具体改进点如下:
新增 | 增强 |
|---|---|
+【数据挖掘】文本分析新增LSH、相似集计算(LSH)节点【数据挖掘】支持异常检测使用场景功能(CBLOF) +【数据挖掘】支持导出PMML模型文件【数据挖掘】支持异常检测使用场景功能(孤立森林) +【数据挖掘】朴素贝叶斯、决策树、多层感知机等算法支持自动调参设置【数据挖掘】增强特征工程(WOE)模型保存 +【数据挖掘】新增ETL和挖掘实验日志 |
+【数据挖掘】文本分析新增LSH、相似集计算(LSH)节点
背景介绍
我们面对和需要处理的数据往往是海量并且具有很高的维度,怎样快速地从海量的高维数据集合中找到与某个数据最相似的一个数据或多个数据成为了一个难点和问题。如果是对一个海量的高维数据集采用线性查找匹配的话,会非常耗时,因此,为了解决该问题,我们可以使用LSH算法这类索引的技术来加快查找过程。
功能简介
新版本,文本分析中新增LSH、相似集计算(LSH)节点,支持计算大规模数据的相似度。
参考文档
详情请参考 数据挖掘 – LSH、数据挖掘 – 相似集计算(LSH) 。
+【数据挖掘】支持导入和导出PMML模型文件
背景介绍
以前的版本,用户往往需要一次建立多个数据挖掘模型, 想要通过导出PMML文件快速进行跨平台的应用和部署。为了满足用户需求,新版本产品支持将训练得到的模型转化为PMML模型文件,用户可将PMML模型文件载入Python或其他平台中进行预测,适应更多环境;同时也支持上传其他服务器导出的模型文件,大大节省了等待时间。
功能简介
1、导入PMML模型文件:在模型管理页面中,新增“上传模型”按钮,支持上传其他服务器模型导出模型文件,并生成对应的模型记录。
2、导出PMML模型文件:已训练的模型右键更多中和模型管理页面的常用操作中,新增“导出PMML模型”功能,支持导出选中模型的PMML模型文件。
参考文档
关于导入和导出PMML模型文件,详情请参考 模型管理 。
