1 概述
用户可以通过编写SQL语句对数据中的表进行加工、处理再添加到数据模型中。
前置条件
2 示例说明
2. 1 通过参数过滤数据
我们都知道,金融、制造等行业的数据量比较大,业务用户在分析报表的时候如果把全部的数据都拉下来,会非常耗时,所以在很多场景下,只希望拉取某天或某几天的数据的数据。
以产品自带数据源northwind数据库下的“orders”表为例,由于每天的订单数据很大,需要增加时间过滤进行查询。
具体的操作步骤如下:
1、创建数据模型并在模型中增加 “SQL查询”,在SQL查询下面编写带有条件的SQL语句,如下图:
- where {[字段=${ParamName}]}参数是动态值,"{[]}"代表参数默认值可不填写,不填写代表查询全部数据。
- 如果 where 字段=${ParamName},这种写法也支持,但是参数默认值必填,否则执行不通过。
- 如果在模型中的[参数管理]进行了关联映射,可以随着模型设置的默认值改变输出结果集;具体可参考:参数设置。
- 参数数据类型,默认是字符串,用户可以选择与SQL查询条件字段匹配的数据类型:日期、日期时间、时间、整型、浮点型、长浮点型、其他。

2、如果用户写好了SQL查询,想回到数据模型,建议先点击 保存 之后再点击 回到模型 ;可以在模型修改数据类型、修改别名、设置与其他查询的关系或者构建数据模型。
2.2 通过参数控制权限
业务用户开发了“销售报表”,老板(admin)可以查看全部地区的销售数据,但是各地区的负责人只能查看对应地区的数据。
目前用户”A“是华南地区的负责人,那如何做到用户”A“只能查看”华南“地区的数据?
我们以产品自带数据源northwind数据库下的“orders”为例:“orders” 存储的是各个区域、省份、城市的销售订单信息。
具体的操作步骤如下:
1、创建数据模型并在模型中增加 SQL查询 , 用户通过SQL查询控制权限:
- 如果权限比较简单,比如通过”用户所属组”可以直接匹配的,可直接用 函数 进行控制;上图的CurrentUserDefaultDepartmentAlias就是用户所属组与区域匹配上了,所以可以控制权限。
- 如果权限控制比较复杂,比如用户存储在另外一个业务库,需要通过SQL语句进行再处理的,可使用 用户属性。

2、保存并回到模型,查看最终效果(预览模型):如需要把该参数在报表层应用,可以参考:参数设置进行映射。

2.3 通过SQL实现数据加工、多表关联等生成宽表
有时候IT技术人员是直接通过SQL处理、加工好对应的指标,然后让业务人员直接基于处理好的指标进行报表展现,并且查询全部数据,这时候也可以使用模型里面的SQL查询。
我们以查看“产品销售额”为例来进行说明。
1、创建数据模型 并在模型中增加 SQL查询
2、以产品自带northwind数据库下的”product“、“orderdetails” 为例编写SQL语句如下图:
- 可以在SQL语句中多表关联、过滤、使用数据库本身的函数进行计算、字符串替换、拼接、case when等等。

