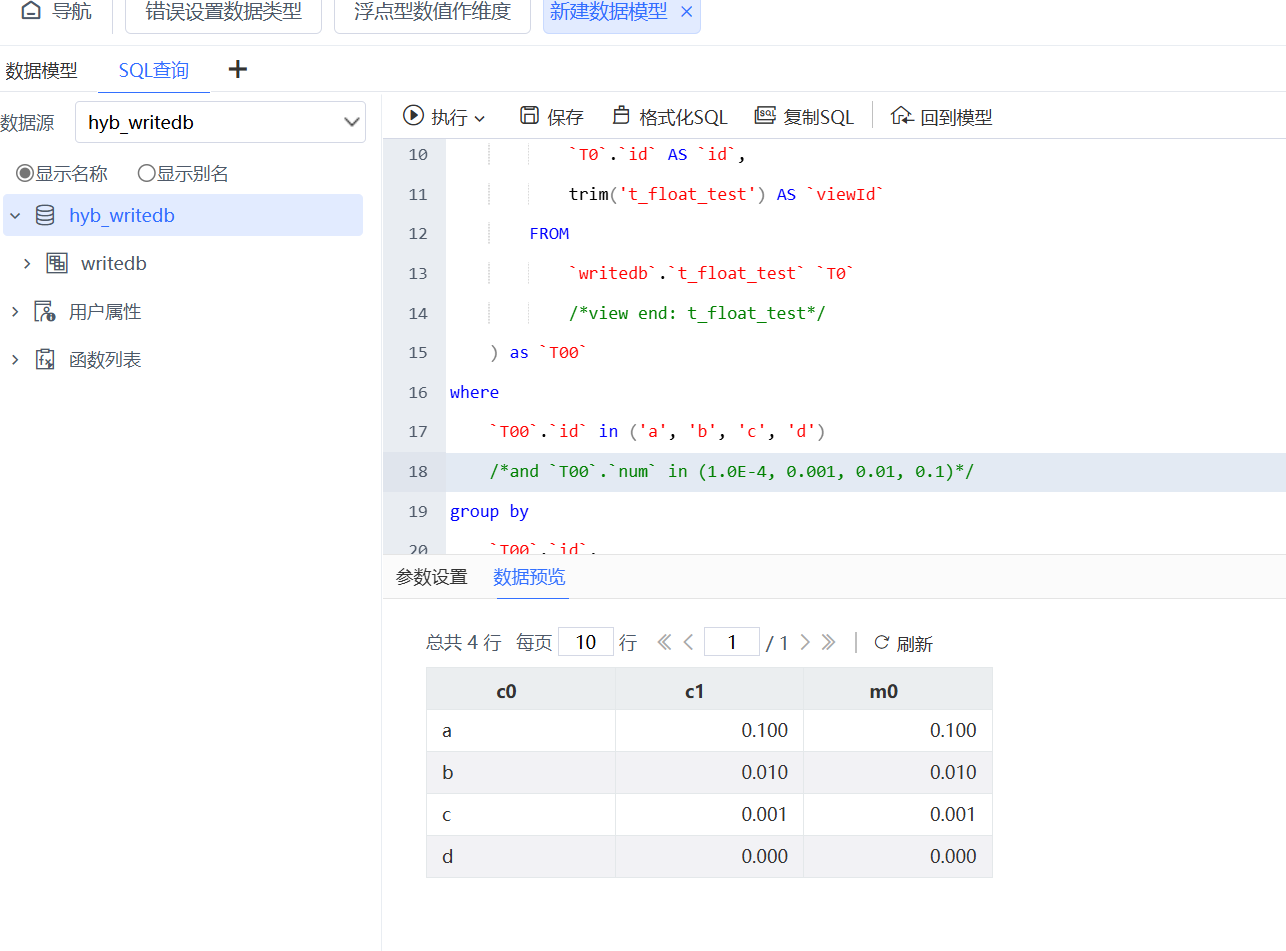
问题原因:
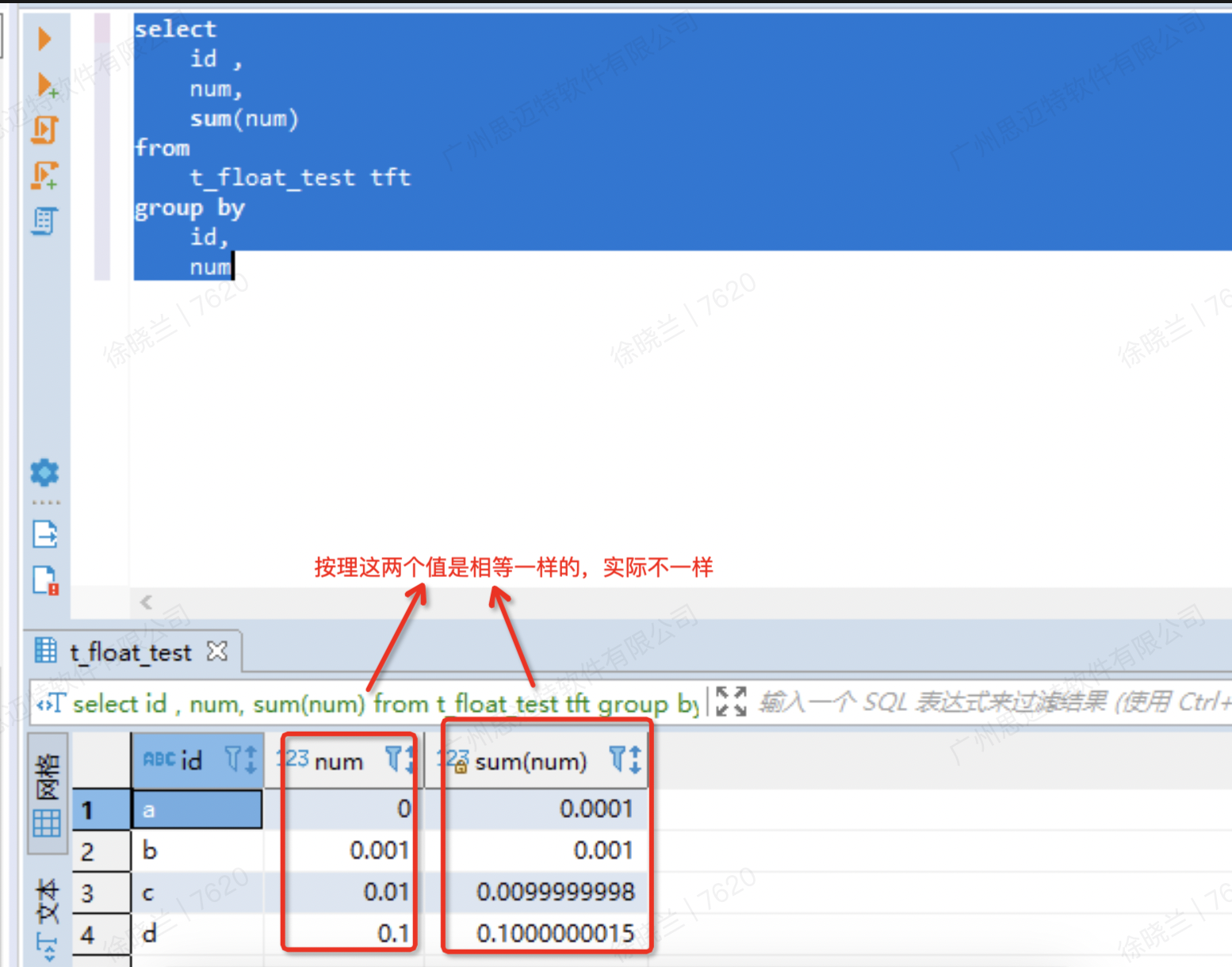
计算机使用二进制数值,有时候是无法准确表示浮点数的,而是一个近似值。比如下面SQL的第3、4条数据,我们认为sum的结果应该是0.01或0.1,但实际上数据库的结果并不是。因为我们使用浮点型数值where筛选条件,有可能匹配不到数据(以下测试是基于mysql)。
解决方案
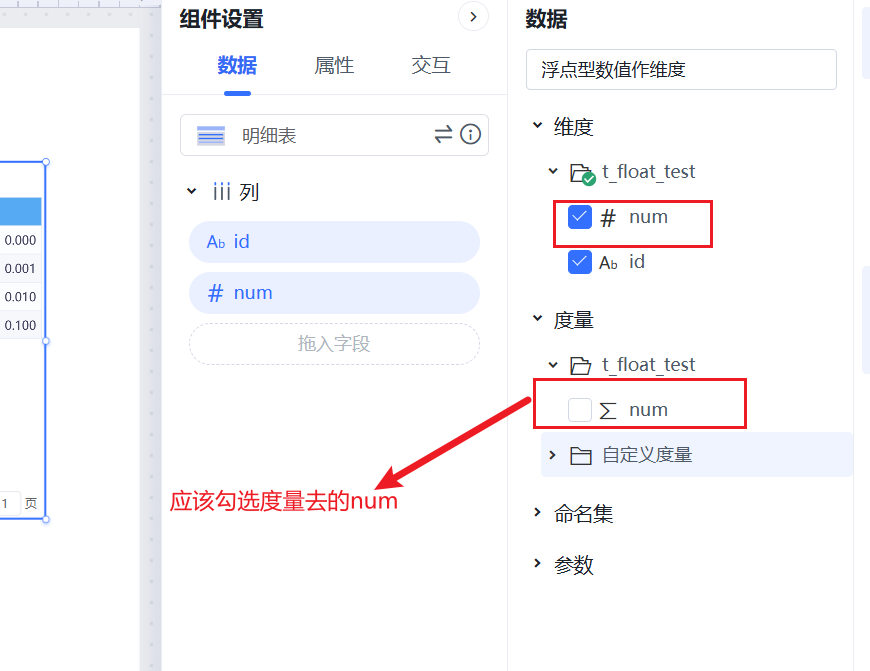