^【数据挖掘】异常值处理节点新增删除异常行功能
背景介绍
在实际应用中,用于分析的数据常常会存在大量的异常值,影响正常的分析结果。新版本,在产品异常值处理节点新增删除异常行处理策略,可用于直接删除一些异常值存在的行,提高数据质量。
功能简介
1、异常值处理节点的配置界面,新增“删除异常行”处理策略,可用于直接删除一些异常值存在的行,为生成训练集做准备。
2、全表统计节点新增“显示异常值”选项。
支持在输出结果的箱线图中显示异常值。
参考文档
详情请参考 数据挖掘-异常值处理 、数据挖掘-全表统计 。
+【数据挖掘】朴素贝叶斯、决策树、多层感知机等算法支持自动调参设置
背景介绍
在实际应用中,用户在进行机器学习时需要对选择的模型进行调参,从而得到最优参数进行匹配,而手动调参往往需要耗费大量时间和人力,可以采取系统自动调参的方式解决问题。此前产品部分机器学习算法已实现了自动调参设置,新版本产品更多的算法支持自动调参设置,帮助用户节约时间和人力,提升数据分析效率。
功能简介
新版本,朴素贝叶斯、决策树、多层感知机、随机森林、梯度提升回归树算法支持自动调参设置,系统可对设置指定或范围内的参数值循环调参,匹配出最优的组合。
参考文档
详情请参考 数据挖掘-朴素贝叶斯、数据挖掘-决策树、数据挖掘-多层感知机、数据挖掘-随机森林、数据挖掘-梯度提升回归树 。
+【数据挖掘】新增ETL和挖掘实验日志
背景介绍
在实际应用中,用户使用数据模型的高级ETL查询时,进行某次数据抽取失败,右上角只显示“初始化”等运行状态,因此想要查看更加详细的运行状态信息,便于及时排查、定位问题。为了满足用户需求,新版本在高级ETL查询、自助ETL、数据挖掘中,新增ETL和挖掘实验日志功能,用于记录ETL和挖掘实验运行状态信息。
功能简介
新版本,在高级ETL、自助ETL、数据挖掘中新增“查看日志”功能,用于记录ETL和挖掘实验运行状态信息。
参考文档
详情请参考 ETL高级查询-界面介绍、自助ETL-界面介绍、 数据挖掘-实验界面介绍 。