3、保存 之后再回到 回到模型,以查询名称命名生成了一个宽表,选中 查询 通过 右键菜单 可以设置与其他查询的关系或者参考构建数据模型构建自己的模型。
2.4 通过SQL进行union
前置条件
如果想复现示例,需要先把示例数据导入到模型中,详细请参考:导入文件数据。
示例数据下载:合同示例数据.rar。
某软件公司北京、广州、深圳的合同数据分别存在三张表中,老板想看三个城市的报表,业务用户希望能把他们进行合并。
目前可以通过数据模型的SQL查询:写SQL语句union2个或多个不同的表。
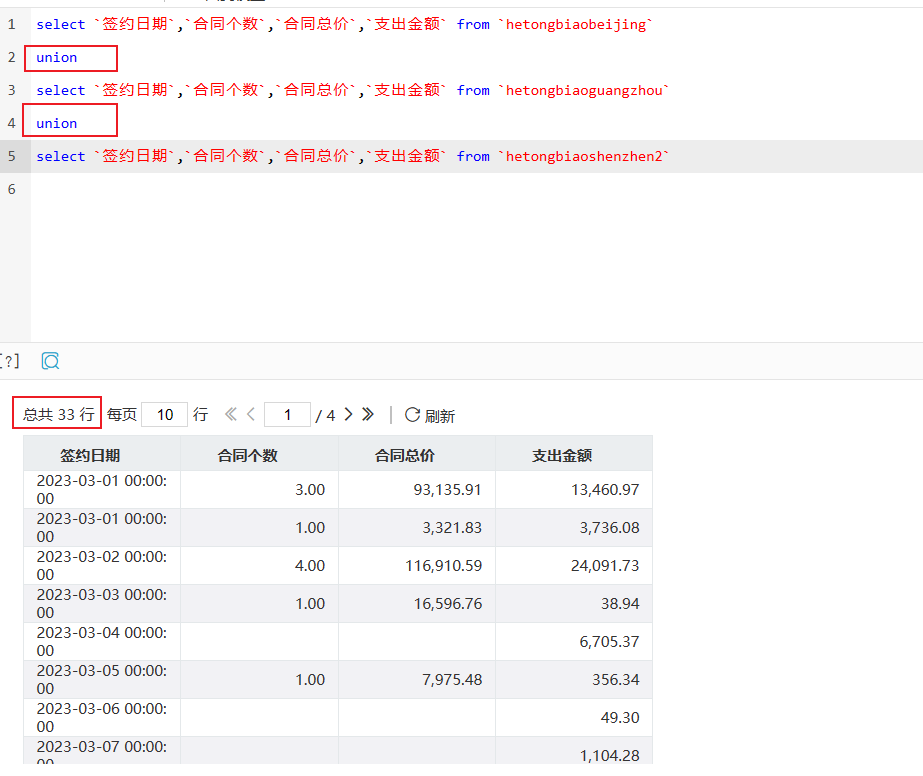
使用 union 将数据合并到一起,如下图:
- 合并前是各个查询单独查询数据,合并之后,3张表的数据全部合成一张表;查看总数,已经累加了三张表的数据。
- union:用于合并俩个或多个SELECT语句的结果集,并且消去表中任何重复行,纵向追加数据。
- 也可以使用union all,union all 与union的区别是:union all 不会消除表中重复行。
- 保存 之后再回到 回到模型 ,可以设置与其他查询的关系或者参考构建数据模型构建自己的模型。
1 概述
用户可以通过编写SQL语句对数据中的表进行加工、处理再添加到数据模型中。
前置条件
2 示例说明
2. 1 通过参数过滤数据
我们都知道,金融、制造等行业的数据量比较大,业务用户在分析报表的时候如果把全部的数据都拉下来,会非常耗时,所以在很多场景下,只希望拉取某天或某几天的数据的数据。
以产品自带数据源northwind数据库下的“orders”表为例,由于每天的订单数据很大,需要增加时间过滤进行查询。
具体的操作步骤如下:
1、创建数据模型并在模型中增加 “SQL查询”,在SQL查询下面编写带有条件的SQL语句,如下图:
- where {[字段=${ParamName}]}参数是动态值,"{[]}"代表参数默认值可不填写,不填写代表查询全部数据。
- 如果 where 字段=${ParamName},这种写法也支持,但是参数默认值必填,否则执行不通过。
- 如果在模型中的[参数管理]进行了关联映射,可以随着模型设置的默认值改变输出结果集;具体可参考:参数设置。
- 参数数据类型,默认是字符串,用户可以选择与SQL查询条件字段匹配的数据类型:日期、日期时间、时间、整型、浮点型、长浮点型、其他。
2、如果用户写好了SQL查询,想回到数据模型,建议先点击 保存 之后再点击 回到模型 ;可以在模型修改数据类型、修改别名、设置与其他查询的关系或者构建数据模型。
2.2 通过参数控制权限
业务用户开发了“销售报表”,老板(admin)可以查看全部地区的销售数据,但是各地区的负责人只能查看对应地区的数据。
目前用户”A“是华南地区的负责人,那如何做到用户”A“只能查看”华南“地区的数据?
我们以产品自带数据源northwind数据库下的“orders”为例:“orders” 存储的是各个区域、省份、城市的销售订单信息。
具体的操作步骤如下:
1、创建数据模型并在模型中增加 SQL查询 , 用户通过SQL查询控制权限:
- 如果权限比较简单,比如通过”用户所属组”可以直接匹配的,可直接用 函数 进行控制;上图的CurrentUserDefaultDepartmentAlias就是用户所属组与区域匹配上了,所以可以控制权限。
- 如果权限控制比较复杂,比如用户存储在另外一个业务库,需要通过SQL语句进行再处理的,可使用 用户属性。
2、保存并回到模型,查看最终效果(预览模型):如需要把该参数在报表层应用,可以参考:参数设置进行映射。
2.3 通过SQL实现数据加工、多表关联等生成宽表
有时候IT技术人员是直接通过SQL处理、加工好对应的指标,然后让业务人员直接基于处理好的指标进行报表展现,并且查询全部数据,这时候也可以使用模型里面的SQL查询。
我们以查看“产品销售额”为例来进行说明。
1、创建数据模型 并在模型中增加 SQL查询