1、如果是希望就与指标聚合后的过滤,比如资产大于200000客户,勾选度量区的指标,映射到sql的话就是having过滤,在多维中就是指标过滤了,不会走上面的维度过滤路径;
2、满足SQL引擎条件的,可以开启SQL引擎,因为sql的查询直接是select id,num,metric from tb group by id,num,不像多维是先查出维成员组合,再计算指标,计算指标把维成员作为查询条件;
3、通过计算列将浮点型字段转成字符串。
举一反三
类似这种比如在clickhouse中,decimal类型的指标,过滤无效,都可采用这种方法验证,如 metric1是decimal(38,6),sql如果是select A, sum(metric1) group by A having sum(metric1)>10000000,过滤无效,实际应该有效,这个就是ch本身的特性,规避方案就是cast(metric1 as float)之类的,或者建表就不用decimal,采用float64之类的类型。
问题现象:
明细表是事实表【员工指标】的所有明细数据,注意到“张三”的指标数据为2,但在左边的汇总表数据被放大了,变成了4。
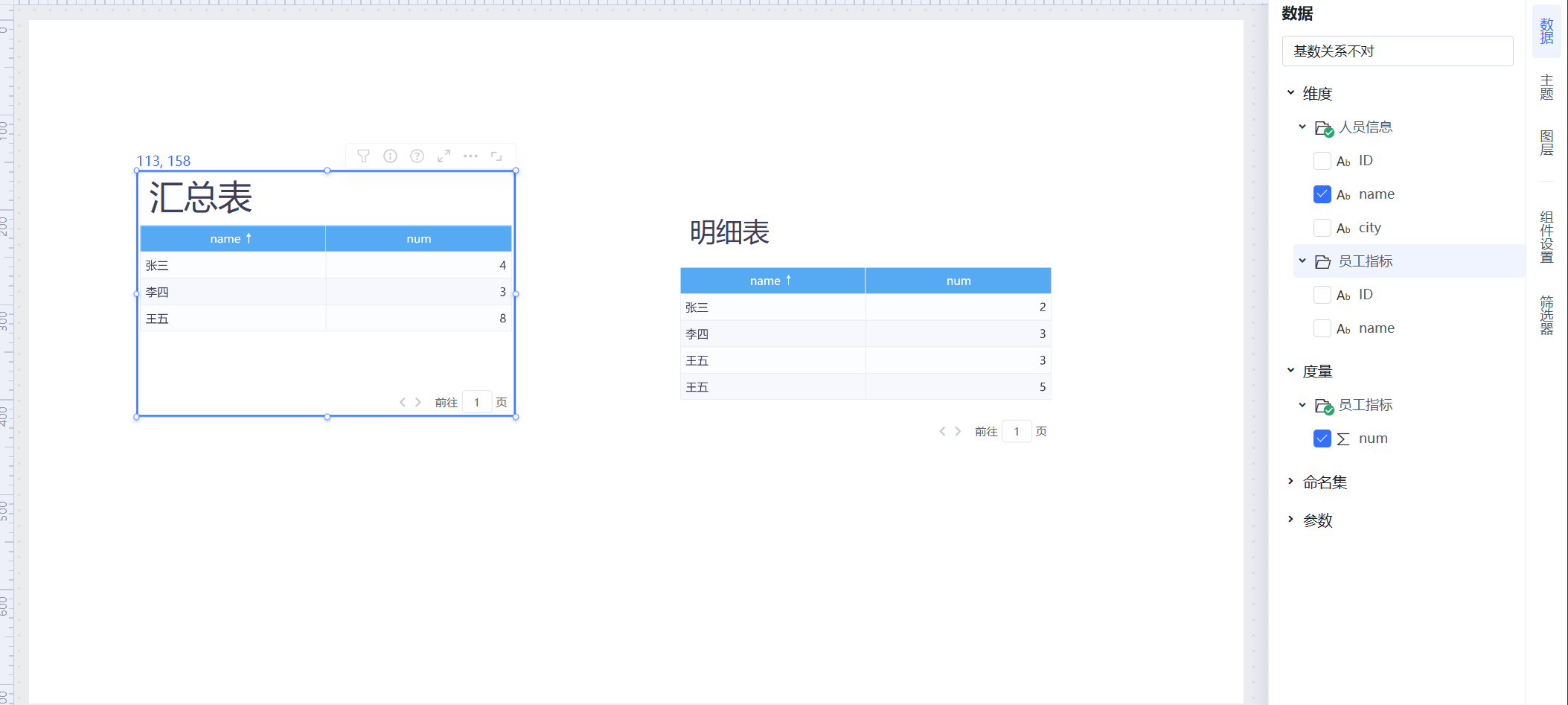