+【自助ETL/数据挖掘/ETL高级查询】数据源新增FTP数据源
功能简介
新版本,在自助ETL、数据挖掘、数据模型的ETL高级查询中,数据源新增FTP数据源,支持通过FTP方式读取Excel、CSV文件数据。
参考文档
关于FTP数据源设置说明,详情请参考 数据挖掘-数据的输入和输出 。
^【数据挖掘】关系目标表支持GaussDB 200数据库
功能简介
新版本,关系目标表(追加)、关系目标表(覆盖)、关系目标表(插入或更新)支持GaussDB 200数据库。
^【自助ETL/数据挖掘】关系数据源节点兼容更多数据源
功能简介
新版本,关系数据源节点兼容更多数据源,包括:Kingbase、Kingbase_V8、Kingbase AnalyticsDB 、GaussDB 200、Teradata、Teradata_V12、神通、Obase、Informix、Kylin、Impala。
注意事项
其中, 关系数据源 KingbaseAnalytics、ShenTong集群暂不支持小批量运行。锚 支持异常检测使用场景功能 支持异常检测使用场景功能
+【数据挖掘】支持异常检测使用场景功能(CBLOF)
背景介绍
异常检测广泛应用在需要发现离群点的场景中如:欺诈检测、入侵检测等,在数据挖掘中属于经典的场景之一,因此将部分较为经典的异常检测算法通过spark进行分布式实现。
功能简介
CBLOF(Cluster-Based Local Outlier Factor,基于聚类的本地异常因子)是一个异常检测节点,原理是先用聚类算法把为数据分为K个簇,而后通过设定占比阈值和突降倍数阈值,把簇区分为大簇和小簇,聚类完成后,计算每个点到最邻近大簇的距离(邻近距离),邻近距离越大的数据点为异常数据的概率越大。
CBLOF算法适用于当没有已知正常的数据时,对所有输入的新数据进行异常值的辨别。

参考文档
详情请参考 数据挖掘 - CBLOF