2、以产品自带northwind数据库下的”product“、“orderdetails” 为例编写SQL语句如下图:
- 可以在SQL语句中多表关联、过滤、使用数据库本身的函数进行计算、字符串替换、拼接、case when等等。
3、保存 之后再回到 回到模型,以查询名称命名生成了一个宽表,选中 查询 通过 右键菜单 可以设置与其他查询的关系或者参考构建数据模型构建自己的模型。
2.4 通过SQL进行union
前置条件
如果想复现示例,需要先把示例数据导入到模型中,详细请参考:导入文件数据。
示例数据下载:合同示例数据.rar。
某软件公司北京、广州、深圳的合同数据分别存在三张表中,老板想看三个城市的报表,业务用户希望能把他们进行合并。
目前可以通过数据模型的SQL查询:写SQL语句union2个或多个不同的表。
使用 union 将数据合并到一起,如下图:
- 合并前是各个查询单独查询数据,合并之后,3张表的数据全部合成一张表;查看总数,已经累加了三张表的数据。
- union:用于合并俩个或多个SELECT语句的结果集,并且消去表中任何重复行,纵向追加数据。
- 也可以使用union all,union all 与union的区别是:union all 不会消除表中重复行。
- 保存 之后再回到 回到模型 ,可以设置与其他查询的关系或者参考构建数据模型构建自己的模型。
其他说明:
MongoDB数据源为NOSQL数据库,仅支持抽取模式下数据模型的SQL查询
数据集处理需通过antlr等第三方工具包统一解析sql语句的语法树,因为mongo不是使用sql语法,目前产品只能解析处理部分常用的MongoDB查询指令,其他指令需要在find之前前面加上return ,通过eval指令执行runCommand脚本函数支持。
使用时需注意如下:
1)目前直接支持的指令关键字有:(即find命令如果只使用了下面关键字不需要在前面加return )
常规指令:
find、getCollection、limit、sort、projection、skip、toArray等;
查询条件:
$gt、$gte、$lt、$lte、$eq、$neq、$in、$nin、$and、$or、$nor、$not、$regex等;
正则表达式部分字符(如字符^)与expression.antlr冲突,find查询支持直接使用正则表达式和使用new RegExp对象,但是不能包含冲突字符。如果是比较复杂的正则表达式建议添加return使用脚本查询。
2)目前支持的数据类型
数值、字符、布尔、日期、正则、内嵌文档、常规数组;
产品只支持MongoDB规整结构的数据结构,即要求返回每行的数据结构是一样,每行结构不一样只解析第一行的数据结果可能会存在数据缺失。
3)非单行指令,如需要设定变量等操作,都需要添加return使用脚本查询;
4)]}、{[等特殊字符的组合antlr第三方工具包无法正常解析,需要通过在中括号和大括号之间加了换行规避处理;
如直接执行db.test.find({"name":{$in:["ttt"]}}),会报错:

添加换行后即正常:
db.test.find(
{"name":{
$in:["ttt"]
}}).toArray()
5)如果MongoDB开通了auth认证鉴权,使用return关键字执行脚本查询,MongoDB业务库配置的用户需要开通执行eval指令的权限,如有anyAction或anyResource的权限,如果没有执行eval指令的权限会提示报错,如下图所示

开通权限命令:
db.createRole({role:"executeFunctions",privileges:[{resource:
{anyResource:true},
actions:["anyAction"]}],roles:[]})
db.grantRolesToUser("yourusername", [
{ role: "executeFunctions", db: "admin" }
])