问题分析
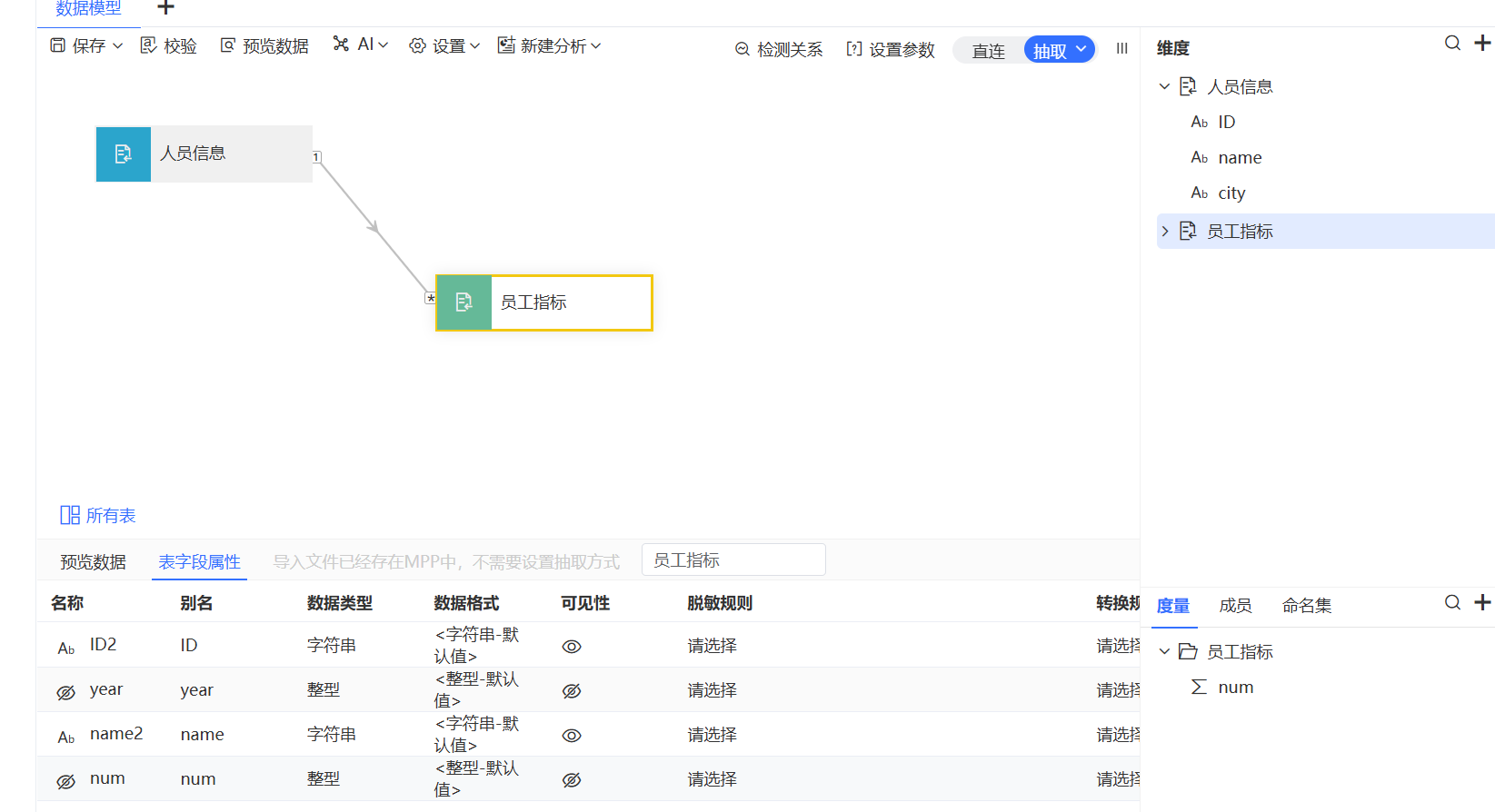
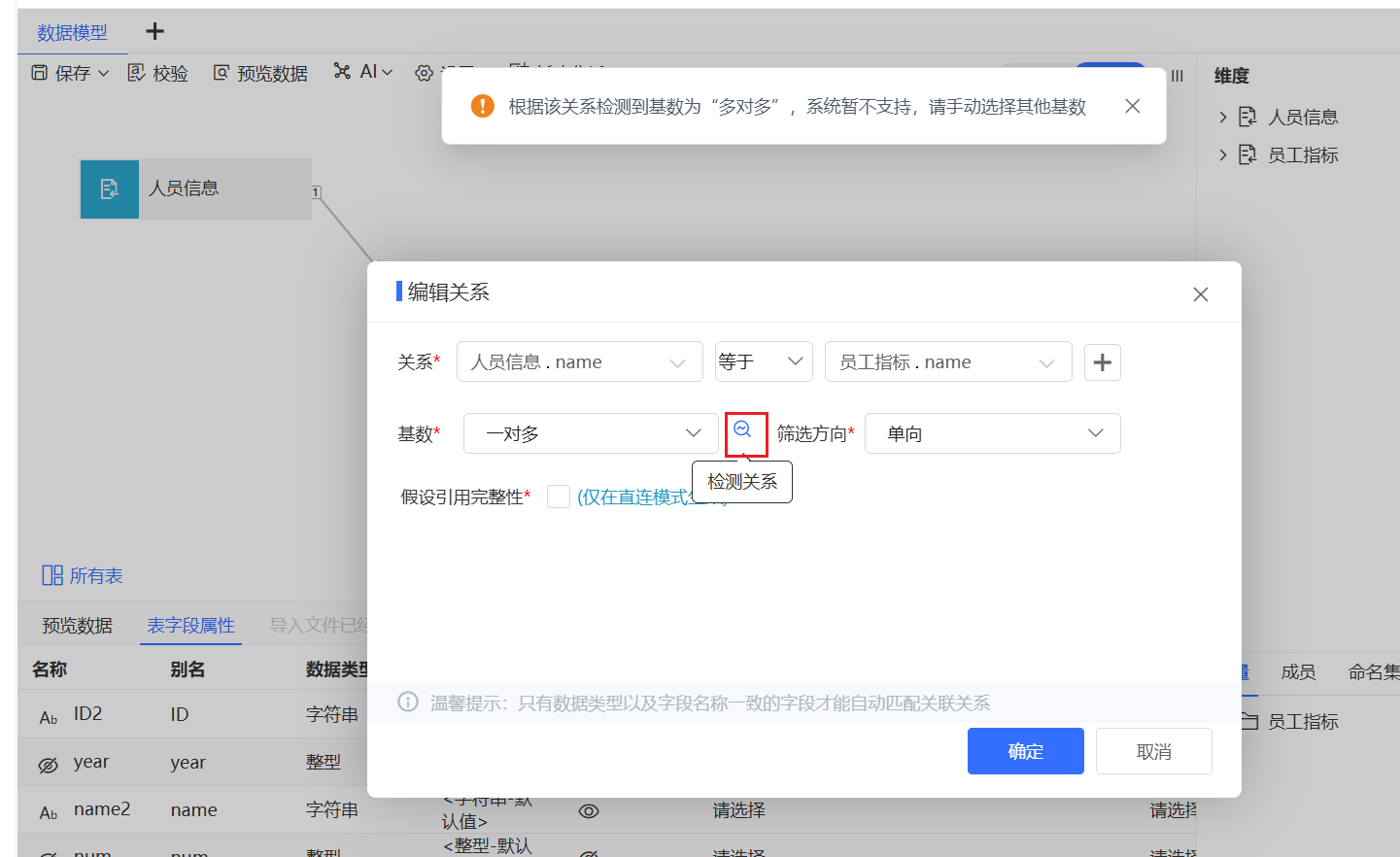
数据放大问题,我们优先考虑基数关系是否设置正确,先去数据模型中检测各个表建的基数关系。如下图检测结果告诉我们基数关系并不正确,基数关系为多对多
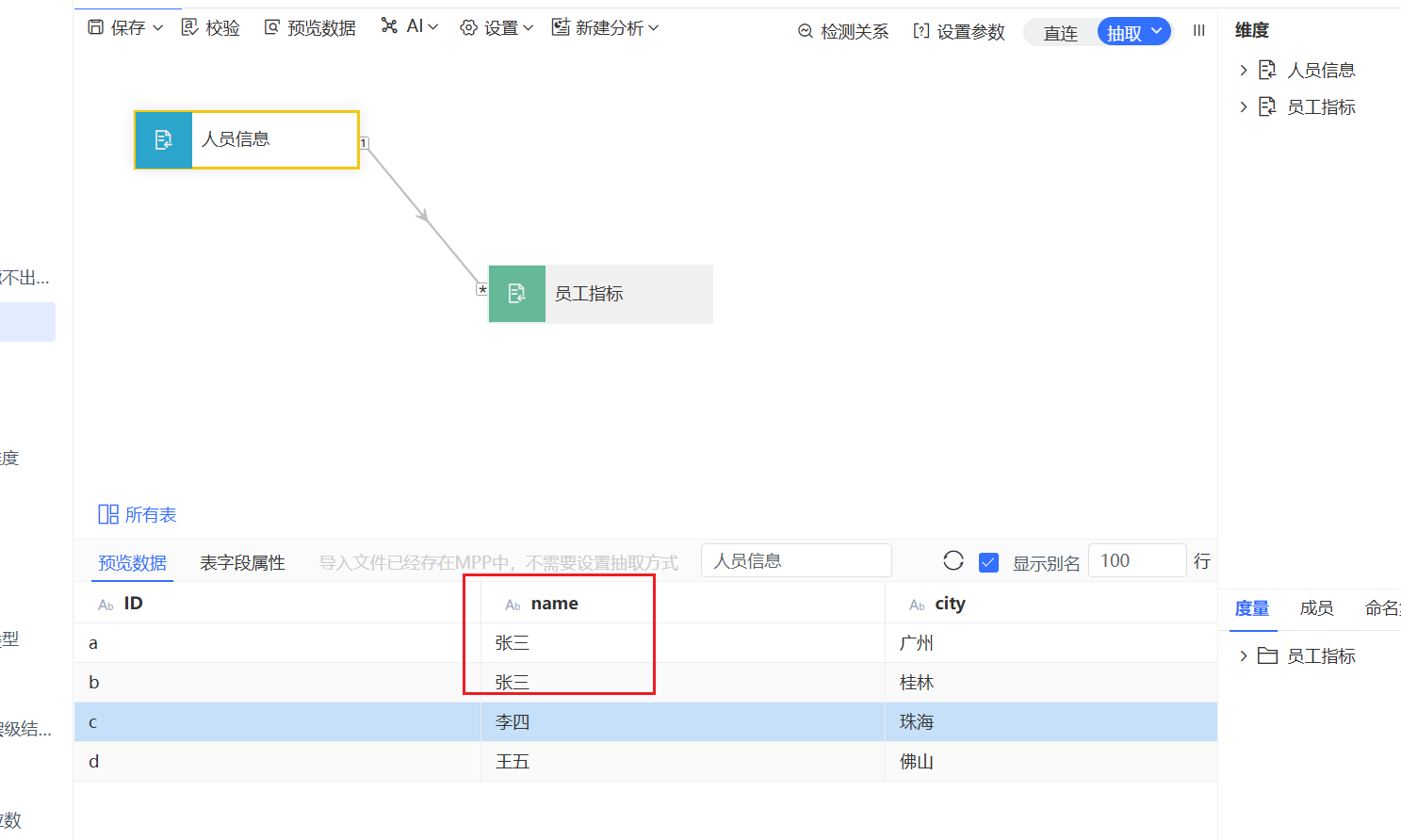
查看维表数据,发现name并不唯一,通过name关联并不合适。
解决方案
选择合适的基数关系,必须保证维表是一的一方,事实表是多(或一)的一方。