锚 支持异常检测使用场景功能(孤立森林) 支持异常检测使用场景功能(孤立森林)
+【数据挖掘】支持异常检测使用场景功能(孤立森林)
背景介绍
异常检测广泛应用在需要发现离群点的场景中如:欺诈检测、入侵检测等,在数据挖掘中属于经典的场景之一,因此将部分较为经典的异常检测算法通过spark进行分布式实现。
功能简介
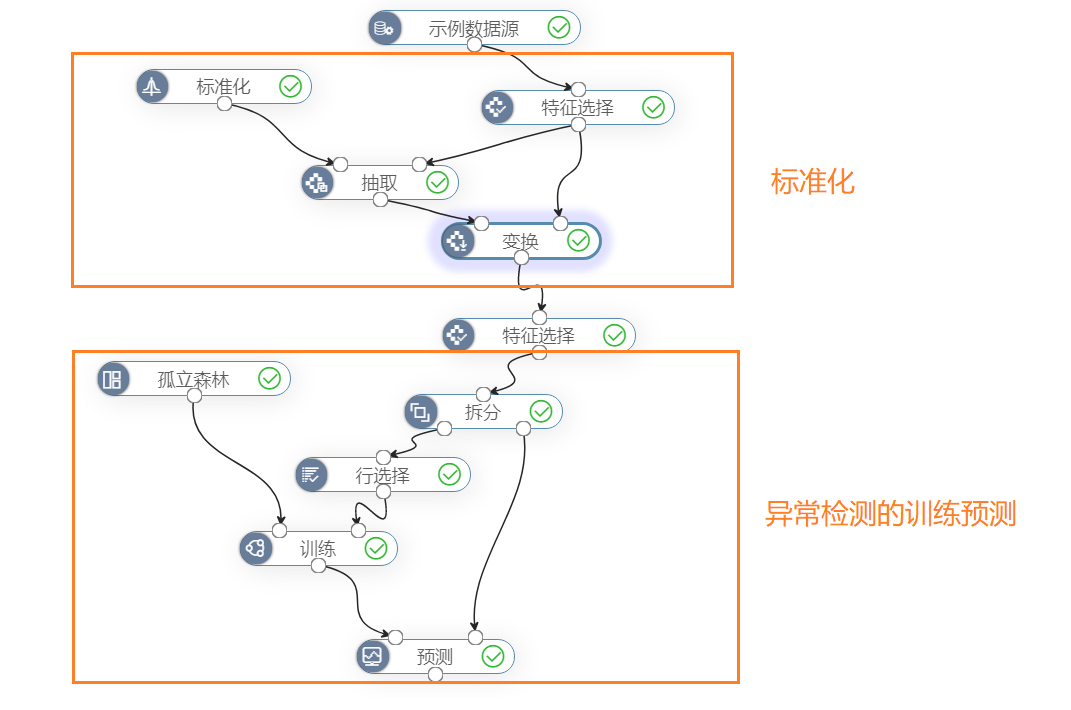
孤立森林是一个异常检测算法节点,需要配合特征选择、训练、预测节点使用(异常检测算法为无监督学习,不需要评估节点)。孤立森林对正常数据进行采样,训练时随机生成决策树对数据进行划分。在预测未知数据时,决策树划分出某单个数据点需要的划分次数越少,对应的异常分数越高,该数据点为异常数据的概率越大。
孤立森林适用于用已知为正常的数据作为训练数据,然后对未知的新数据作预测,检测新数据中的异常数据。
参考文档
详情请参考 数据挖掘 - 孤立森林。
锚 增强特征工程(WOE)模型保存 增强特征工程(WOE)模型保存
+【数据挖掘】增强特征工程(WOE)模型保存
背景介绍
旧的特征工程功能没有保存模型机制,导致用户需要手工记住参数来进行模型发布,因此新增支持类似WOE特征工程模型的保存机制。
功能简介
WOE编码节点和评分卡构建节点现在支持保存模型,保存的模型可以展示模型参数,以及再次使用进行预测。
新增了数据预测节点用于对特征工程模型(WOE编码模型、评分卡模型)进行预测,可以配合这些模型的保存功能,把已保存的模型接入数据预测节点对新数据进行预测。
参考文档
详情请参考 数据挖掘 - 数据预测。
锚 支持自定义调整节点目录结构 支持自定义调整节点目录结构
+【数据挖掘】支持自定义调整节点目录结构
背景介绍
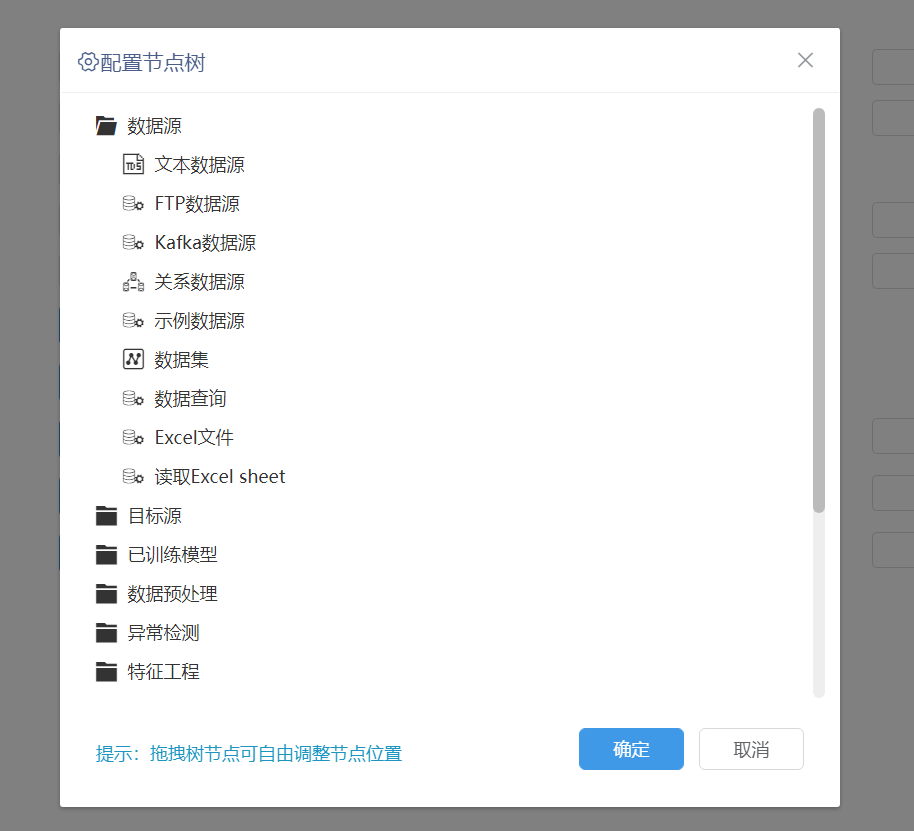