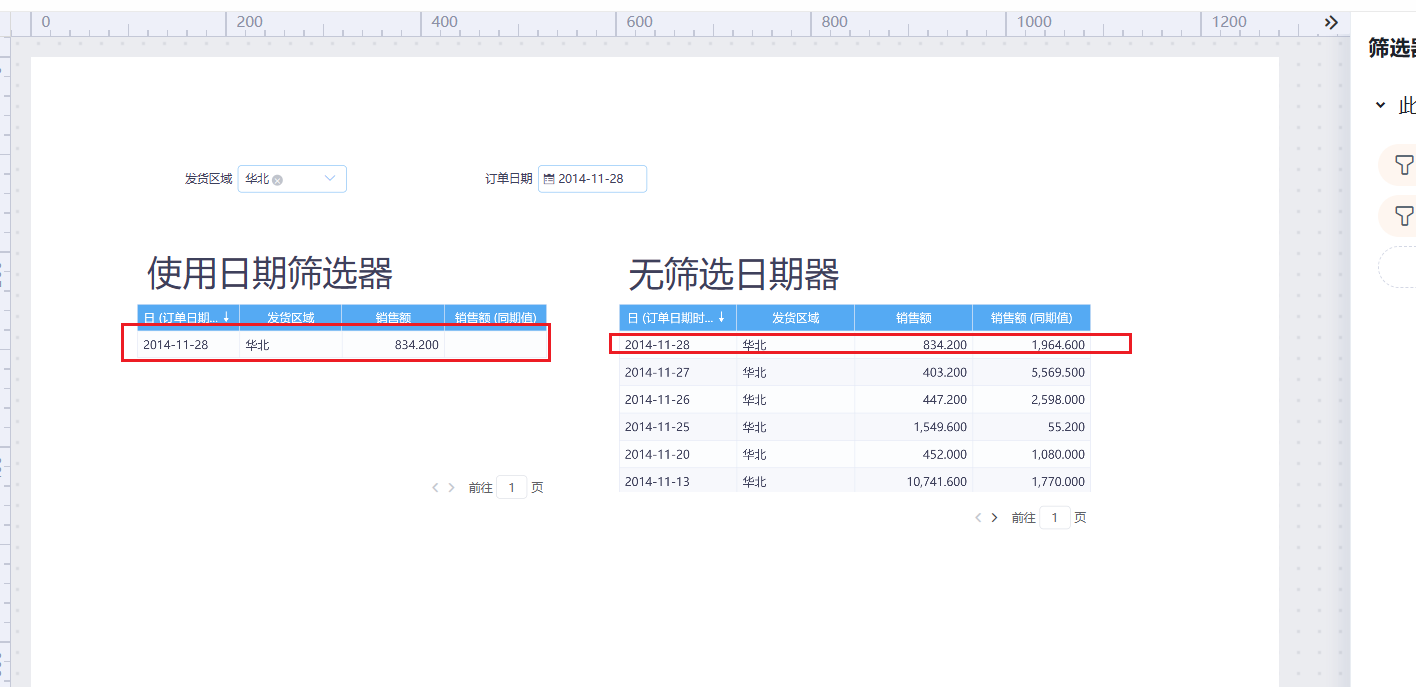
问题现象:
如下图,右边表格没有日期筛选器,注意到2014-11-28有同期值;当订单日期筛选器选择2014-11-28后,左边的表格同期值不显示数据。
分析思路
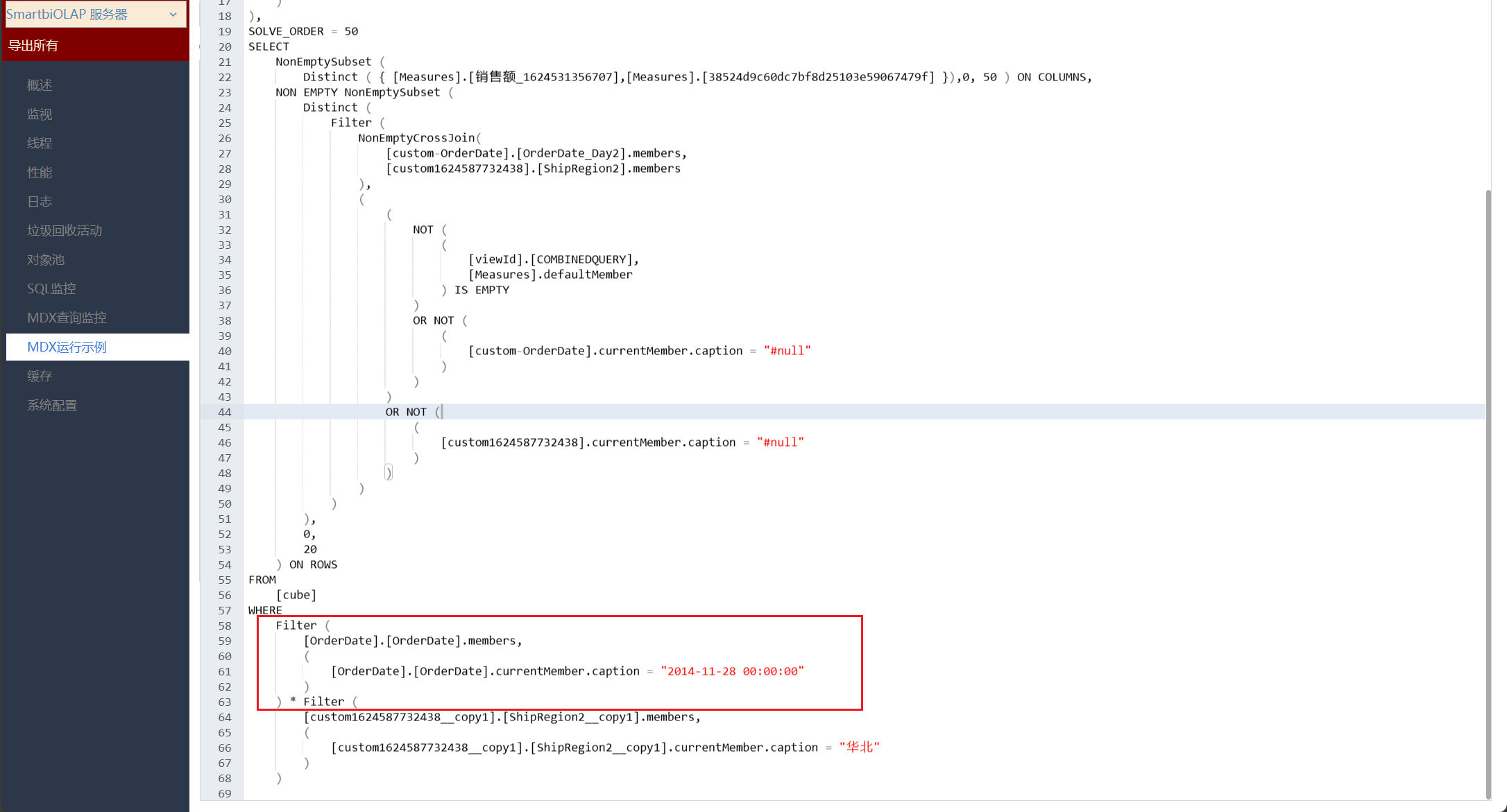
我们首先观察执行的MDX,发现两个组件MDX的差异在于切片区(where部分),同期值不显示MDX有订单日期原始字段的筛选过滤。
问题原因
如果了解同期等时间计算的逻辑,我们很容易知道问题出在切片区。比如计算订单维日期2014-11-28,华北区域的销售额同期值,多维引擎需要获取订单维日期2013-11-28,华北区域的销售额;有订单日期原始字段筛选器的情况下,计算订单维日期2014-11-28,华北区域、对应订单日期2014-11-18的销售额同期值,多维引擎需要获取的是订单维日期2013-11-28,华北区域、对应订单日期2014-11-18的销售额,指的注意的是,没有数据能满足订单维日期为2013-11-28并且订单日期为2014-11-18,所有同期是为空。
解决办法
有时间筛选器的的同环比等时间计算,我们应该使用时间层次对应的时间字段作为筛选器,不应该使用原始字段。
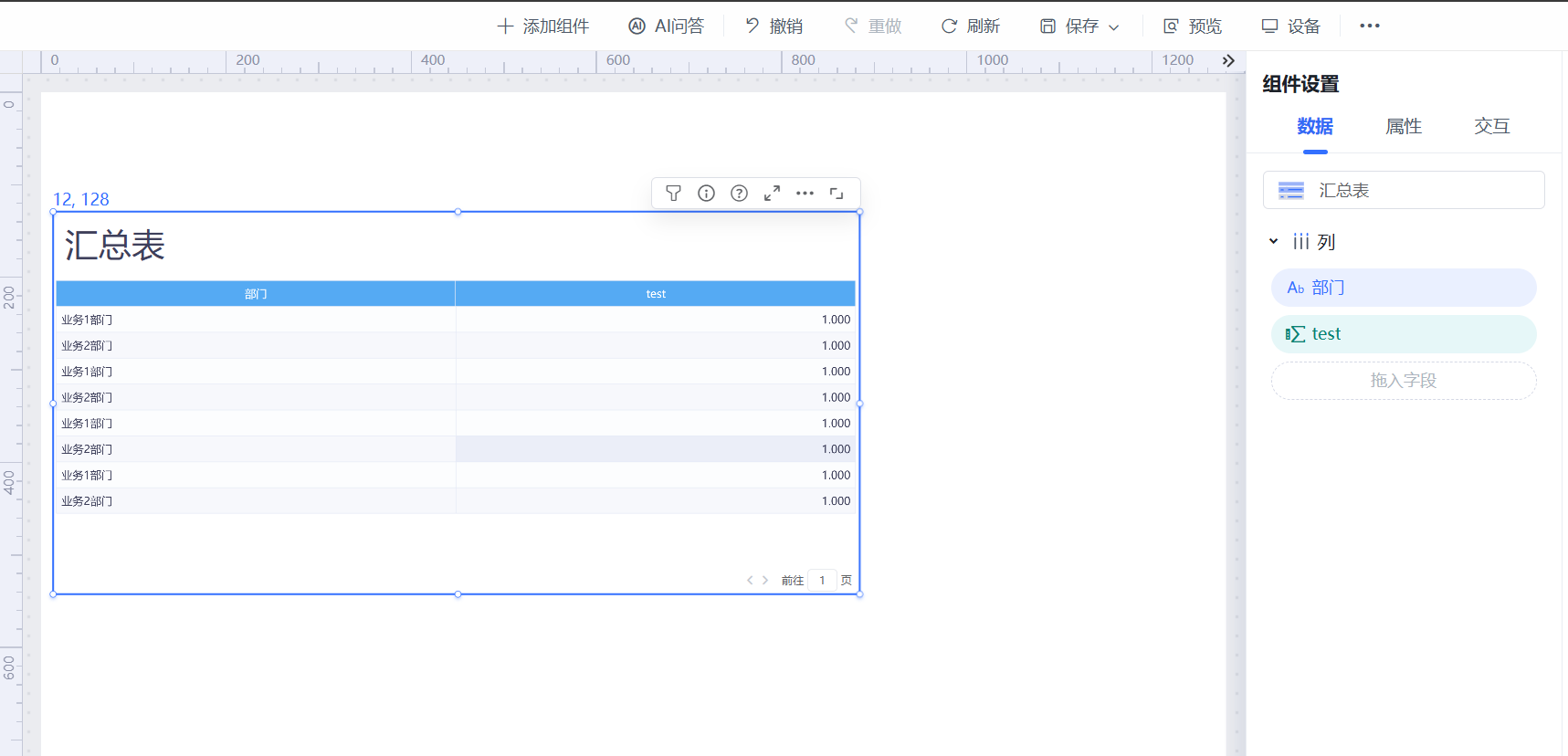
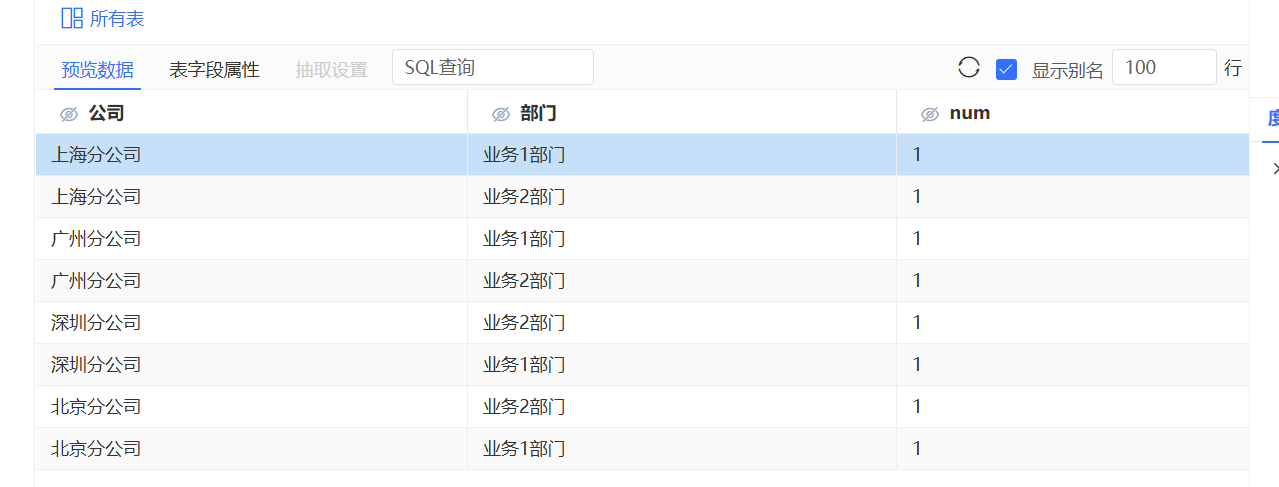
问题现象:
如下图的汇总表,部门列没有进行聚合汇总,我们认为汇总之后只有两条数据:业务1部门和业务2部门。
问题分析:
查看报表资源,发现模型有一个公司层次结构,部门来源于层次机构里的字段。
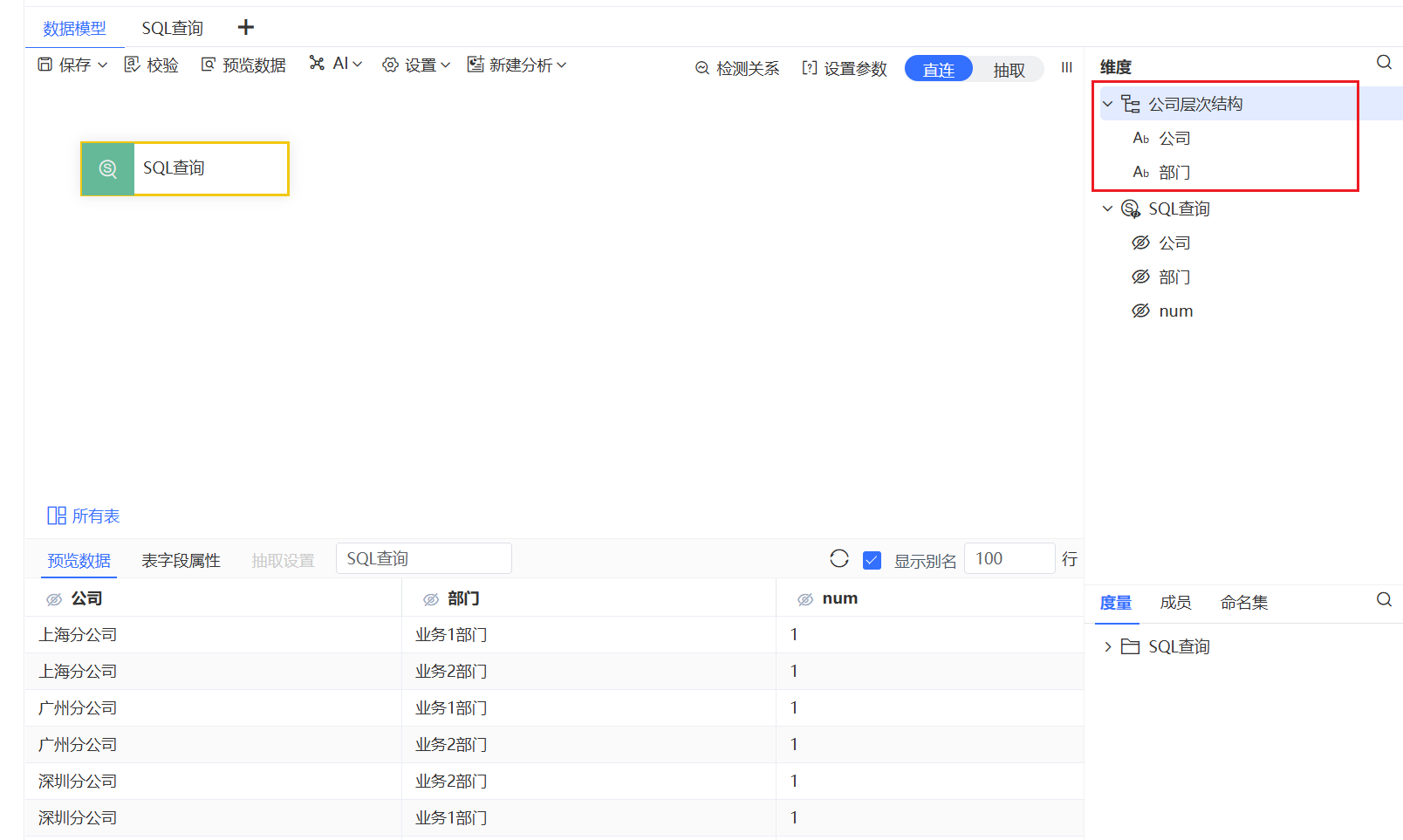