用户有时候想要调整挖掘实验里左侧节点树的目录结构。同时挖掘能够上传自定义节点,但是无法修改目录结构,导致上传的新节点有时候无法正确归类,因此需要能够支持自定义目录结构功能。
功能简介
用户可以根据需要以拖拽的方式调整节点目录中的文件夹顺序、节点顺序、节点归类等。上传的自定义节点也能在目录结构中调整。支持新建目录。
参考文档
详情请参考 数据挖掘 - 自定义节点目录结构。
锚 关联规则和聚类支持模型自学习 关联规则和聚类支持模型自学习
^【数据挖掘】关联规则和聚类支持模型自学习
背景介绍
旧的模型自学习功能只支持分类算法的自学习任务,无法作用于聚类算法和关联规则算法,因此模型自学习需要支持关联规则和聚类任务。
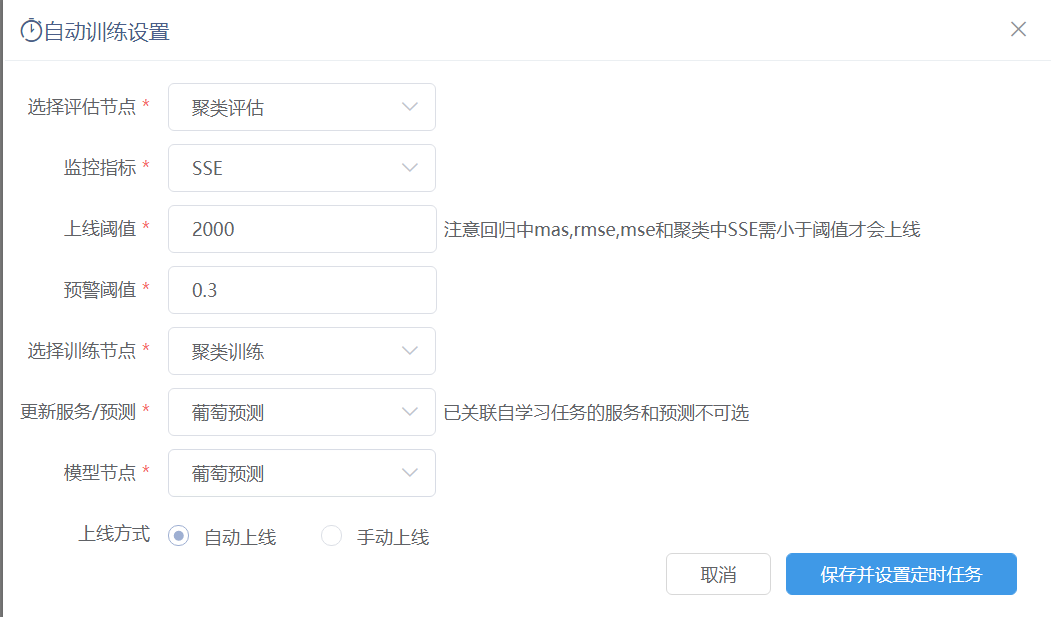
功能简介
可以在聚类任务和关联规则任务实验中进行模型自学习的设置,关联到对应的聚类模型和关联规则模型,实现对该模型的自动更新。
参考文档
详情请参考 数据挖掘 - 模型自学习和模型批量预测使用示例。
锚 评估报告重构 评估报告重构
^【数据挖掘】评估报告重构
背景介绍
旧的评估报告的功能通过电子表格的方式展现,重构后通过仪表盘的方式展现。
功能简介
通过在数据模型中建有若干个Java查询,用于获取挖掘实验中的评估节点中的数据,获取的结果输出到仪表盘,并最终能够通过仪表盘进行数据展现。
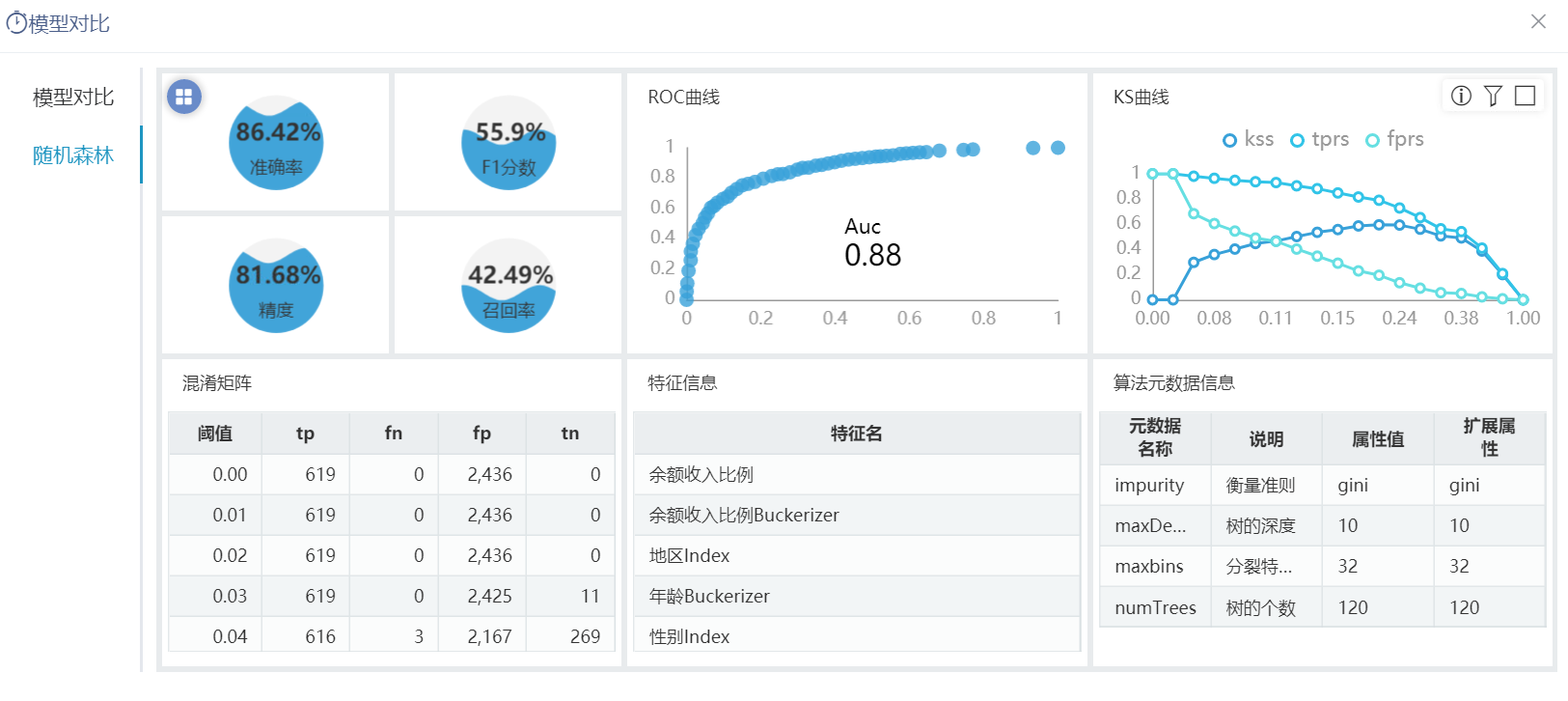
参考文档
详情请参考 数据挖掘 - 模型对比。
锚 指标模型维度和事实表新建自助ETL时,自动添加目标数据源节点 指标模型维度和事实表新建自助ETL时,自动添加目标数据源节点
^【ETL】指标模型维度和事实表新建自助ETL时,自动添加目标数据源节点
背景介绍
指标模型基于维度和事实表新建自助ETL时,自动添加目标数据源节点,并填写好相关参数。
功能简介
指标模型基于维度和事实表新建自助ETL时,会在新建的ETL中自动添加关系目标表(覆盖)节点,并自动填写数据库、Schema、表名的信息。