对于层次结构,我们需要了解的是,这是一种父子机构的层级,对于子成员,如果父成员不同,那子成员不能汇总成一个,他们有不同的是路径。本示例中,部门的父级成员是公司,我们注意到不同的公司都有业务1部们和业务2部门。
解决方案:
针对本例,如果需要关注业务部门的汇总指标,不考虑公司维,那需要使用原始的部门维度。
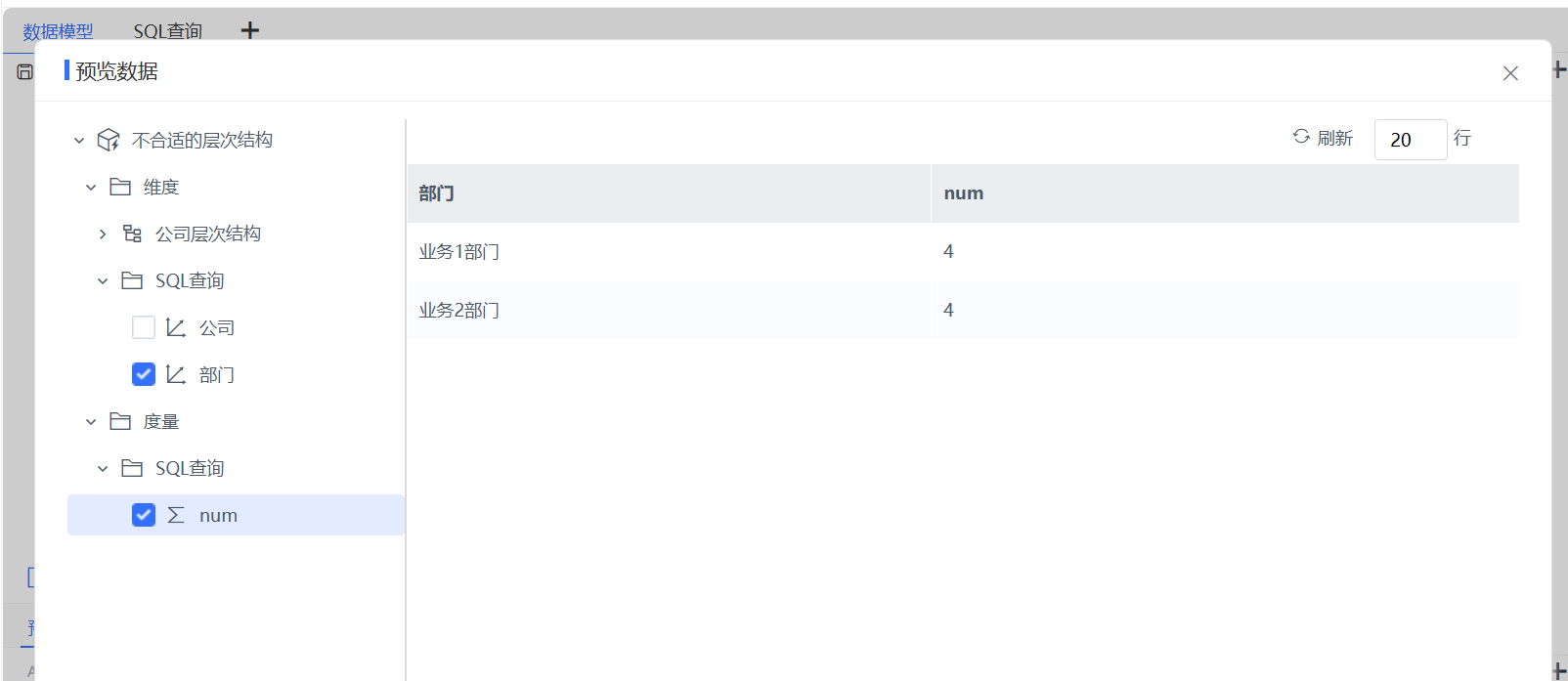
举一反三:
通常也出现在年周时间维度的应用上。旧版本的时间层次结构允许生成包含年周的层次:
年->年季>年月->年周->年月日
比如下图出现了2024年22周两条数据,实际上2024年22周存在跨月的